
Beautiful Soup(ビューティフル・スープ)とは、HTMLやXMLファイルからデータを取得し、解析するPythonのWEBスクレイピング用のライブラリです。インターネット上に公開されているWEBサイトでは広くHTMLやXMLが使われており、これらの情報の取得や解析に、大変便利なライブラリです。
Pythonでは、Beautiful Soupを利用して、簡単にWEBサイトからデータを自動的に取得することができます。
Beautiful Soupは、
- 情報収集の為にニュースサイトやブログから、自動的にデータを取得し保存したい。
- 製品の価格情報を取得して、トレンドを把握し価格設定に利用したい。
- WEBサイトから統計情報や他社のIR情報を取得し、競合分析、マーケットリサーチに活用したい。
という場合に利用すると便利です。
この記事ではチュートリアル形式で、Python3におけるBeautiful Soupの基本的な使い方を解説していきます。
- PythonのWEBスクレイピング用ライブラリとその違い(Selenium、BeautifulSoup、Requests)
- BeautifulSoup4と関連ライブラリのインストール
- BeautifulSoupの前に必要なRequestsを使ったデータの取得方法
- BeautifulSoupの基礎的な使い方
- selectメソッドの基本的な使い方(CSSセレクタによる抽出)
- find、find_allメソッドの基本的な使い方(HTMLタグによる抽出)
- 階層化されたサイトをクローリングする方法(複数ページを移動・遷移しテキストを取得)
- HTMLの階層を移動してタグを指定する方法
- find_allメソッドの使い方の詳細解説
- findメソッドの使い方の詳細解説
- selectメソッドの使い方の詳細解説
- Seleniumと連携し画像ファイルをダウンロード・保存する方法
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
PythonのWEBスクレイピング用ライブラリとその違い(Selenium、BeautifulSoup、Requests)
WEBスクレイピングの手順
まずはスクレイピングの手順を確認した上で、その中で各ライブラリの役割の違いについて見ていきましょう。
スクレイピングは、次の3ステップで行われます。
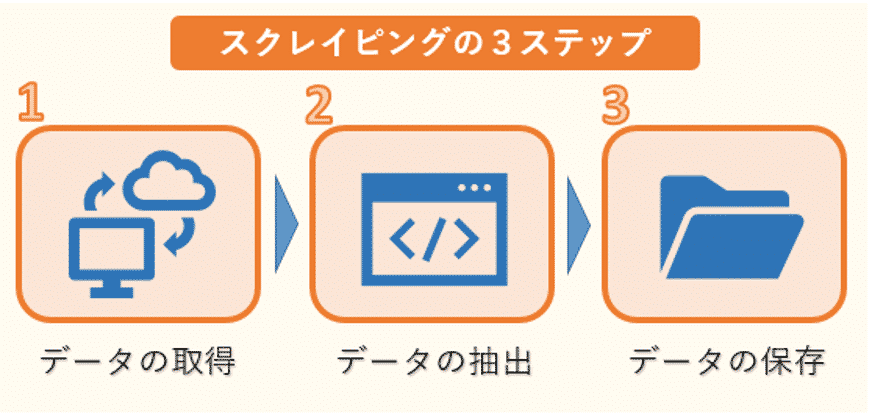
1つ目はWEBサイトのHTMLなどのデータ取得です。ただし、HTMLには必要な文章のデータだけでなく、タグなどのデータも混じっているので、必要なものだけを抽出する作業が必要になります。
そこで2つ目のデータの抽出が欠かせません。ここでは、複雑な構造のHTMLデータを解析し、必要な情報だけを抽出します。
そして最後に抽出した情報をデータベースやファイルなどに保存します。
WEBスクレイピングに利用する各ライブラリの役割
Pythonのスクレイピングによく使われるライブラリとしては、Requests、Beautiful Soup、Seleniumがあります。
先ほどのWEBスクレイピングの3ステップの中で、それぞれのライブラリがどこで使われるのかをまとめると次のようになります。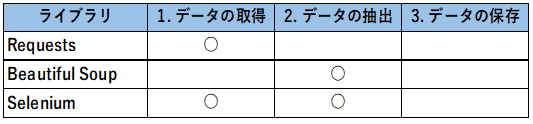
Requestsは1つ目のHTMLデータの取得によく用いられます。PythonではRequestsを利用して、簡単にWEBサイトからデータを自動的に取得することができます。
その後、取得したデータからBeautiful Soupなどのライブラリを用いて必要な情報のみを抽出します。
そしてSeleniumは、JavaScriptが使われているサイトからのデータの取得や、サイトへのログインなどに使います。
Seleniumは、データ取得だけでなく、データの抽出も行うことができますが、ブラウザを操作してデータを取得しますので、動作が遅いことが難点です。
従って、できるだけRequestsやBeautiful Soupを使い、Seleniumは必要最低限の箇所で使うことをお勧めします。この記事ではBeautiful Soupの基本的な使い方を解説していきます。
またBeautifulSoup、Selenium、Requestsについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
BeautifulSoup4と関連ライブラリのインストール
Beautiful Soupは、標準ではインストールされていませんので、pipやcondaを利用して別途インストールする必要があります。最新のバージョンはBeautiful Soup4になります。
pipを利用してインストールする場合は、以下のコマンドを入力してください。
pipの詳しい説明は「Pythonでの外部ライブラリの追加インストール方法」を参照ください。
またcondaを利用してインストールする場合は、次のコマンドを入力してください。
condaの詳しい説明は「Anacondaでの外部ライブラリの追加インストール方法」を参照ください。
またBeautiful Soup自体はHTMLファイルやXMLファイルを解析するライブラリで、ファイルデータのダウンロードは行いません。
Beautiful Soupでファイルを解析するには、ファイルデータをダウンロードする必要がありますので、必要なライブラリrequestsもインストールします。requestsの詳しい説明は、「図解!PythonのRequestsを徹底解説!」を参照ください。
requests をpipでインストールする場合は、次のコマンドを入力してください。
またcondaでインストールする場合は、次のコマンドを入力してください。
これでインストールは終わりました。次に、これらのライブラリを利用する前にはインポートしておく必要があります。
1 2 | import requests from bs4 import BeautifulSoup |
以上で、Beautiful Soupを使うための準備は終わりです。
BeautifulSoupの前に必要なRequestsを使ったデータの取得方法
これからBeautiful Soupの基本となる使い方を紹介していきます。ここはでは、読売新聞オンライン(https://www.yomiuri.co.jp/) から記事を取得してみます。
まず今回は、メインページのトップニュースのタイトル(赤線で囲った箇所)とそのURLを取得したいと思います。
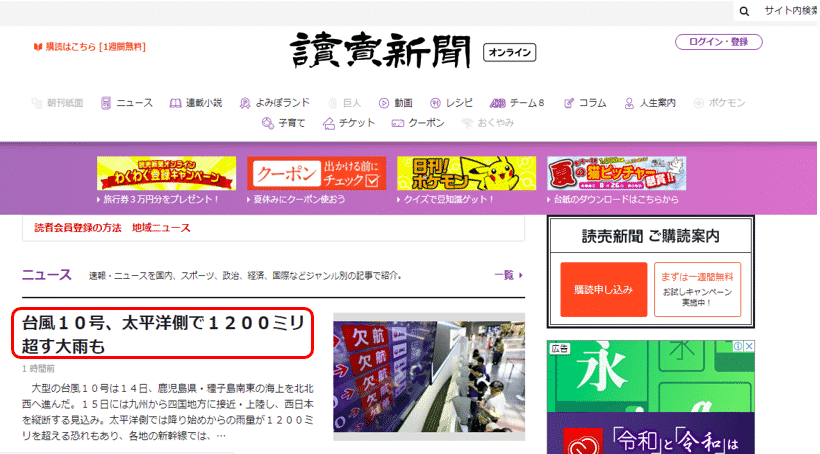
まずはrequestsを利用して、WEBサイトの情報をダウンロードします。requestsの詳しい説明は、「図解!PythonのRequestsを徹底解説!」を参照ください。
変数urlを定義し、確認したいWEBサイトのアドレスを渡します。次に、requests.get()に対してurlを渡しています。request.get()で指定されたwebの情報を取得し、その結果は、変数resに格納します。
1 2 | url = 'https://www.yomiuri.co.jp' res = requests.get(url) |
試しに取得した内容を表示してみましょう。textで内容を確認することができます。
1 | res.text |

WEBサイトの大量の情報が取り込まれています。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
BeautifulSoupの基礎的な使い方
次に、この情報の中からトップニュースのタイトルとURLを取り出してみましょう。そのためには、BeautifulSoup()を用いて、ダウンロードした情報の解析が必要になります。
BeautifulSoup()の記述方法は以下です。
1つ目の引数には、解析対象のHTML/XMLを渡します。
2つ目の引数として解析に利用するパーサー(解析器)を指定します。
| パーサー | 引数での指定方法 | 特徴 |
| Python’s html.parser | “html.parser” | 追加ライブラリが不要 |
| lxml’s HTML parser | “lxml” | 高速に処理可 |
| lxml’s XML parser | “xml” | XMLに対応し、高速に処理可 |
| html5lib | “html5lib” | 正しくHTML5を処理可 |
この中でも、今回はPythonの標準ライブラリに入っており、追加でライブラリのインストールが不要なPython’s html.parserを利用します。
参考までにパーサーとしてlxmlを使う場合、pipやcondaを利用して別途インストールする必要があります。
pipを利用してインストールする場合は、以下のコマンドを入力してください。
またcondaを利用してライブラリをインストールする場合は、次のコマンドを入力してください。
BeautifulSoup()に先ほど取得したWEBサイトの情報とパーサー"html.parser"を渡してあげます。
1 | soup = BeautifulSoup(res.text, "html.parser") |
これらの情報を用いてBeautiful SoupではHTMLを解析していきますが、必要な箇所を解析するために、該当箇所を指定、検索する方法がいくつかあります。
- 1つ目は、selectメソッドにより、CSSセレクタで該当する箇所を指定する方法です。
- 2つ目は、find、find_allメソッドにより、HTMLタグの該当する箇所を検索する方法です。
