
スクレイピングにおけるXPathの使い方を初心者向けに解説した記事です。
XPathとは、基本的な書き方、id・classなど様々な属性やテキストの取得方法、contains関数の使い方など要点を全て解説しています。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
XPathとは
XPathとは、XML形式の文書から特定の部分を指定して取得するための簡易言語です。HTMLにも使うことができます。
XPathはスクレイピングにおいて、HTMLの中から特定の情報を指定し取得するのに利用されます。
HTMLは次のようにタグと言う記号で構成されており、開始タグ、終了タグで囲まれたものを要素といいます。
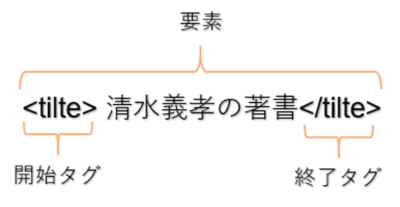
上記の要素はtitleタグに囲まれていますので、titile要素と言います。
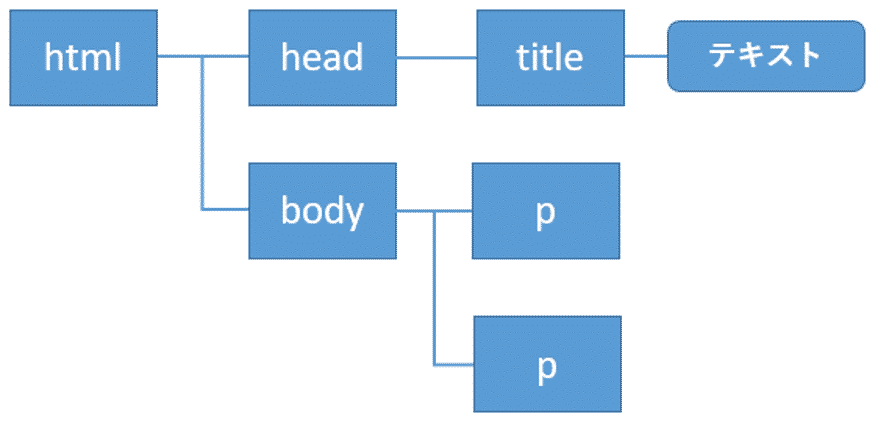
またHTMLは、1つのタグが別のタグで囲われ、というように入れ子の状態で記述されます。これらは階層構造とみなすことができます。
例えば次のHTMLについては、

このような階層構造で表すことができます。
またHTMLのタグの中には、いくつかの属性が含まれることがあります。

これらは属性と属性値からなり、上記のclass属性の属性値は"book"になります。またその横のid="link1"も属性と属性値です。
属性にはid属性のように、HTMLの中で必ず重複しない属性値を持つものと、そうでないものとがあります。
これらの属性も組合せながら、XPathでは要素を指定します。
XPathを利用したPythonでのスクレイピングについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「PythonでWebスクレイピング・クローリングを極めよう!(Scrapy、Selenium編)(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
XPathの基本的な書き方
ここではまずXPathの基本的な書き方を説明していきます。
この基本的な書き方を理解した上で、後から説明する属性の指定方法や階層の前後をたどって要素を指定する方法などの応用的なトピックに進んでいってください。
XPathにおいて、各要素はノードテストと呼ばれます。また各ノードテストを”/”(スラッシュ)で区切り、指定したい要素までの道のりを示したものをロケーションパスと言います。
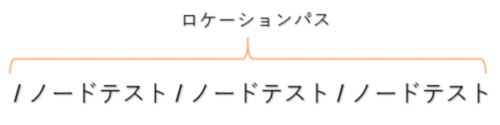
ロケーションパスの書き方
HTMLのルート(html要素)からXPathを書く場合は、/ スラッシュを使って記述します。
例えば、html – head – titleとたどってtitle要素を指定する場合、

次のように書きます。
1 | /html/head/title |
テキストノードの表示: text()
要素に含まれるテキスト(テキストノードと呼びます)を表示したい場合はtext()を使います。ここではtitleのテキストを表示しています。
1 | /html/head/title/text() |
ノードパスを省略: //(ダブルスラッシュ)
パスを短縮して記述する場合は、//(ダブルスラッシュ)で途中のパスを省略して記述することができます。
ここでは、/html/head/ を省略してtitleから記述をしています。
1 | //title/text() |
ここでは、例のHTMLにtitle1つしか含まれませんでしたので、表示された結果は、/html/head/title/text()と同じです。
