WEBスクレイピングとは、WEBサイトから情報を自動的に取得し、必要に応じて、情報の加工などを行うことです。取得したデータは、ファイルやデータベースに保存します。
スクレイピングで取得したいデータのニーズは様々ですが、その中でも、株価の履歴情報を取得し、分析に利用したいというニーズは高く、スクレイピングを勉強するきっかけとなっている人も多いようです。
ただ、株価の情報はWEBサイトで公開されていますが、スクレイピングを禁止しているサイトも多く、またスクレイピングを禁止していなくても、継続的に株価を提供しているサイトはとても少ないです。
今回は、その中でもStooq.comというサイトから、Pythonのデータ分析用ライブラリPandasのread_html()を利用し、日本の個別株の情報を取得したいと思います。
米国株の取得方法は「Pandasによるテーブルのスクレイピングと保存」を参照ください。
read_html()では、WEBサイト上のテーブルに格納されているデータを非常に簡単に取得することができます。
同様の株価のデータはpandas_datareaderを使っても取得することができますが、データ取得元のサイトへのアクセスが禁止されると使えなくなります。
従ってこれらのライブラリを使うだけでなく、その仕組みを理解し、別のサイトからも同様のデータを取得できるようになることは必要不可欠です。
必要に応じて取得元のサイトを変更し、安定的にデータを取得できるよう、この記事では、Pandasのread_html()を用いてWEBスクレイピングする方法と考え方を1ステップずつ解説し、日本株の株価情報をstooq.comから取得していきたいと思います。
read_html()の基本的な使い方や必要なライブラリのインストールも「Pandasによるテーブルのスクレイピングと保存」を参照ください。read_html()を利用するには、WEBスクレイピング用のライブラリBeautifulSoup4、html5lib、lxmlをインストールしておく必要があります。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
WEBスクレイピングによるStooqから日本の株価情報の取得
これから日本株の株価の取得方法を紹介していきます。ここでは、Stooq(https://stooq.com/)からトヨタ自動車の株価情報を取得してみます。
サイトの事前確認
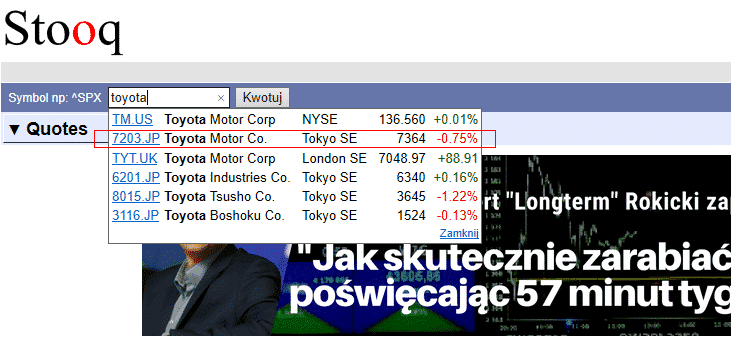
まずはStooqのサイトから、画面左上にある「Symbol np:^SPX」の横にあるテキストボックスに「toyota」と入力すると、下のようにリストが表示されます。その中から、「7203.JP」を選択してください。
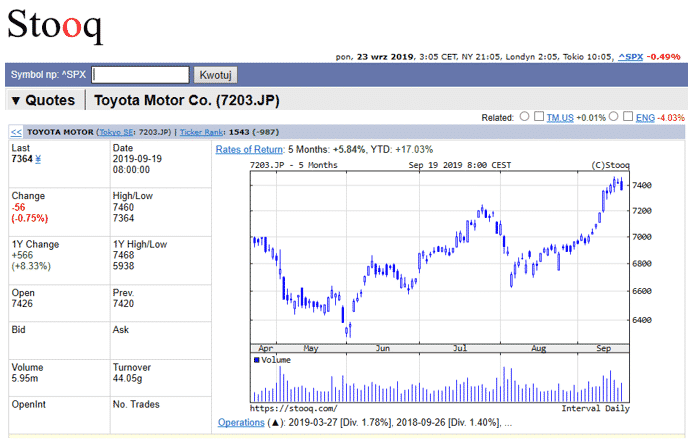
そして次のようにグラフの画面が表示されましたら、画面右下の「More On 7203.JP」の欄にいきます。
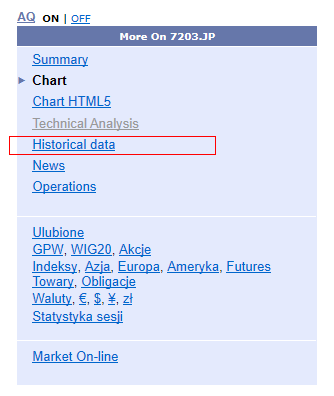
「More On 7203.JP」欄で「Historical data」をクリックします。
次に以下の赤線で囲ったエリアの項目を入力していきます。ここでは、Start dateにApr 1 2019を、End dateにSep 20 2019を選択し、IntervalはDailyのままにしておきます。そして、Showボタンを押します。
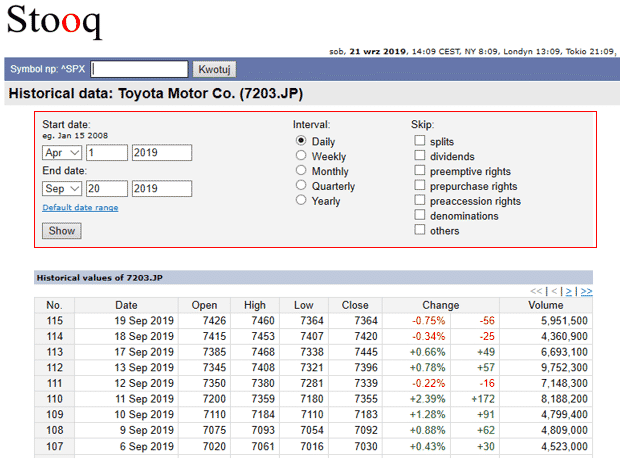
すると、画面の下に入力した条件に一致する株価の情報(赤線で囲った箇所)が表示されました。
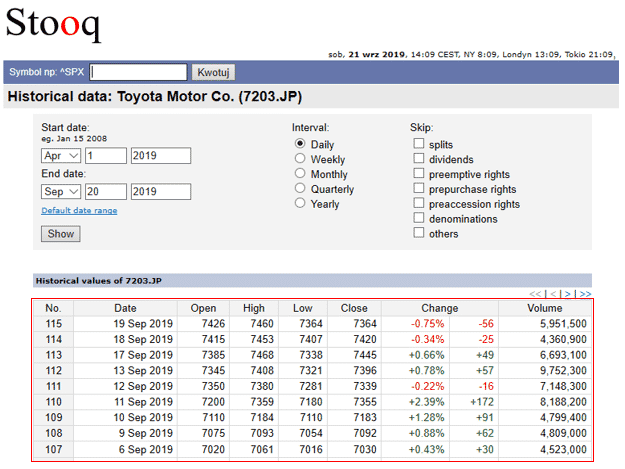
ここでは40日分ずつ情報が表示され、表の右上、もしくは、右下にある矢印のボタンでページを切り替えて、残りの日の情報も確認できるようです。