- 3つ目は、HTMLの階層を移動して、HTMLタグの該当する箇所を検索する方法です。
これらの方法を順番に解説していきます。ここではまず、1つ目のselectメソッドによりCSSセレクタで指定する方法を確認していきましょう。
selectメソッドの基本的な使い方(CSSセレクタによる抽出)
ということで、次に、WEBサイトの取得したい箇所を指定して情報を抽出していきます。
そのためには、WEBサイトから該当箇所を示すCSSセレクタという情報(住所のようなもの)を取り出します。CSSセレクタは、HTMLから処理対象とする要素を選択するのに利用します。
CSSセレクタを調べるためには、WEBブラウザとしてGoogle Chromeを使うと非常に便利です。インストールされておられない場合は、インストールをお勧めします。
Google Chromeのインストールは、こちらのリンクをご参照ください。
https://support.google.com/chrome/answer/95346?co=GENIE.Platform%3DDesktop&hl=ja
Google Chromeの準備が整いましたら、Google Chromeで読売新聞オンラインのページを開きます。メインページのトップニュースのタイトルにマウスのカーソルを当て、右クリックします。するとメニューが表示されますので、その中から「検証」を選択します。
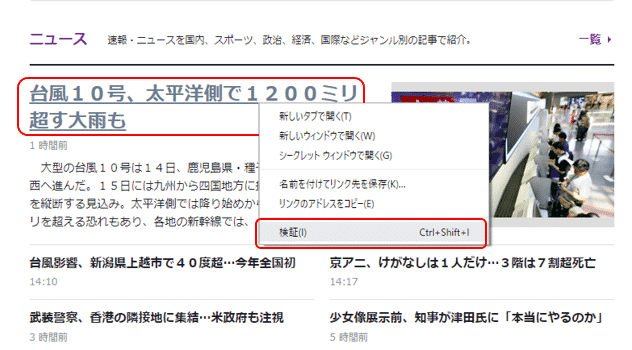
すると、右側にウィンドウが現れ、HTMLが表示されます。先ほどのトップニュースのタイトルに該当する箇所にカーソルが当たった状態で、右クリックします。またメニューが表示されますので、Copy → Copy selectorを選択します。
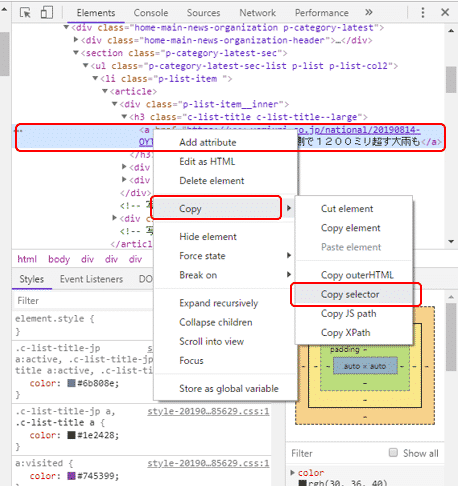
このようにしてコピーしたCSSセレクタをメモ帳に貼り付けます。すると次のようなCSSセレクタが表示されます。これがトップニュースに該当する箇所のCSSセレクタになります。
これを用いて、Beautiful Soupで解析を進めていきますが、1つサポートされていないCSSセレクタ、nth-childがあります(該当箇所の背景色を変えています)。nth-childをnth-of-typeに変更する必要があります。
変更後
このようにして取得したCSSセレクタをsoup.select()に渡します。戻り値は、変数elemsに格納します。
1 | elems = soup.select('body > div.layout-contents > div.layout-contents__main > div > div.home-main-news-organization.p-category-latest > section > ul > li:nth-of-type(1) > article > div.p-list-item__inner > h3 > a') |
ここまでがWEBサイトから指定した箇所の情報を単純に取得する一連の処理になります。
これらの取得した情報を表示してみましょう。変数elemsの最初の要素を表示してみます。
1 | elems[0] |
指定したトップニュースのタイトルやリンクが表示されました。但し、HTMLのタグが混在しており、見やすい状態とは言えません。
次にcontentsを利用して内容を表示してみます。contenstの詳細はこちらを参照ください。
1 | elems[0].contents[0] |
トップニュースのタイトルだけを取り出すことができました。
今度はリンクのURLだけを取得したいと思います。リンクが含まれているaタグのhref属性の内容だけを抽出するattrs['href']を利用します。タグの属性値の確認方法はこちらを参照ください。
1 | elems[0].attrs['href'] |
このようにselectメソッドでCSSセレクタを利用して、指定したトップニュースのタイトルやリンクを取得することができました。
selectメソッドの使い方の詳細については、この記事の後の章で解説いたします。
>> select()の詳細解説へのリンク
find、find_allメソッドの基本的な使い方(HTMLタグによる抽出)
前回はCSSセレクタを利用して情報を抽出しましたが、次は、HTMLタグで該当する箇所を検索する方法を試してみましょう。
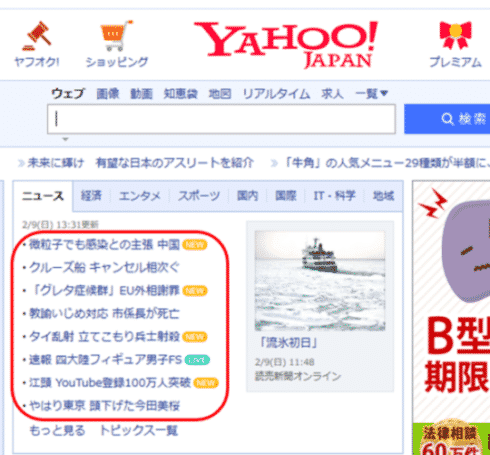
ここはでは、yahoo(https://www.yahoo.co.jp/) から記事を取得してみます。今回は、メインページのトップニュースから、タイトル(赤線で囲った箇所)とそのURLの組み合わせの一覧を取得したいと思います。
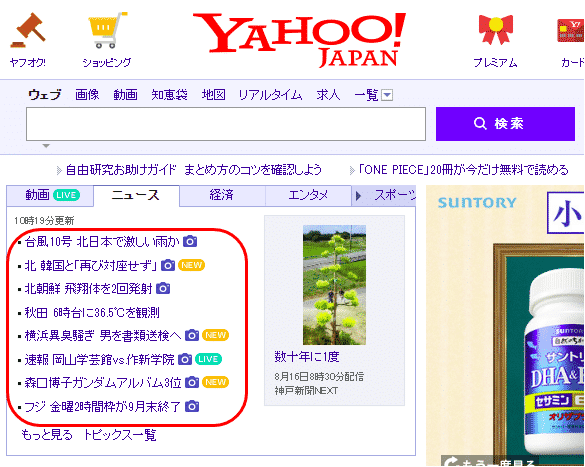
前回同様、requestsを利用して、WEBサイトの情報をダウンロードします。変数urlを定義し、確認したいWEBサイトのアドレスを渡します。次に、requests.get()に対してurlを渡しています。request.get()で指定されたwebの情報を取得し、その結果は、変数resに格納します。
1 2 | url = 'https://www.yahoo.co.jp/' res = requests.get(url) |
BeautifulSoup()に先ほど取得したWEBサイトの情報とパーサー"html.parser"を渡してあげます。
1 | soup = BeautifulSoup(res.text, "html.parser") |
これらの情報を用いてBeautiful SoupではHTMLを解析していきますが、該当箇所を指定、検索する方法の中で、今回は、HTMLタグで該当する箇所を検索する方法を利用します。
Beautiful Soupでは、HTMLタグで該当する箇所を検索するメソッドには次のようなものがあります。
| メソッド | 引数 | 説明 |
| find() | 検索するHTMLタグ | 引数に一致する 最初の1つの 要素を取得します。 |
| find_all() | 検索するHTMLタグ | 引数に一致する 全ての 要素を取得します。 |
各メソッドの使い方の詳細については、この記事の後の章で解説いたします。
>> find_all()の詳細解説へのリンク
>> find()の詳細解説へのリンク
ここではまず使い方の概要を理解しましょう。
最初に該当する箇所のHTMLタグを確認します。ブラウザでyahooのページを開きます。(ここでは、Google Chromeの例を載せていますが、他のブラウザでも確認できます。)
メインページのトップニュースのタイトルにマウスのカーソルを当て、右クリックします。するとメニューが表示されますので、その中から「検証」を選択します。
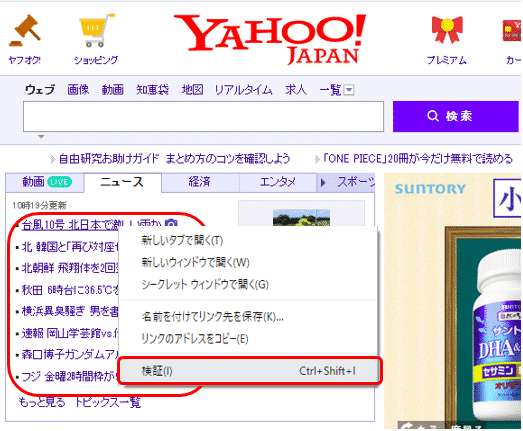
すると、右側にウィンドウが現れ、HTMLが表示されます。先ほどのトップページのニュースは、htmlのタグで<a href=”url”>…</a>のように記載されているようです。
タグ<a>は、リンクの開始点と終了点を指定するタグです。リンクの開始点ではhref属性でリンク先を指定しています。
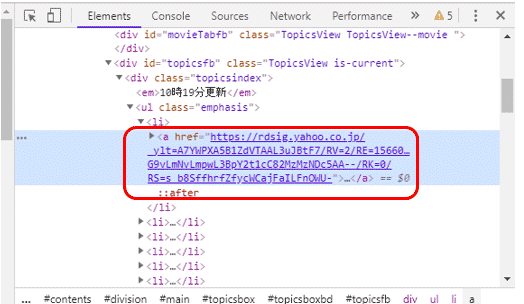
ここで先ほどのメソッドを試してみましょう。まずはfind()に引数”a”を渡すと、
1 2 | elems = soup.find("a") elems |
タグ<a>が含まれる内容が表示されましたが、欲しい情報ではないようです。find()では、引数で渡されたタグで検索してヒットした、最初の1つの 要素を取得しますので、その内容が表示されているようです。
次に、find_all()に引数"a"を渡して、検索してみます。
1 2 | elems = soup.find_all("a") elems |

今度は、タグ<a>が含まれる全ての要素が表示されました。ここから必要な情報だけに絞り込む必要があるようです。
どのようにして絞り込めば良いのでしょうか?先ほど表示された内容をよく見てみると、トップニュースに該当する箇所は全て、URLに"news.yahoo.co.jp/pickup"が含まれているようです。これが利用できそうです。

ということで、URLに”news.yahoo.co.jp/pickup”が含まれているという条件でさらに絞り込んでいきましょう。
ここで文字列のパターンで検索できるモジュールreをインポートします。モジュールreの詳しい説明は、「図解!Python 正規表現の徹底解説!」を参照ください。
1 | import re |
ライブラリreのcompile()を利用して、href=re.compile("news.yahoo.co.jp/pickup") をfind_all()の引数として渡します。
ここでは、href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出しています。そして抽出した結果を表示すると、
1 2 | elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup")) elems |

表示したいトップニュースの箇所に絞り込んで情報を表示することができました。
後は、ここからURLとタイトルを抽出して一覧表示するだけです。ここからは前回学習した内容を活かすことができそうです。
まずは1つ目のニュースのタイトルを表示してみます。contentsを使えばよかったですね。
1 | elems[0].contents[0] |