但し、HTMLの中にtitle要素がいくつか存在する場合に省略して記述すると、該当する要素が複数になります。その場合は複数の要素が表示されます。
1つに絞り込みたい場合、1つに絞り込める親の要素までを短縮して指定してそこから子要素を指定するか、属性と合わせて指定するなどが必要になります。
以降の章では、これらの基本的な書き方を元に、様々な属性の指定の方法や、HTMLの階層構造をたどって要素を指定する方法などの応用的なトピックに進んでいきます。
これらの応用的なトピックを理解するにあたっては、実際にXPathを入力し、実行結果を確認しながら進めていくことが重要です。
XPathの実行を試すことができるサイトをご紹介します。
XPathを試せる検証・テストツール(XPath Tester)
XPath Playground
XPath Playgroundのサイトでは、実際にXPathを記述し、実行結果を確認することができます。
XPathの練習にお勧めのサイトです。この記事を確認しながら、ブラウザでサイトも開けて、ぜひ実行結果を確認しながら読み進めていってください。

XPath Playgroundの画面にいくと、3つの入力欄があります。
- HTMLの入力欄では、XPathの検証に利用するHTMLを入力します。ここに入力されたHTMLを元に、XPathを実行し結果を表示します。
- XPathの入力欄では、実行を試したいXPathを入力してください。ここの入力内容を随時変更し、正しい結果が取得できているかを確認しながら進めていくことになります。
- 結果表示欄には、XPathにより取得された要素が表示されます。
サンプルHTMLコード
この記事で利用したHTMLを記載しておきます。XPath PlaygroundでHTML入力欄に張り付けてください。
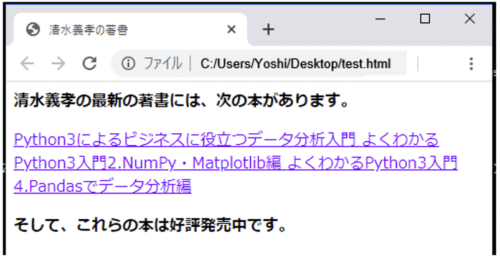
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | <html> <head> <title>清水義孝の著書</title> </head> <body> <p class="title"> <b>清水義孝の最新の著書には、次の本があります。</b> </p> <p class="recent books"> <a class="book" href="https://www.amazon.co.jp/dp/B07TN4D3HG" id="link1"> Python3によるビジネスに役立つデータ分析入門 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07SRLRS4M" id="link2"> よくわかるPython3入門2.NumPy・Matplotlib編 </a> <a class="book" href="http://www.amazon.co.jp/dp/B07T9SZ96B" id="link3"> よくわかるPython3入門4.Pandasでデータ分析編 </a> </p> <p class="end"> <b>そして、これらの本は好評発売中です。</b> </p> </body> </html> |
上記のHTMLは、実際にブラウザで表示すると次のようになります。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
XPathの述語による属性の取得方法
属性の取得: [](スクエアブラケット)と @(アットマーク)
属性は[]と@で指定し、条件に一致した要素を取得ます。
このように取得する要素を、属性などの条件でさらに絞り込むものを述語と呼びます。

ロケーションパス上の任意のノードテストの直後に付けることができます。
属性idが”link1”を持つa要素を指定してみます。