画面を切り替えながらURLを見ていくと、
最初のページは、
https://stooq.com/q/d/?s=7203.jp&c=0&d1=20190401&d2=20190920
次のページは、
https://stooq.com/q/d/?s=7203.jp&i=d&d1=20190401&d2=20190920&l=2
その次のページは、
https://stooq.com/q/d/?s=7203.jp&i=d&d1=20190401&d2=20190920&l=3
となっているようです。
ここから法則を確認すると、それぞれ以下の箇所は、
s=7203.jp:銘柄コード
d1=20190401:検索開始日付
d2=20190920:検索終了日付
l=3:ページ数
を示しているようです。
またページ数については、1ページ目はURLに「&l=1」とは表示されていませんでしたが、これを付けて入力すると、1ページ目が表示されました。
この法則を利用して、1ページ目から順に最後の数値だけを1つずつ加算していけば、全てのデータを確認することができそうです。
1ページ目の株価情報の取得
それでは実際にプログラムを書いていきましょう。まずpandasをインポートします。
1 | import pandas as pd |
次にページ数を除いたURLの一部を変数url_1に格納します。
1 | url_1 = 'https://stooq.com/q/d/?s=7203.jp&i=d&d1=20190401&d2=20190920&l=' |
これから最初のページを読み込みます。最初のページはURLの末尾に1を付け、変数urlに格納します。
1 2 | i = 1 url = url_1 + str(i) |
そして、read_html()に対して、変数urlを渡し、引数headerに0行目を指定します。取得した結果は、変数dataに格納されます。
1 | data = pd.read_html(url, header = 0) |
それではWEBページから取得したテーブルの情報を表示してみましょう。結果はリストの形式で取得されます。例えば、読み込み対象のWEBページに複数のテーブルがある場合、1つ目のテーブルは[0]、2つ目のテーブルは[1]で確認することができます。
ここではテーブルが1つしかありませんので、[0]で確認します。head()を使って最初の10行を表示してみましょう。
1 | data[0].head(10) |
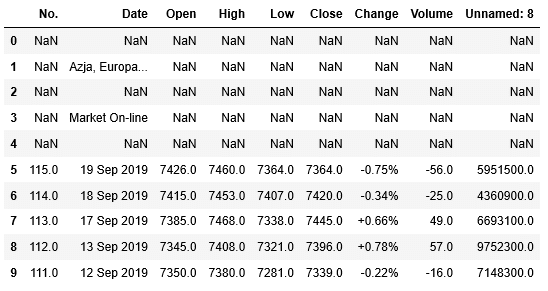
最初の5行は欠損値を示すNaN(Not a number)になっていて、データが入っていないようです。
合わせて、tail()を用いて、後ろからの5行も内容を確認しましょう。
1 | data[0].tail() |
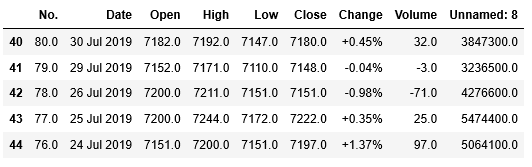
後ろの5行にはNaNは含まれていないようです。
最初の5行に含まれていたNaNを取り除きましょう。変数dataに格納されているデータの内、スライスを利用して5行目以降のデータを取得し、変数df_stockに格納します。そして最初の5行を確認します。
1 2 | df_stock = data[1][5:] df_stock.head() |
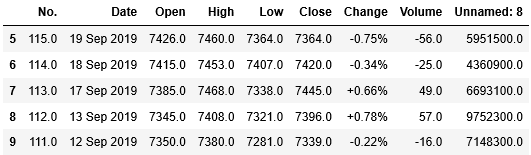
データが入っていなかったNaNの行は無くなりました。ここまでで、まずは1ページ目のデータを取得することができました。
2ページ目以降の株価情報の取得
次に2ページ目以降のデータも取得していきます。2ページ目以降はfor文の繰り返し処理で取得できそうです。但し、最後のページで繰り返し処理を終える必要があります。その条件は何になるでしょうか?最後のページを見てみましょう。

すると、最後のページの最終行では、列No.の値が1で終わっているようです。これをfor文の終了の判定条件に使うことができそうです。