トップニュースの1つ目のタイトルだけを取り出すことができました。
今度はリンクのURLだけを取得したいと思います。リンクが含まれているタグhrefの内容だけを抽出するattrs['href']を利用します。
1 | elems[0].attrs['href'] |
同様に、2つ目のニュースも取得してみましょう。リストelemsの2つ目の要素を表示するよう、elems[0]からelems[1]に変更します。
1 | elems[1].contents[0] |
2つ目のニュースのURLも同様に、elems[0]からelems[1]に変更すると表示されました。
1 | elems[1].attrs['href'] |
このようにしてリストelemsに格納されている全ての要素のcontensとhref属性を取得すれば、タイトルとURLの一覧を表示することができます。全ての要素の表示はfor文を使って次のように書きます。
1 2 3 | for elem in elems: print(elem.contents[0]) print(elem.attrs['href']) |

このようにして、yahooのトップページからニュースのタイトルとURLの一覧を取得することができました。
階層化されたサイトをクローリングする方法(複数ページを移動・遷移しテキストを取得)
前回はyahoo(https://www.yahoo.co.jp/) のメインページのトップニュースから、タイトル(赤線で囲った箇所)とそのURLの組み合わせの一覧を取得しました。
今回はそのリンクをたどって、それぞれのニュースの詳細な情報も取得してみましょう。
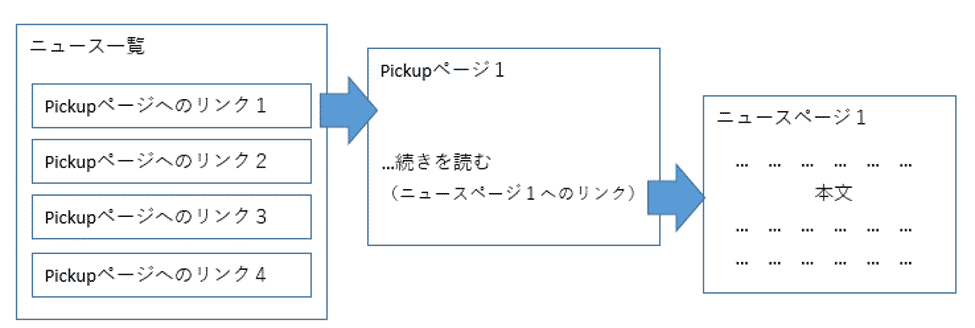
Yahooのサイトは階層化されていて、最終的にニュースの情報を取得するには複数のページを移動していく必要があります。
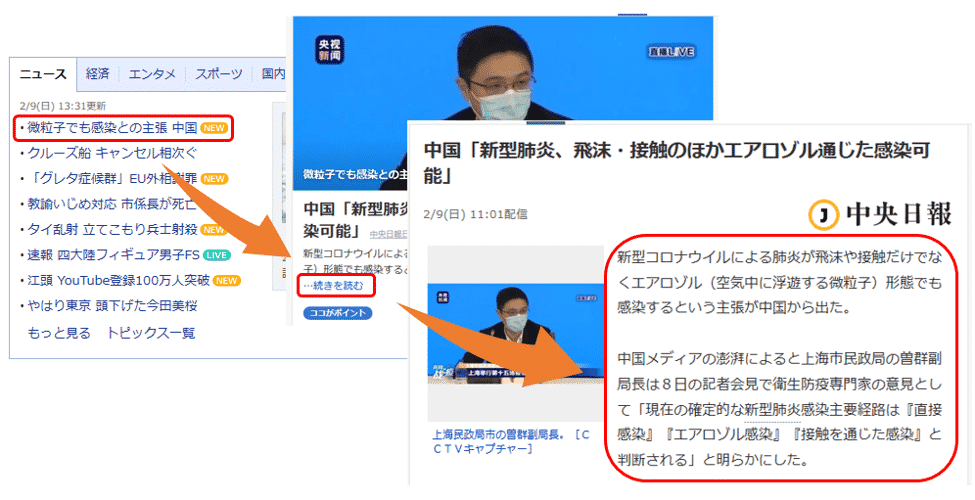
まずは主要ニュースの一覧が表示されていて、そのリンクをクリックすると、Pickupニュース用の要約が表示されたページに遷移します。
そして、「…続きを読む」のリンクを押すと、ニュースの詳細が書かれたページに遷移します。
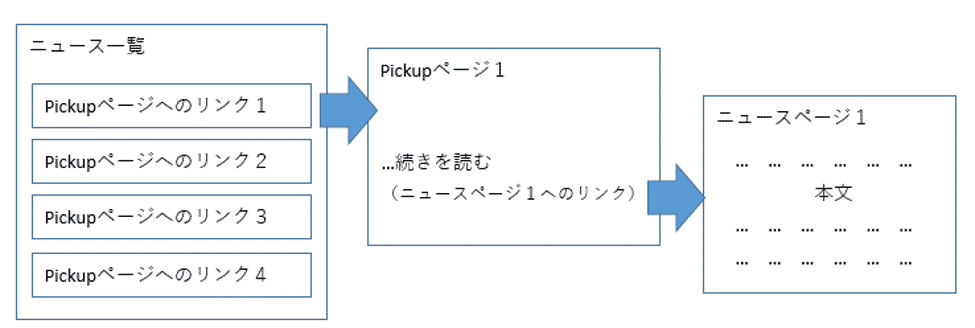
この一連のページ遷移を、一覧に表示されている主要ニュースの数だけ繰り返すことにより、全てのニュースの詳細な情報を取得することができます。
それでは実際にコーディングを進めていきます。
前回、記述したコードは次のものでした。今回は、この続きから始めます。
1 2 3 4 5 6 7 8 9 10 11 12 | import requests from bs4 import BeautifulSoup import re url = "https://www.yahoo.co.jp/" res = requests.get(url) soup = BeautifulSoup(res.text, "html.parser") elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup")) for elem in elems: print(elem.contents[0]) print(elem.attrs['href']) |
最初に主要ニュースの一覧からPickupページへのリンクを取得します。
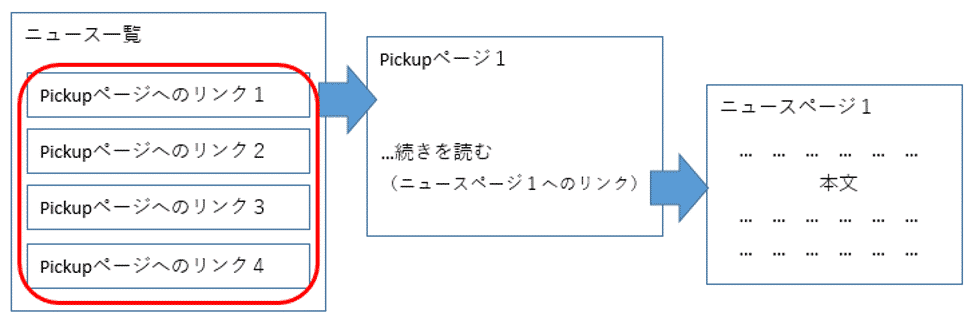
またこのリンクは、後から1つずつ取り出して処理しやすいよう、リスト型にして変数に入れておきたいと思います。
ということで、前回記述した一覧からタイトルとリンクを取得・表示したコードを変更します。
print(elem.contents[0])
print(elem.attrs['href'])
リンクを取得するコードを利用して [ ] で括り、リスト内包表記という記述方法で取得したリンクの一覧をリスト型にします。
そして、そのリストの内容を変数pickup_linksに格納します。
格納した内容をprint()で表示してみましょう。
1 2 | pickup_links = [elem.attrs['href'] for elem in elems] print(pickup_links) |
主要ニュースの一覧から取得したPickupページのURLがリストで格納されていることがわかります。
次にそれぞれのURLを元に、Pickupページ、ニュースページへと階層をクローリングして、ニュースページの情報を取得しましょう。
ニュースページからテキスト情報を取得・表示するコードは、次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #一覧のリンクを順に処理 for pickup_link in pickup_links: #Pickupページへ遷移しページの情報を取得 pickup_res = requests.get(pickup_link) pickup_soup = BeautifulSoup(pickup_res.text, "html.parser") #ニュースページへのリンクを取得 pickup_elem = pickup_soup.find("p", class_="pickupMain_detailLink") news_link = pickup_elem.contents[0].attrs['href'] #ニュースページの情報を取得 news_res = requests.get(news_link) news_soup = BeautifulSoup(news_res.text, "html.parser") #タイトルとURLを表示 print(news_soup.title.text) print(news_link) #ニュースのテキスト情報を取得し表示 detail_text = news_soup.find(class_=re.compile("DetailText")) print(detail_text.text if hasattr(detail_text, "text") else '',end='\n\n\n\n') |
コードを詳しく解説していきます。
先ほどリストに格納したニュースのURLを、for文で1つずつ取り出しながら繰り返し処理を実行していきます。
for pickup_link in pickup_links:
1つのニュースのURLは、変数pickup_linkに格納され、以降の処理を実施します。
変数pickup_linkに格納されたURLを元に、requests.get()でPickupページの情報をダウンロードします。
pickup_res = requests.get(pickup_link)
pickup_soup = BeautifulSoup(pickup_res.text, "html.parser")
そして、BeautifulSoup()を使ってその内容の解析を始めます。
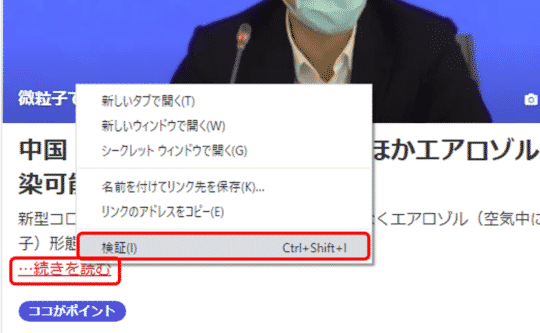
Pickupページからニュースページへ遷移するURLはどのようにして取得すれば良いでしょうか?前回と同様にChromeの検証で確認しましょう。
「…続きを読む」のリンクにマウスのカーソルを当て、右クリックします。するとメニューが表示されますので、その中から「検証」を選択します。
該当箇所のHTMLを確認すると、class属性”pickupMain_detailLink”を持つpタグの配下にaタグがあります。
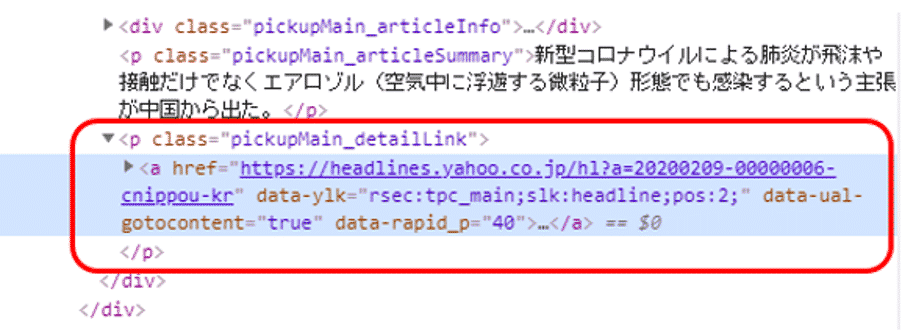
そして、そのaタグのhref属性にリンクが格納されているようです。
まずはfind()でclass属性”pickupMain_detailLink”を持つpタグを取得します。
pickup_elem = pickup_soup.find("p", class_="pickupMain_detailLink")
news_link = pickup_elem.contents[0].attrs['href']
次にpタグの最初の子要素をcontents[0]で取得し、そのhref属性を変数news_linkに格納します。
この取得したURLを元に、requests.get()でニュースページの情報をダウンロードします。
news_res = requests.get(news_link)
news_soup = BeautifulSoup(news_res.text, "html.parser")
そして、BeautifulSoup()で解析します。
これから取得したニュースページの情報を表示します。
まずはタイトルとURLを表示します。タイトルは通常、titleタグのtext属性に含まれます。
print(news_soup.title.text)
print(news_link)
そしていよいよニュースの内容を表示しますが、ここでもどのようにすれば取得できるでしょうか?ここでもChromeの検証で確認しましょう。
ニュースのテキストの箇所にカーソルを当て、右クリックでメニューを表示します。そして「検証」を選択します。
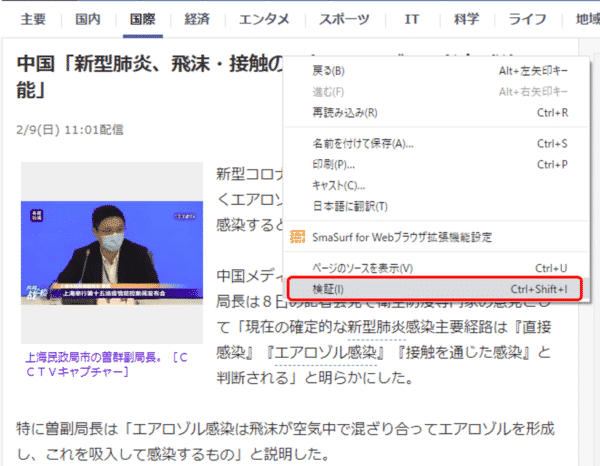
そして該当箇所のHTMLを確認すると、class属性”ynDetailText yjDirectSLinkTarget”を持つpタグのテキストの中に、ニュースの本文が含まれていることがわかります。
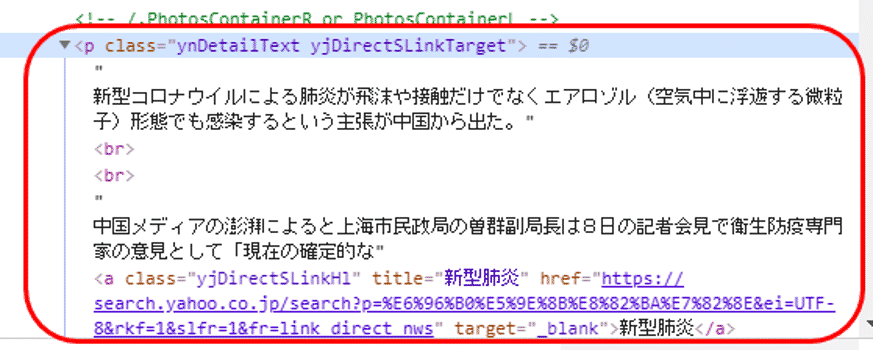