1 | //a[@id="link1"] |
先ほどの例のケースでは、属性を指定しなければ、該当するものが複数存在します。属性を指定することにより、1つに絞り込まれたことがわかります。
1 | //a |
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
任意の属性を取得(ワイルドカード):*(アスタリスク)
特定の属性ではなく任意の属性を指定する場合、アスタリスクを使って指定します。
1 | //a[@*="link1"] |
属性値を表示: @(アットマーク)
属性値を表示したい場合は@(アットマーク)を使います。
1 | //p[@class="recent books"]/a/@href |
.http://www.amazon.co.jp/dp/B07SRLRS4M
.http://www.amazon.co.jp/dp/B07T9SZ96B
複数属性の条件指定: and(かつ)
and(かつ)を使って、class属性に”book”を含み、かつ、href属性に” B07SRLRS4M”を含むa要素を取得してみます。
属性値にある特定の値が含まれているかを確認するには、contains()を使います。
これらのandとcontains()を組み合わせて、次のように記述します。
1 | //a[contains(@class,"book") and contains(@href,"B07SRLRS4M")] |
複数属性の条件指定: or (または)
or (または)でclass属性に”book”を含む、または、href属性に” B07SRLRS4M”を含むa要素のテキストを取得しています。
1 | //a[contains(@class,"book") or contains(@href,"B07SRLRS4M")] |
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
特定の属性を含まない要素の指定: not (~以外)
not (~以外)でhref属性に” B07SRLRS4M”を含まないa要素のテキストを取得しています。
1 | //a[not(contains(@href,"B07SRLRS4M"))] |
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
属性値に含まれる文字列を前方一致で検索: starts-with
前方一致でhref属性にhttp://www.amazon.co.jp/を含むa要素を取得しています。
1 | //a[starts-with(@href,"http://www.amazon.co.jp/")] |
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
属性値に含まれる文字列を後方一致で検索: ends-with
後方一致で検索する場合はends-withを使います。
1 | //a[ends-with(@href,"96B")] |
但し、この関数はXPath version2.0のみ対応しており、chromeなど多くのブラウザではサポートされていません。参考までに掲載しています。
属性値に含まれる文字列をあいまい検索: contains
ある属性に特定の文字列が含まれているかの確認は、先ほど出てきましたcontainsを使います。containsは完全一致ではなく、部分一致でもOKです。
1 | //a[contains(@href,"amazon")] |
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
ここではhref属性に”amazon”を含むa要素を取得しています。