それでは、残りのページからデータを読み込む処理を書いてみましょう。
1 2 3 4 5 6 | for i in range(2,100): url = url_1 + str(i) data = pd.read_html(url) df_stock = df_stock.append(data[1][5:]) if float(data[1]["No."].tail(1)) == 1.0: break |
プログラムの内容を解説すると、for i in range(2,100): では、2ページ目以降の読み込み処理をする為、2から99までの数値をiに格納しながら、順に繰り返し処理を実行しています。ページ数は多くないので、ここでは99を最後としています。
次に、url = url_1 + str(i) でURLの末尾のページ数を代入し、読み込み対象のURLを変数urlに格納しています。
そして、data = pd.read_html(url) で対象のページのデータを読み込み、先ほどの1ページ目と同様、最初の5行にはNaNが入っているようですので、次のdf_stock = df_stock.append(data[1][5:]) で最初の5行を読み飛ばした結果を変数df_stockに格納しています。
最後に、if float(data[1]["No."].tail(1)) == 1.0: で各ページの最終行の列No.が1.0の場合、最終ページとしてbreak文で、for文の繰り返し処理を終えています。
それでは、取得したデータを確認してみましょう。最初の5行を表示します。
1 | df_stock.head() |
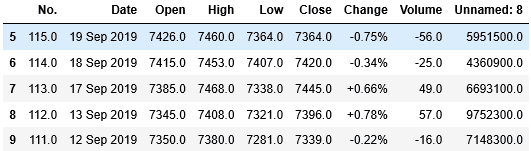
合わせて、後ろからの5行も確認します。
1 | df_stock.tail() |
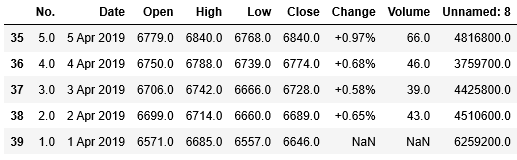
抽出条件に指定した2019年4月1日までのデータが表示されているようです。このようにして、全てのページのデータを取得することができました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
WEBスクレイピングで取得した日本の株価情報のグラフ(チャート)表示
取得データの問題点の確認
次に、これらの取得した情報を用いてグラフを表示してみたいと思います。但し、取得したデータを確認した結果、2つの問題があるようです。
- 列Changeは、元のサイト上の表は%と数値の2つの列をセル結合している為、取得したデータでは、タイトルがずれている。Changeの数値が入っている列のタイトルが「Volume」になり、実際に「Volume」の値が入っている列のタイトルが「Unnamed: 8」になっている。
- 列Dateに格納されている日付が、1 Apr 2019のように文字列になっていて、時系列にグラフを表示できない。
このような問題はWEBスクレイピングでは良く起こり得ます。日付、数値、欠損値にかかわらず、WEBサイト上はテキスト型で表示することができます。また表はセル結合されており、見た目には綺麗でも、データの取得がうまくいかないこともあります。
しかし、その情報をグラフ化したり、適切な形式で保存しようとすると、これらの情報を適切に処理してからでないと、グラフ表示やデータ保存することはできません。1つ1つ対処していきましょう。
不要な列の削除・列名の変更
まず1つ目のタイトルのズレについては、不要な列Change(%、数値)の2つの列を削除しましょう。合わせて列No.も不要ですので削除します。
DataFrameの列を削除するにはdrop ()を利用します。記述方法は次のようになります。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| 削除する列 | 必須 | 削除対象の列名。 複数の列が存在する場合、リストに格納。 |