ここではclass属性に”DetailText”を含む要素をあいまい検索しましょう。文字列のパターンで検索できるライブラリreを使います。
ライブラリreのcompile()を利用して、class_=re.compile("DetailText") をfind ()の引数として渡します。ここでは、class属性の中で"DetailText"が含まれているものを抽出しています。
detail_text = news_soup.find(class_=re.compile("DetailText"))
print(detail_text.text if hasattr(detail_text, "text") else '',end='\n\n\n\n')
そして抽出した結果をprint()で表示しています。
その際、text属性がある場合はそのままtextの内容を、無い場合は’’(シングルクォーテーションが2つ)で何も表示しないようにしています。
また最後にはend引数に改行文字\nを4つ渡し、それぞれ取得した主要ニュースのテキストの間隔を空けるようにしています。
実行結果は、次のようになります。

(以下、省略)
1つ目のニュースのタイトル、URL、本文が表示され、そして、2つ目と続いて表示されました。最終的に主要ニュース一覧に表示されていた8つのニュースの本文が表示されます。
このようにして、Yahooの主要ニュースのように、階層化されたサイトのリンクを順にクローリングしながら、最終的に必要なニュースのテキスト情報を表示することができました。
HTMLの階層を移動してタグを指定する方法
Beautiful Soupはスクレイピングにおいて、HTMLの中から特定の情報を指定し取得するのに利用されます。
HTMLは次のようにタグと言う記号で構成されており、開始タグ、終了タグで囲まれたものを要素といいます。
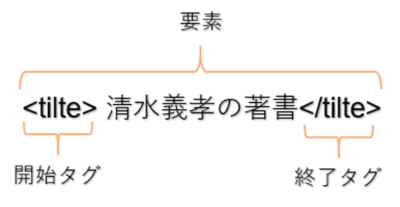
上記の要素はtitleタグに囲まれていますので、titile要素と言います。※この記事でのtitleタグなどXXタグという言い方は、titile要素などXX要素と同じ意味で用いています。
またHTMLは、1つのタグが別のタグで囲われ、というように入れ子の状態で記述されます。これらは階層構造とみなすことができます。
例えば次のHTMLについては、

このような階層構造で表すことができます。
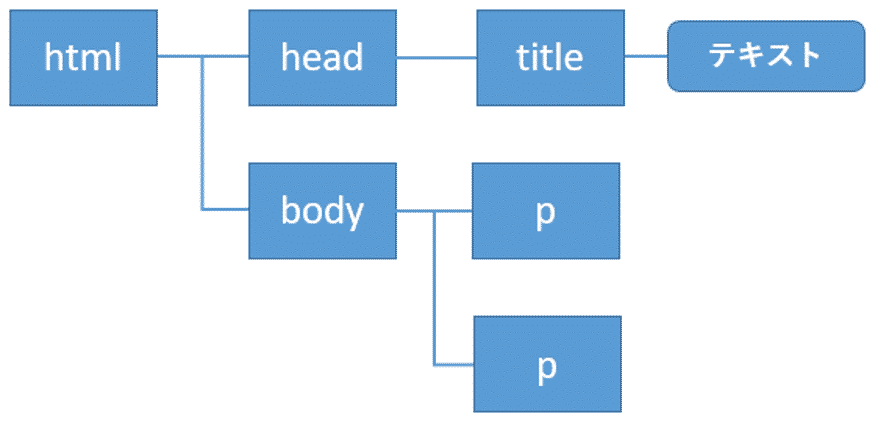
これらの階層構造の中には、同じ要素が含まれます。従って、Beautiful Soupで特定の要素を指定するには、うまく階層をたどる必要があります。
またHTMLのタグの中には、いくつかの属性が含まれることがあります。

これらは属性と属性値からなり、上記のclass属性の属性値は"book"になります。またその横のid="link1"も属性と属性値です。
属性にはid属性のように、HTMLの中で必ず重複しない属性値を持つものと、そうでないものとがあります。
Beautiful Soupでは、これらの属性を取得したり、これらの属性も組合せながら要素を指定したりします。
BeautifulSoupでの基本的なタグの指定方法
ここではまずBeautiful Soupでの基本的なタグの指定方法を説明していきます。
この基本的な書き方を理解した上で、後から説明する階層の前後をたどって要素を指定する方法などの応用的なトピックに進んでいってください。
サンプルコード
以降の章の説明で利用するコードを記載しておきます。HTMLをBeautifulSoup()へ渡すまでのコードになります。これを元に次の章のコードを実行してみてください。
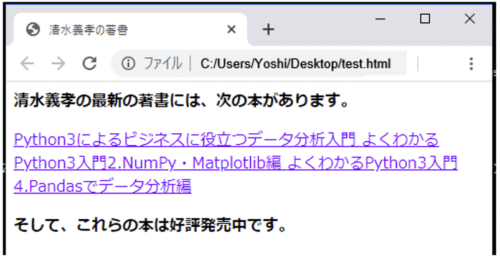
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | from bs4 import BeautifulSoup html = """ <html> <head> <title>清水義孝の著書</title> </head> <body> <p class="title"> <b>清水義孝の最新の著書には、次の本があります。</b> </p> <p class="recent books"> <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1"> Python3によるビジネスに役立つデータ分析入門 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2"> よくわかるPython3入門2.NumPy・Matplotlib編 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3"> よくわかるPython3入門4.Pandasでデータ分析編 </a> </p> <p class="end"> <b>そして、これらの本は好評発売中です。</b> </p> </body> </html> """ soup = BeautifulSoup(html,'html.parser') |
上記のHTMLは、実際にブラウザで表示すると次のようになります。
ルート(最上位層)からの指定方法
HTMLのルート(html要素)から指定する場合は、「.」(ドット)を使って記述します。
例えば、html – head – titleとたどってtitle要素を指定する場合、次のように書きます。

1 | print(soup.html.head.title) |
パス(階層)を省略して指定する方法
HTMLのルート(html要素)からではなく、パス(階層)を省略して途中から指定することもできます。
先ほどの例から.html.head を省略してtitleから記述してみましょう。
1 | print(soup.title) |
同様にtitle要素の内容が表示されました。
ここでは、例のHTMLにtitle1つしか含まれませんでしたので、表示された結果は、soup.html.head.titleと指定したのと同じです。
但し、HTMLの中にtitle要素がいくつか存在する場合に省略して記述すると、最初の要素が取得されます。
例えば、.body.pと指定すると、
1 | print(soup.body.p) |
<b>清水義孝の最新の著書には、次の本があります。</b>
</p>
bodyに含まれる3つのp要素の内、最初のものが表示されました。
その他の要素も取得したい場合、find_all()を使って取得するなどの工夫が必要になります。
1 2 | for p in soup.body.find_all("p"): print(p,end="\n\n") |
<b>清水義孝の最新の著書には、次の本があります。</b>
</p>
<p class="recent books">
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編
</a>
</p>
<p class="end">
<b>そして、これらの本は好評発売中です。</b>
</p>
bodyに含まれる3つのp要素が表示されました。それぞれの要素の間はprint()の引数end="\n\n"(出力後に改行を2つ挿入)の指定により改行しています。
テキストの表示: .string
要素に含まれるテキストを表示したい場合は .stringを使います。ここではtitleのテキストを表示しています。
1 | print(soup.title.string) |
全てのテキストの表示: get_text()
ページに含まれる全てのテキストを表示したい場合は get_text()を使います。
1 | print(soup.get_text()) |
清水義孝の最新の著書には、次の本があります。
Python3によるビジネスに役立つデータ分析入門
よくわかるPython3入門2.NumPy・Matplotlib編
よくわかるPython3入門4.Pandasでデータ分析編
そして、これらの本は好評発売中です。
属性値の表示: [] / get()
要素に含まれる属性の値を表示したい場合は [](スクェアブラケット)を使います。ここではbody配下のp要素に含まれるclass属性の値を表示しています。
1 | print(soup.body.p["class"]) |
属性に複数の値がある場合、リストに複数の値が入ります。
ここではbody配下の2つ目のp要素に含まれるclass属性の値を表示しています。next_siblingについては後ほど解説します。
1 | print(soup.body.p.next_sibling.next_sibling["class"]) |
2つ目のpタグは、<p class="recent books">となっています。class属性に空白を挟んで2つの単語がある場合、2つの属性値があるとみなされます。
また属性値はget()でも取得することができます。
1 | print(soup.body.p.get("class")) |
HTMLを整形して表示: print + prettify
prettify()を使うと1行に1タグのきれいにフォーマットされた形式でHTMLの内容を確認できます。
prettify()は次のように記述します。
1 | print(soup.prettify()) |

親・先祖・兄弟・子・子孫要素の指定方法
今までの説明では、ルートもしくは途中のパスからから階層を降りて目的の要素を指定していました。

例えば、html – head – titleとたどってtitle要素を指定する場合、次のように書きます。
1 | print(soup.html.head.title) |