テキストに含まれる文字列の検索: contains(text(), 検索文字列)
containsは、テキストに含まれる文字列も検索可能です。但し、大文字・小文字を区別するので注意が必要です。
1 | //a[contains(text(),"NumPy")] |
“NumPy”を”numpy”と全て小文字にすると、該当するものが無く、結果には何も表示されません。
1 | //a[contains(text(),"numpy")] |
リストの取得方法
ここからはリストの要素の取得方法を確認していきましょう。サンプルのHTMLは以下になります。
サンプルHTMLコード
1 2 3 4 5 6 | <ul class="book"> <li>Python3によるビジネスに役立つデータ分析入門</li> <li>よくわかるPython3入門1.基礎編</li> <li>よくわかるPython3入門2.NumPy・Matplotlib編</li> <li>よくわかるPython3入門4.Pandasでデータ分析編</li> </ul> |
全ての要素を取得
要素liを指定すると、全てのリストを取得できます。
1 | //ul[@class="book"]/li |
<li>よくわかるPython3入門1.基礎編</li>
<li>よくわかるPython3入門2.NumPy・Matplotlib編</li>
<li>よくわかるPython3入門4.Pandasでデータ分析編</li>
n番目の要素の取得: [] (スクウェアブラケット)で数値を囲む
[] (スクウェアブラケット)で数値を囲むと、その順番の要素を取得できます。
例えば、2番目の要素を取得したい場合、li[2]と記述します。
1 | //ul[@class="book"]/li[2] |
n番目の要素の取得: position
positionでもn番目の要素を指定することができます。
タグ[position()=何番目]
例えば2番目の要素を取得する場合は次のように書きます。
1 | //ul[@class="book"]/li[position()=2] |
複数の要素の取得: position & or
1つ目と4つ目を取得したい場合、[]に対してorを使ってもうまくいきません。
1 | //ul[@class="book"]/li[1 or 4] |
<li>よくわかるPython3入門1.基礎編</li>
<li>よくわかるPython3入門2.NumPy・Matplotlib編</li>
<li>よくわかるPython3入門4.Pandasでデータ分析編</li>
1から4番目までの全ての要素が表示されてしまいます。
次のようにposition()とorを使えば1番目と4番目の要素を取得できます。
1 | //ul[@class="book"]/li[position()=1 or position()=4] |
<li>よくわかるPython3入門4.Pandasでデータ分析編</li>
最後の要素を取得: last
最後の要素を取得したい場合、last()を使います。要素の数が変わる可能性があるけれども、必ず最後の要素を取得したいという時に使うと便利です。
1 | //ul[@class="book"]/li[position()=last()] |
最初の要素を取得: position()=1
最初の要素はposition()=1で取得できます。
1 | //ul[@class="book"]/li[position()=1] |
n番目以降・以前の要素を取得: 不等号
position()では>、<、>=、<=などの数学的オペレーションが使えます。 特定の順番以降の要素の取得に使います。 例えば、1番目の要素にはブランクが入っており、でも2番目以降に必要な情報が入っているなどの場合、2番目以降の要素を取得する必要があります。