| axis | 任意 | 0:行を削除 1: 列を削除 |
| inplace | 任意 | True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 |
drop()で列No.、Change、Volume(Changeの数値が格納されている)を削除します。その際に引数inplaceにはTrueを指定して、実行結果をDataFrameに保存します。そして最初の5行を表示して、列が削除されていることを確認してみましょう。
1 2 | df_stock.drop(['No.','Change', 'Volume'], axis=1, inplace=True) df_stock.head() |
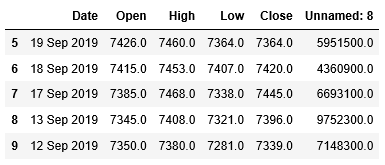
削除した列が消えています。
そして、Volumeが格納されている列「Unnamed: 8」に正しい列名を付けましょう。DataFrameの列名を変更するにはrename ()を利用します。次のように記述します。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| columns | 必須 | 列名変更対象の列名。 辞書型で {変更前:変更後} というように渡す。 |
| inplace | 任意 | True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 |
rename ()で列「Unnamed: 8」の名称を「Volume」に変更します。引数inplaceにはTrueを指定し、最初の5行を表示してみます。
1 2 | df_stock.rename(columns={'Unnamed: 8': 'Volume'}, inplace=True) df_stock.head() |
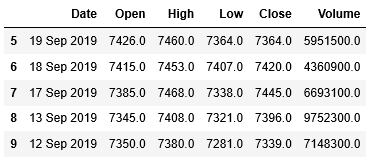
列名が「Unnamed: 8」から「Volume」に変更されています。
日付型インデックスの設定
次に2つ目の問題である「列Dateに格納されている日付が、1 Apr 2019のように文字列になっていて、時系列にグラフを表示できない。」に対応していきます。
ここでは文字列を日付型に変換するdatetime. strptime()を使います。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| 文字列 | 必須 | 日付型に変換したい文字列 |
| 日付書式 | 必須 | 文字列の書式を次の記号で指定(文字列がどのような書式で書かれているかを指定) %b:月名の短縮形Aprなど %d:0埋めした10進数の日にち 01、02など %Y:西暦4桁の10進表記 2019、2020など |
まずはdatetimeをインポートします。
1 | from datetime import datetime as dt |
次にstrptime()を元に列Dateに格納されている日付を示した文字列を日付型に変換し、元のDataFrameに対して列Date2を追加して日付型の値を格納します。
列Dateに格納されている日付が、1 Apr 2019の書式ですので、strptime()の引数には、"%d %b %Y"を指定しています。
1 | df_stock["Date2"] = [dt.strptime(i, "%d %b %Y") for i in df_stock["Date"]] |
また[dt.strptime(i, "%b %d, %Y") for i in data[0]["Date"]]の箇所では、リスト内包表記という方法を用いています。
data[0]["Date"]に格納されている値(日付を示した文字列)をfor文で1行目から順に読み込んで変数iに格納し、その値がstrptime()で日付型に変換しています。