但し、時にはある要素の親の要素やそのさらに親の要素(先祖要素)、子の要素とその子の要素(子孫要素)、同じ親を持つ子要素同士(兄弟要素)などを指定する必要があります。
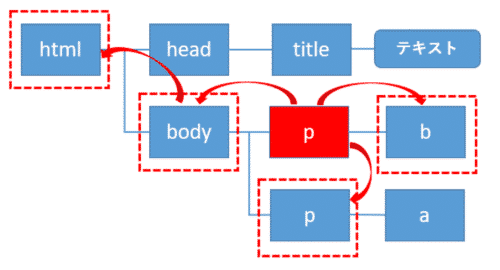
これらはBeautiful Soupでは属性を使って指定します。
属性には次のようなものがあります。
| 属性 | 説明 |
| .contents | 子要素(リスト型) |
| .children | 子要素(イテレータ型) |
| .descendants | 子孫要素 |
| .parent | 親要素 |
| .parents | 先祖要素 |
| .next_sibling | 次の兄弟要素 |
| .previous_sibling | 前の兄弟要素 |
| .next_siblings | 次の全ての兄弟要素 |
| .previous_siblings | 前の全ての兄弟要素 |
ここではこれらの属性の指定方法を詳しく確認していきます。
HTMLの階層構造
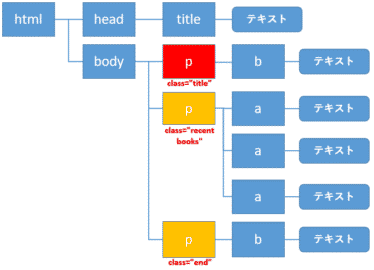
親・先祖・兄弟・子・子孫要素の指定方法を確認する前に、兄弟要素や先祖要素などの言葉の定義を確認しましょう。
親・子・兄弟要素
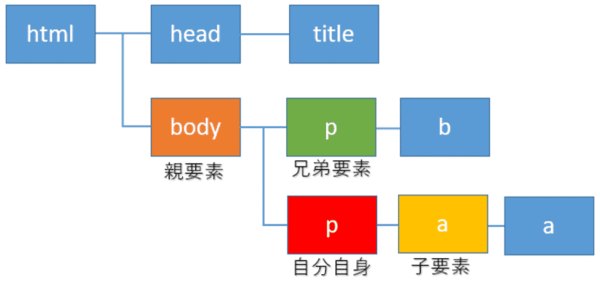
ここでは、自分自身の要素を赤色のp要素とします。そこから1階層上に上がったbody要素(オレンジ色)が親要素になります。
また1つ階層を下に降りたa要素(黄色)が子要素になります。また同じ親要素の子である緑色のp要素は兄弟要素と呼ばれます。
先祖・子孫要素
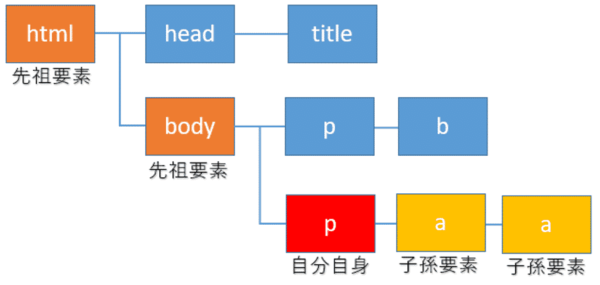
また同様に自分自身の要素を赤色のp要素とします。そこから1階層上に上がったbody要素とさらに階層を上がったその親要素htmlが先祖要素(オレンジ色)になります。
そして、階層を下に順に下がっていった要素は子孫要素(黄色)と言います。
子要素の取得: .contents / .children
自分自身をbody要素(赤色)とすると、子要素とは黄色の要素になります。
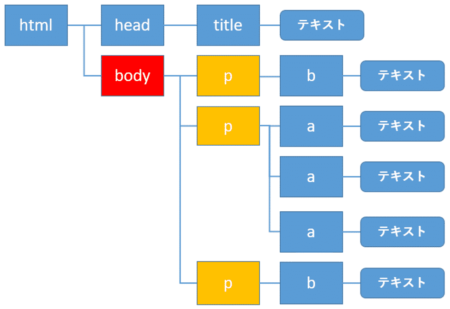
これらの子の要素を取得するには、属性に.contentsを指定します。
1 2 | for child in soup.body.contents: print(child,end="\n\n") |
<b>清水義孝の最新の著書には、次の本があります。</b>
</p>
<p class="recent books">
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編
</a>
</p>
<p class="end">
<b>そして、これらの本は好評発売中です。</b>
</p>
contents属性はリストで返ってくるので、インデックスを指定して好きな要素にアクセスすることができます。但し、HTMLには空白や改行が含まれますので、注意が必要です。
1 | print(soup.body.contents[0]) |
何も表示されませんでした。インデックス0には空白や改行が入っていたようです。
インデックス1を指定すると、
1 | print(soup.body.contents[1]) |
<b>清水義孝の最新の著書には、次の本があります。</b>
</p>
最初のp要素の内容が表示されました。このようにして、インデックスを指定して、各要素にアクセスすることができます。
また子要素は.childrenでも取得することができます。こちらはイテレータで返ってきますので、各要素に順序どおりにアクセスするのに使います。
1 2 | for child in soup.body.children: print(child, end="\n\n") |
<b>清水義孝の最新の著書には、次の本があります。</b>
</p>
<p class="recent books">
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編
</a>
</p>
<p class="end">
<b>そして、これらの本は好評発売中です。</b>
</p>
子孫要素の取得: .descendants
自分自身の要素をhead要素(赤色)とすると、子孫の要素は黄色の要素になります。

子孫要素を取得するには、属性に.descendantsを指定します。
1 2 | for child in soup.head.descendants: print(child,end="\n\n") |
清水義孝の著書
ここではtitile要素とその子要素のテキストが表示されました。
親要素の取得: .parent
今度は自分自身の要素をtitle要素(赤色)とすると、親要素は黄色のhead要素になります。

親要素を取得するには、属性に.parentを指定します。
1 | print(soup.title.parent) |
<title>清水義孝の著書</title>
</head>
head要素の内容が表示されました。
先祖要素の取得: .parents
次に自分自身の要素を赤色のa要素とすると、先祖要素は黄色のp、body、html要素になります。
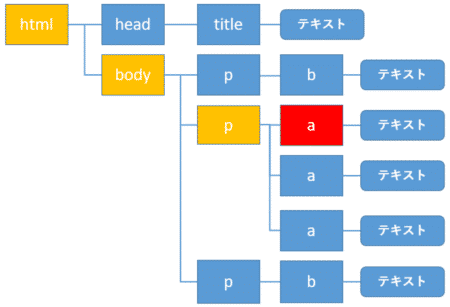
先祖要素を取得するには、属性に.parentsを指定します。ここでは.nameを付けて要素名だけを表示しましょう。
1 2 | for parent in soup.a.parents: print(parent.name) |
body
html
[document]
p、body、htmlとa要素の先祖要素が表示されました。
次の兄弟要素の取得: .next_sibling / .next_siblings
次に自分自身の要素を赤色のp要素とすると、次の兄弟要素は黄色のp要素になります。
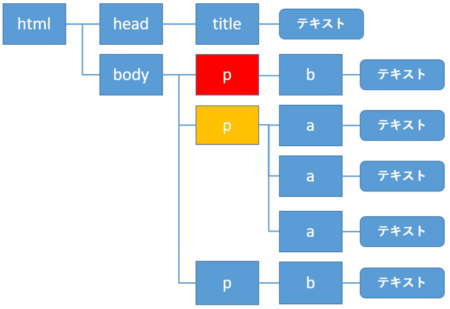
次の兄弟要素を取得するには、属性に.next_siblingを指定します。ここでは.nameを付けて要素名だけを表示しましょう。但し、HTMLには空白や改行が含まれますので、注意が必要です。
1 | print(soup.body.p.next_sibling) |
何も表示されませんでした。
このような場合、もう1つ.next_siblingを付けます。
1 | print(soup.body.p.next_sibling.next_sibling) |
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編
</a>
</p>
2つ.next_siblingを記述することで、次のp要素(class="recent books")の情報を取得することができました。
また1つ目だけでなく、次の全ての兄弟要素を取得するには .next_siblingsを使います。
1 2 | for sibling in soup.body.p.next_siblings: print(sibling if sibling != "\n" else "", end = "\n\n") |
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編
</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編
</a>
</p>
<p class="end">
<b>そして、これらの本は好評発売中です。</b>
</p>
次にある全て(ここでは2つ)の兄弟要素の情報を取得することができました。
前の兄弟要素の取得: .previous_sibling / .previous_siblings
次に自分自身の要素を赤色のbody要素とすると、前の兄弟要素は黄色のhead要素になります。
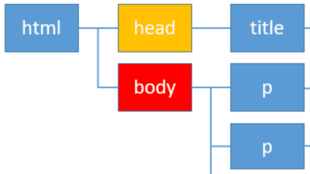
前の兄弟要素を取得するには、属性に.previous_siblingを指定します。
1 | print(soup.body.previous_sibling.previous_sibling) |
<title>清水義孝の著書</title>
</head>
head要素の内容が表示されました。
次に全ての前の兄弟要素を取得してみましょう。
例を変えて、自分自身の要素を赤色のp要素とすると、前の兄弟要素は黄色の2つのp要素になります。
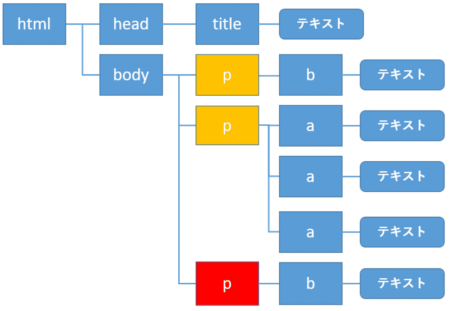
全ての前の兄弟要素を取得するには、属性に.previous_siblingsを指定します。ここではclass属性の値を表示してみましょう。
1 2 | for sibling in soup.body.find("p", class_="end").previous_siblings: print(sibling["class"] if sibling != "\n" else "", end = "\n\n") |
全ての前の兄弟要素(ここでは2つのp要素)のclass属性の値が表示されました。
find_allメソッドの使い方の詳細解説
この章ではfind_all()の使い方を詳しく解説していきます。
find_all: Tagオブジェクト、引数、戻り値
find_all()は、Tagオブジェクトが持つ子孫要素のうち、引数に一致する全ての要素を取得します。
例えば、soup.body.find_all()と指定した場合、bodyタグの子孫要素から、引数に一致するすべての要素を取得します。