1 | //ul[@class="book"]/li[position()>1] |
<li>よくわかるPython3入門2.NumPy・Matplotlib編</li>
<li>よくわかるPython3入門4.Pandasでデータ分析編</li>
軸を用いた親・先祖・兄弟・子・子孫要素の指定
軸の使い方
今までの説明では、ルートもしくは途中のパスからから階層を降りて目的の要素を指定していました。

例えば、html – head – titleとたどってtitle要素を指定する場合、次のように書きます。
1 | /html/head/title |
但し、時にはある要素の親の要素やそのさらに親の要素(先祖要素)、子の要素とその子の要素(子孫要素)、同じ親を持つ子要素同士(兄弟要素)などを指定する必要があります。
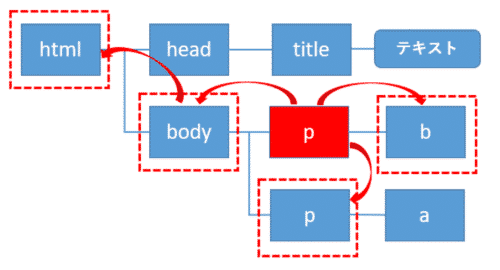
これらはXPathでは軸を使って指定します。XPathでは軸はノードテストの前に「軸::」を付加して指定します。

軸はロケーションパス上の任意のノードテストの前に付けることができます。
軸には次のようなものがあります。
| 軸 | 説明 |
| parent | 親の要素 |
| ancestor | 先祖要素 |
| ancestor-or-self | 自分自身も含めた先祖要素 |
| preceding | 先祖を除く全ての前の要素 |
| preceding-sibling | 前にある全ての兄弟要素 |
| child | 子要素 |
| following | 後ろの全ての要素 |
| following-sibling | 後ろにある兄弟要素 |
| descendant | 後ろの子孫要素 |
| descendant-or-self | 自分自身を含む後ろの子孫要素 |
| self | 自分自身の要素 |
| attribute | 自分自身の属性 |
ここではこれらの軸の指定方法を確認していきます。
HTMLの階層構造
XPathでの軸の指定方法を確認する前に、兄弟要素や先祖要素などの言葉の定義を確認しましょう。
親・子・兄弟要素
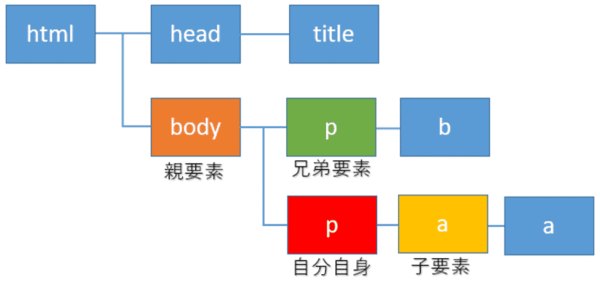
ここでは、自分自身の要素を赤色のp要素とします。そこから1階層上に上がったbody要素(オレンジ色)が親要素になります。
また1つ階層を下に降りたa要素(黄色)が子要素になります。また同じ親要素の子である緑色のp要素は兄弟要素と呼ばれます。
先祖・子孫要素
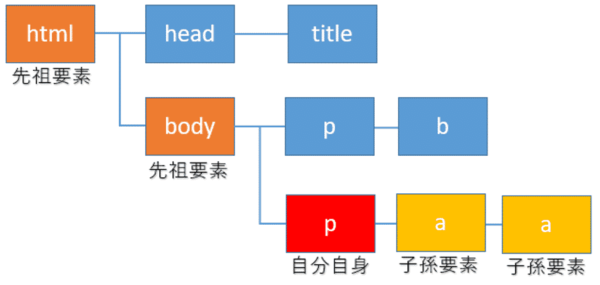
また同様に自分自身の要素を赤色のp要素とします。そこから1階層上に上がったbody要素とさらに階層を上がったその親要素htmlが先祖要素(オレンジ色)になります。
そして、階層を下に順に下がっていった要素は子孫要素(黄色)と言います。
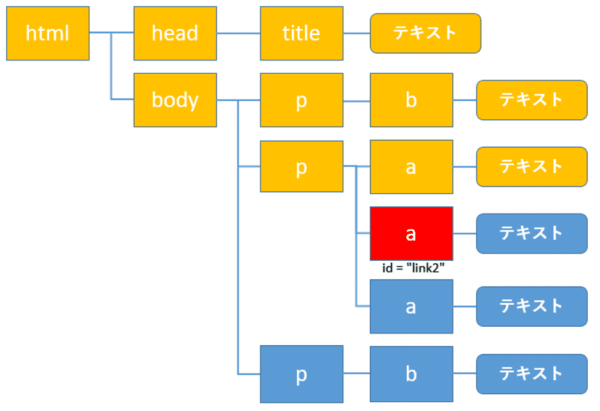
自分自身をid属性が”link2”のa要素(赤色)とすると、前にある要素とは黄色の要素になります。これらの取得方法を1つ1つ確認していきます。
親要素の取得: parent
親の要素(黄色)を取得するには、軸にparent::と入力します。
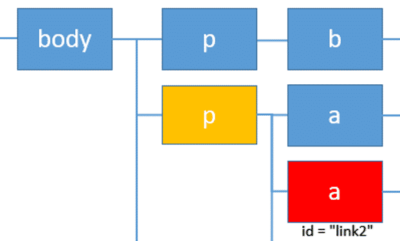
次のように記述します。
1 | //a[@id="link2"]/parent::p |
ここでは、親の要素がpとわかっておりparent::pとしましたが、わからない場合は、node()を使います。結果は同じです。
1 | //a[@id="link2"]/parent::node() |
先祖要素の取得: ancestor