その結果は、全体が[ ]で囲われていますのでリスト型となり、リストの中には、全ての行の文字列が日付型に変換された結果が格納されています。
まずは列Date2に格納した値を確認してみましょう。
1 | df_stock["Date2"].head() |
1 2 3 4 5 6 | 5 2019-09-19 6 2019-09-18 7 2019-09-17 8 2019-09-13 9 2019-09-12 Name: Date2, dtype: datetime64[ns] |
日付型で値が格納されていることがわかります。変換がうまくいったようです。
そして、df_stock.head()の最初の5行を確認します。
1 | df_stock.head() |
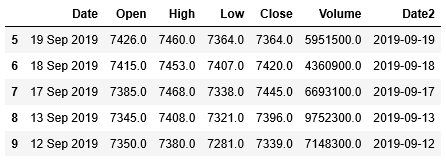
列Date2が追加されていることも確認できました。これで全ての問題は解決されました。
グラフの作成に取り掛かる前に、列Date2をインデックスに指定します。(DataFrameへのインデックスの設定に関する詳しい説明は「Pandas DataFrameへのインデックスの指定と削除、変更」を参照ください。)
インデックスの設定にはset_index()を利用します。また引数inplaceにTrueを指定して、インデックス設定の実行結果をDataFrameに保存します。
1 2 | df_stock.set_index("Date2",inplace=True) df_stock.head() |
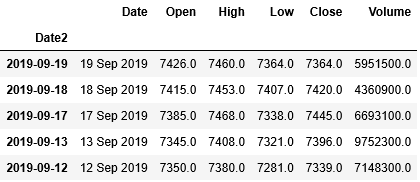
列Date2がインデックスに指定されました。
株価グラフ(チャート)の表示
それでは、グラフを表示してみましょう。DataFrameからグラフを表示するには、plot()を使えば簡単にできます。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| title | 任意 | グラフのタイトル |
| grid | 任意 | 目盛線の表示有無 |
| kind | 任意 | グラフの種類。何も指定しなければ’line’ ‘line’:折れ線グラフ ‘bar’:棒グラフ ‘scatter’:散布図 ‘pie’:円グラフ |
ここでは、株価Closeを縦軸に、日付を横軸にして折れ線グラフを描きます。またタイトルと目盛線も追加しましょう。
1 | df_stock["Close"].plot(title='Toyota Stock Price',grid=True) |
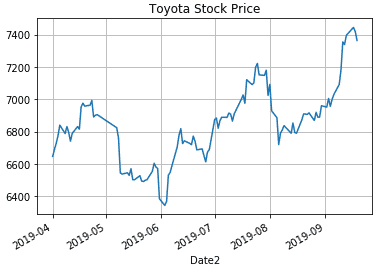
このようにして、Stooqから取得したトヨタ自動車の株価を元にグラフを描画することができました。
WEBスクレイピングで取得した日本の株価情報の保存(CSVファイル)
最後に取得した株価のデータを後から確認できるよう、CSVファイルに保存していきましょう。
DataFrameに保持しているデータをCSVファイルへ書き込むには、to_csvを使います。
CSVファイルへの書き込みに関する詳しい説明は「Pandas Excel、CSVファイルの読み込み、書き込み(出力)」を参照ください。
それでは先ほど読み込んだdf_salesの内容を、ファイル名”Toyota_Stock.csv”で、ディレクトリは指定せずに作業を行っているディレクトリにCSVファイルとして保存します。
1 | df_stock.to_csv("Toyota_Stock.csv") |
保存されたCSVファイルをEXCELで開いてみると、次のように表示されました。
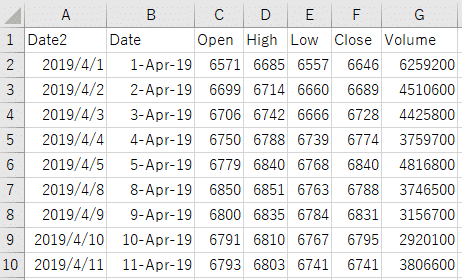
このようにして、Stooqから取得した株価情報を保存することができました。
関連記事です。
Pythonを使ったスクレイピングについての詳細は、こちらをご覧ください。