またタグの指定をせずにsoup.find_all()と指定した場合、BeautifulSoupに渡したHTML全体の中から、引数に一致するすべての要素を取得します。
| 引数 | 説明 |
| name | タグを指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
| attrs | タグの属性を辞書で渡し指定する。 |
| recursive | Tagオブジェクトの検索対象範囲を指定。 True: Tagオブジェクトの全ての子孫要素を検索。 False: Tagオブジェクトの直下の子要素のみを検索。 |
| text | タグに挟まれているテキスト(文字列)を指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
| imit | 検索条件にマッチしたタグ・文字列の取得する数を制限する。 |
| キーワード引数 | タグの属性を指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
これらのfind_all()の引数について、1つ1つ順に詳細を確認していきましょう。
サンプルコード
前の章と同じですが、以降の章の説明で利用するコードを再掲しておきます。HTMLをBeautifulSoup()へ渡すまでのコードになります。これを元に次の章のコードを実行してみてください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | from bs4 import BeautifulSoup html = """ <html> <head> <title>清水義孝の著書</title> </head> <body> <p class="title"> <b>清水義孝の最新の著書には、次の本があります。</b> </p> <p class="recent books"> <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1"> Python3によるビジネスに役立つデータ分析入門 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2"> よくわかるPython3入門2.NumPy・Matplotlib編 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3"> よくわかるPython3入門4.Pandasでデータ分析編 </a> </p> <p class="end"> <b>そして、これらの本は好評発売中です。</b> </p> </body> </html> """ soup = BeautifulSoup(html,'html.parser') |
上記のHTMLは、実際にブラウザで表示すると次のようになります。
find_all: name引数
name引数は、取得するタグを指定するのに使います。文字列、正規表現、リスト、関数、True値で指定することができます。
文字列
name引数に文字列を渡すと、文字列に一致するタグを取得します。
1 | soup.find_all("title") |
titleタグの内容を取得することができました。
リスト
検索条件に複数のタグを指定したい場合、name引数にリストで渡すこともできます。リスト内の複数のタグのいずれかに一致したものを取得します。
1 | soup.find_all(["a", "b"]) |
, <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>
, <b>そして、これらの本は好評発売中です。</b>]
ここではリストに含まれる、aタグ、bタグの情報が取得されました。
正規表現
name引数では、正規表現のreモジュールを用いて前方一致や部分一致など、タグを柔軟に検索することができます。
また利用前にreモジュールをインポートしてください。
この例では、全ての"b"ではじまるタグを検索します。記号「^」は、文字列の先頭からパターンに一致するかを判定します。
1 2 3 | import re for tag in soup.find_all(re.compile("^b")): print(tag.name) |
b
b
ここでは"b"から始まるbodyとbタグに一致しました。
True値
name引数にTrue値を渡すと、Tagオブジェクトの全ての子孫要素を取得します。
例えば以下のコードは、bodyタグ内の全てのタグを取得します。
1 2 | for tag in soup.body.find_all(True): print(tag.name) |
b
p
a
a
a
p
b
関数
name引数には、上記の引数以外に、自分で関数を定義しfind_all()に渡すこともできます。自作の関数の引数には、検索対象のタグを渡します。
またその関数は、引数が条件に一致したときはTrueを、一致しないときは False を返します。
以下の関数の例では、タグにclass属性があり、かつ、id属性はない場合に True を返します。
1 2 | def has_class_but_no_id(tag): return tag.has_attr('class') and not tag.has_attr('id') |
この自作の関数をfind_all() に渡します。
1 | soup.find_all(has_class_but_no_id) |
, <p class="recent books"> <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a></p>
, <p class="end"> <b>そして、これらの本は好評発売中です。</b></p>]
実行すると、class属性があり、id属性がない3つのpタグが取得されました。
find_all: キーワード引数
キーワード引数としてタグの属性を指定し、一致するタグの情報を取得できます。
キーワード引数の値もまた、 文字列、正規表現、リスト、関数、True値をとることができます。そして、複数のキーワード引数も指定できます。
例えば、キーワード引数としてhref に値を渡すと、Beautiful SoupはHTMLタグのhref属性に対してフィルタリングを行います。:
1 | soup.find_all(href=re.compile("http://")) |
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
ここではhref属性に文字列”http://”を含むタグを取得しています。
次のコードは、id属性に何か値が入っている全てのタグを見つけます。
1 | soup.find_all(id=True) |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
また複数のキーワード引数を一度に渡すことによって、複数の属性についてフィルタリングできます。
1 | soup.find_all(href=re.compile("http://"), id="link3") |
よくわかるPython3入門4.Pandasでデータ分析編</a>]
class属性を指定する場合、「class_」とアンダーバーを付けてください。「class」はpythonの予約語に含まれますので、そのままでは使用できません。
1 | soup.find_all("a", class_="book") |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
find_all: attrs引数
属性を辞書にして引数 attrs として値を渡しても、属性で検索することができます。辞書にはキーとして属性を、値として属性値を設定します。
例えば、以下のコードでは、辞書でid属性、属性値”link2”を渡しています。
1 | soup.find_all(attrs={"id": "link2"}) |
よくわかるPython3入門2.NumPy・Matplotlib編</a>]
また辞書で複数の属性を渡すことで、複数条件での検索も可能です。
1 | soup.find_all(attrs={"class": "book", "id": "link2"}) |
よくわかるPython3入門2.NumPy・Matplotlib編</a>]
class属性が”book”、かつ、id属性が”link2”を持つaタグの内容が表示されました。
find_all: text引数(テキストの検索)
text引数で、タグに挟まれているテキストの文字列を対象として検索することができます。
name引数やキーワード引数と同様、 文字列、正規表現、リスト、関数、True値で指定できます。
例えば以下のコードでは、テキスト”清水義孝の著書”を検索しています。
1 | soup.find_all(text="清水義孝の著書") |
また完全一致でテキストを検索するのではなく、正規表現を使ってテキスト"Python3"を含むものという条件で検索もできます。
1 | soup.find_all(text=re.compile("Python3")) |
'\n よくわかるPython3入門2.NumPy・Matplotlib編\n ',
'\n よくわかるPython3入門4.Pandasでデータ分析編\n ']
find_all: limit引数
find_all()では指定した条件に一致するすべてのタグ・文字列を取得しますが、limit引数により取得する数を制限できます。
最初に一致したいくつかのタグ・文字列しか必要のない場合に設定すると良いです。
次の場合、該当するaタグは3つあります。
1 | soup.find_all("a") |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
引数limitに2を渡すことにより、最初の2つしか取得しません。
1 | soup.find_all("a", limit=2) |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>]
find_all: recursive引数
Tagオブジェクトの検索対象範囲を指定します。通常は(何も指定しない、もしくはTrueを指定した場合)、Tagオブジェクトの全ての子孫要素を検索します。
Falseを指定した場合、Tagオブジェクトの直下の子要素しか検索しません。従って、直下の子要素しか検索する必要がないケースだけ、Falseを指定してください。
例えば次のコードでは、bodyの子孫要素も含めてaタグを検索します。
1 | soup.body.find_all("a") |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
一方で次のコードでは、recursiveにFalseを指定しているのでbodyの直下の子要素までしか検索しません。
1 | soup.body.find_all("a", recursive=False) |
従って、該当するaタグがありませんでした。
findメソッドの使い方の詳細解説
この章ではfind()の使い方を詳しく解説していきます。
find: Tagオブジェクト、引数、戻り値
find()は、Tagオブジェクトが持つ子孫要素のうち、引数に一致する最初の1つの要素を取得します。最初の1つしか取得する必要のない場合、find()を利用しましょう。
Tagオブジェクトの説明は、find_all()と同じなので省略します。
この点を除き、引数limitで1を指定したfind_all()と結果は同じです。
また一致するものがない場合、Noneを返します。
| 引数 | 説明 |
| name | タグを指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
| attrs | タグの属性を辞書で渡し指定する。 |
| recursive | Tagオブジェクトの検索対象範囲を指定。 True: Tagオブジェクトの全ての子孫要素を検索。 False: Tagオブジェクトの直下の子要素のみを検索。 |
| text | タグに挟まれているテキスト(文字列)を指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
| キーワード引数 | タグの属性を指定する。 文字列、正規表現、リスト、関数、True値での指定が可能。 |
サンプルコード
前の章と同じですが、以降の章の説明で利用するコードを再掲しておきます。HTMLをBeautifulSoup()へ渡すまでのコードになります。これを元に次の章のコードを実行してみてください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | from bs4 import BeautifulSoup html = """ <html> <head> <title>清水義孝の著書</title> </head> <body> <p class="title"> <b>清水義孝の最新の著書には、次の本があります。</b> </p> <p class="recent books"> <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1"> Python3によるビジネスに役立つデータ分析入門 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2"> よくわかるPython3入門2.NumPy・Matplotlib編 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3"> よくわかるPython3入門4.Pandasでデータ分析編 </a> </p> <p class="end"> <b>そして、これらの本は好評発売中です。</b> </p> </body> </html> """ soup = BeautifulSoup(html,'html.parser') |
findとfind_allの違い
find_all()では引数limitに1を渡すことにより、最初の1つしか取得しません。
1 | soup.find_all("a", limit=1) |
Python3によるビジネスに役立つデータ分析入門</a>]
リストで結果が返ってきました。
今度はfind()で最初のaタグを取得してみましょう。
1 | soup.find("a") |
Python3によるビジネスに役立つデータ分析入門</a>
取得できた最初のaタグの内容が表示されました。リストではありません。
selectメソッドの使い方の詳細解説
この章ではselect()の使い方を詳しく解説していきます。
select: Tagオブジェクト、引数、戻り値
select()は、Tagオブジェクトが持つ子孫要素のうち、引数のCSSセレクタに一致する全ての要素を取得します。
Tagオブジェクトの説明は、find_all()と同じなので省略します。詳細は「find_allメソッドの使い方の詳細解説」を参照ください。
サンプルコード
前の章と同じですが、以降の章の説明で利用するコードを再掲しておきます。HTMLをBeautifulSoup()へ渡すまでのコードになります。これを元に次の章のコードを実行してみてください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | from bs4 import BeautifulSoup html = """ <html> <head> <title>清水義孝の著書</title> </head> <body> <p class="title"> <b>清水義孝の最新の著書には、次の本があります。</b> </p> <p class="recent books"> <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1"> Python3によるビジネスに役立つデータ分析入門 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2"> よくわかるPython3入門2.NumPy・Matplotlib編 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3"> よくわかるPython3入門4.Pandasでデータ分析編 </a> </p> <p class="end"> <b>そして、これらの本は好評発売中です。</b> </p> </body> </html> """ soup = BeautifulSoup(html,'html.parser') |
select: 要素の取得
要素を指定する場合は、そのまま要素名を記述します。
例えば、html – head – titleと階層になっている中のtitle要素を指定する場合、次のように書きます。
1 | soup.select("title") |
要素が複数ある場合、複数の要素が取得されます。
1 | soup.select("b") |
, <b>そして、これらの本は好評発売中です。</b>]
ここでは2つのb要素が取得されました。
またCSSセレクタの取得する対象は、Tagオブジェクトの子孫要素からになります。次のコードの場合、body配下の最初のp要素(赤色)の子孫要素から要素が取得されます。
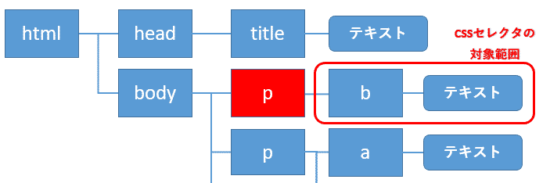
1 | soup.body.p.select("b") |
ここではb要素が1つしかありません。
select: 複数要素の取得
複数の要素を取得する場合は、要素名をカンマで区切って記述します。
例えば、titile要素とb要素を取得する場合は次のように書きます。
1 | soup.select("title, b") |
, <b>清水義孝の最新の著書には、次の本があります。</b>
, <b>そして、これらの本は好評発売中です。</b>]
select: テキストの取得
CSSセレクタではテキストを指定できません。ある要素の配下にあるテキストを取得する場合は、その要素を取得して、テキストは.stringで取得します。
例えばtitile要素の配下にあるテキストを取得する場合、次のように書きます。
1 | soup.select("title")[0].string |
soup.select("title")でtitile要素を取得し、結果がリストで返ってきますので、[0]で最初の要素を指定します。そして.stringでテキストを取得しています。
select: class属性の取得
class属性を取得する場合、.(ドット)の後にclass属性の属性値を書いて指定します。ここでは、class属性の値に”end”を持つ要素を取得しています。
1 | soup.select(".end") |
class属性の値に”end”を持つp要素が取得されました。
また要素と合わせてclass属性を指定することもできます。その場合は、要素名.class属性の値と記述します。
1 | soup.select("p.end") |
先ほどと同じく、class属性の値に”end”を持つp要素が取得されました。
select: 複数の属性値を持つclassの取得
class属性は複数の属性値をもつことができます。その場合、class=”属性値1 属性値2”とスペースをはさんで複数の属性値が記入されます。
例えばサンプルのHTMLでは、以下のp要素がclass属性に複数の値、”recent”と”books”をもちます。
これらのclassの属性値は、.recentなどと1つずつ指定しても良いですが、合わせて指定したい場合があります。その場合、.属性値1.属性値2と指定します。
1 | soup.select(".recent.books") |
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>
</p>]
select: id属性の取得
id属性を取得する場合、#(シャープ)の後にid属性の値を書きます。ここでは、id属性の値に”link2”を持つ要素を取得しています。
1 | soup.select("#link2") |
よくわかるPython3入門2.NumPy・Matplotlib編</a>]
id属性が”link2”のa要素が取得されました。
select: 正規表現を用いたhref属性の指定
href属性を取得する場合、次のように書きます。
もしくは、要素名は省略することもできます。
これらの指定では、属性値は完全に一致していなければ取得できません。
href属性にはURLが含まれますので、https://から始まるもの、google.co.jpが含まれるものなど、前方一致やあいまい検索が必要になります。
その場合、正規表現を用いて検索することができます。
| 検索タイプ | 書式 | 説明 |
| 前方一致 | [href^="属性値(先頭)"] | 指定された属性値(先頭)からhref属性の値が始まるものを取得 |
| 後方一致 | [href$="属性値(末尾)"] | 指定された属性値(末尾)でhref属性の値が終わるものを取得 |
| あいまい検索 | [href*="属性値"] | 指定された属性値がhref属性の値に含まれるものを取得 |
例) 正規表現でのhref指定(前方一致)
href属性が"http:"から始まるa要素を取得します。
1 | soup.select('a[href^="http:"]') |
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
href属性が"http:"から始まる2つのa要素が取得されました。
例) 正規表現でのhref指定(後方一致)
href属性が”96B”で終わるa要素を取得します。
1 | soup.select('a[href$="96B"]') |
よくわかるPython3入門4.Pandasでデータ分析編</a>]
例) 正規表現でのhref指定(あいまい検索)
href属性に"amazon"を含むa要素を取得します。
1 | soup.select('a[href*="amazon"]') |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
href属性をもつa要素は3つとも"amazon"を含みますので、全て表示されました。
select: 子孫要素の取得
自分自身の要素をbody要素(赤色)とすると、子孫の要素は黄色の要素になります。
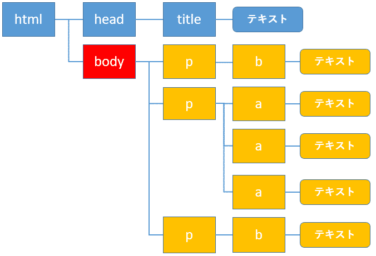
子孫要素を指定するには、次のように記述します。
※2つの要素の間にはスペースを入れます。
body要素の子孫要素の内、a要素を取得してみましょう。
1 | soup.select("body a") |
Python3によるビジネスに役立つデータ分析入門</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
, <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>]
3つのa要素が取得されました。
select: 子要素の取得
自分自身の要素をbody要素(赤色)とすると、子の要素は黄色の要素になります。
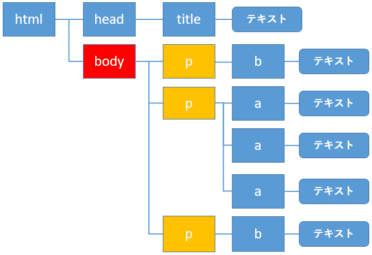
子要素を指定するには、> を用いて指定します。
例えば、body要素の子要素の内、class属性に"end"をもつp要素を取得する場合、次のように書きます。
1 | soup.select("body > p.end") |
select: 隣接する直後の兄弟要素の取得
自分自身の要素をclass属性に"title"をもつp要素(赤色)とすると、直後の兄弟要素は黄色の要素になります。
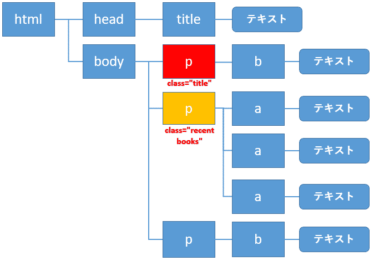
直後の兄弟要素を指定するには、+ を用いて指定します。
class属性に"title"をもつp要素の直後の兄弟要素を取得します。
1 | soup.select("p.title + p") |
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a>
</p>]
select: 後ろの全ての兄弟要素の取得
自分自身の要素をclass属性に"title"をもつp要素(赤色)とすると、後ろの兄弟要素は黄色の要素になります。
後ろの全ての兄弟要素を指定するには、~(チルダ) を用いて指定します。
class属性に"title"をもつp要素の後ろの兄弟要素を取得します。
1 | soup.select("p.title ~ p") |
<a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1">
Python3によるビジネスに役立つデータ分析入門</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2">
よくわかるPython3入門2.NumPy・Matplotlib編</a>
<a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3">
よくわかるPython3入門4.Pandasでデータ分析編</a></p>
, <p class="end"><b>そして、これらの本は好評発売中です。</b>
</p>]
class属性にそれぞれ"recent books"、"end"をもつ2つのp要素を取得できました。
select: リストの取得
異なる形式のHTMLからの要素の取得方法も確認していきましょう。ここでは例としてリストを取り上げたいと思います。
ここでも以降の章の説明で利用するコードを再掲しておきます。これを元に次の章のコードを実行してみてください。
1 2 3 4 5 6 7 8 9 10 | from bs4 import BeautifulSoup html = """ <ul id="book"> <li>Python3によるビジネスに役立つデータ分析入門</li> <li>よくわかるPython3入門1.基礎編</li> <li>よくわかるPython3入門2.NumPy・Matplotlib編</li> <li>よくわかるPython3入門4.Pandasでデータ分析編</li> </ul> """ soup = BeautifulSoup(html,'html.parser') |
この例のリストは階層構造として順不同のリストを示すul要素を親に、リスト項目を示す複数のli要素を子に持ちます。
リストの全ての要素の取得
リストの全ての要素を取得してみましょう。
この例にはありませんが、同じHTML内に複数のリストがある場合を考慮して、まずはul要素を特定する必要があります。
ここではid属性に"book"をもつul要素を指定してから、その子要素のliを取得しています。
1 | soup.select("ul#book > li") |
<li>よくわかるPython3入門1.基礎編</li>,
<li>よくわかるPython3入門2.NumPy・Matplotlib編</li>,
<li>よくわかるPython3入門4.Pandasでデータ分析編</li>]
リストの全ての要素が取得されました。
リストのn番目の要素の取得
リストのn番目の要素の取得は、次のように記述します。
リストの最初の要素を取得してみましょう。
1 | soup.select("ul#book > li:nth-of-type(1)") |
リストの2番目の要素を取得してみましょう。
1 | soup.select("ul#book > li:nth-of-type(2)") |
このようにしてリストの要素もCSSセレクタを使って取得することができました。
リストには順不同のリストを示すul要素、順番のあるリストを示すol要素などがありますが、同様に取得することができます。
Seleniumと連携し画像ファイルをダウンロード・保存する方法
以下の記事では、Seleniumと連携し画像ファイルをダウンロード・保存する方法を解説してます。
Seleniumを使ってインスタグラムへログインし、画面をスクロールさせながら画像のURLが入っているimgタグのsrc属性の情報をリストに格納しています。
そしてリストに格納した情報を元に、Requestsを使って画像をダウンロードし保存しています。
宜しければご参照ください。

関連記事です。
Pythonを使ったスクレイピングについての詳細は、こちらをご覧ください。