先祖要素(黄色)の取得にはancestorを使います。
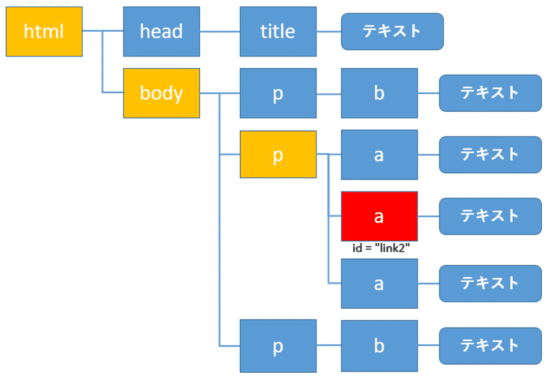
親要素だけでなく、その親とノードをたどっていき、各要素を取得します。
1 | //a[@id="link2"]/ancestor::node() |
<body> <p class="title"> … … (省略)… … </p> </body>
<p class="recent books">… … (省略)… … </p>
ここではid属性が”link2”のa要素の先祖要素であるhtml、body、pが表示されました。
自身も含めた先祖要素の取得: ancestor-or-self
先ほどのancestorには自分自身は含まれません。自身も含めた先祖要素の取得にはancestor-or-selfを使います。
1 | //a[@id="link2"]/ancestor-or-self::node() |
<body> <p class="title"> … … (省略)… … </p> </body>
<p class="recent books">… … (省略)… … </p>
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
すると自身(a要素)も含めて取得できます。
先祖を除く全ての前の要素を取得: preceding
自身の要素の前にある、先祖要素を除いた全ての要素の取得にはprecedingを使います。
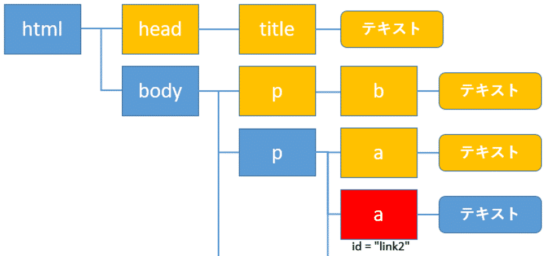
次のように記述します。
1 | //a[@id="link2"]/preceding::node() |
<title> 清水義孝の著書 </title>
清水義孝の著書
<p class="title"> <b> 清水義孝の最新の著書には、次の本があります。 </b> </p>
<b> 清水義孝の最新の著書には、次の本があります。 </b>
清水義孝の最新の著書には、次の本があります。
<a class="book" id="link1" href="https://www.amazon.co.jp/dp/B07TN4D3HG"> Python3によるビジネスに役立つデータ分析入門 </a>
Python3によるビジネスに役立つデータ分析入門
実行すると、テキストも含めた全ての前の要素を取得することができました。但し、先祖要素のhtml、body、p(class属性が"recent books")は除かれています。
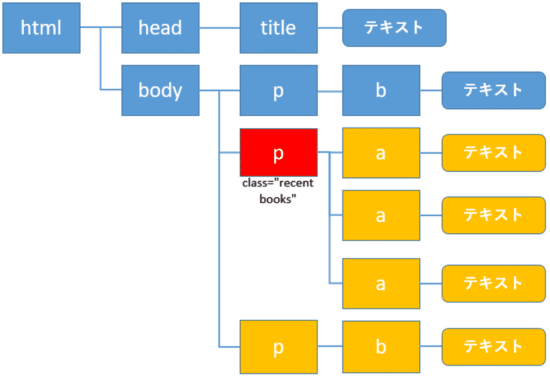
前にある全ての兄弟要素の取得: preceding-sibling
自身より前にある全ての兄弟要素(黄色)の取得にはpreceding-siblingを使います。
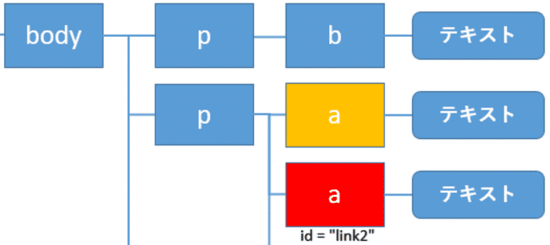
このように書きます。
1 | //a[@id="link2"]/preceding-sibling::node() |
自分自身をclass属性が”recent books”のp要素(赤色)とすると、後ろにある要素とは黄色の要素になります。これらの取得方法も1つ1つ確認していきます。
子要素の取得: child
子要素(黄色)の取得はchildを使います。
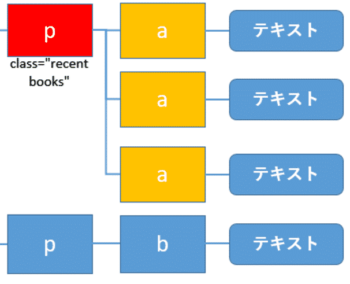
こちらも子要素の要素がわかっている場合、その要素を記述します。ここではa要素を記述しています。
1 | //p[@class="recent books"]/child::a |
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
子要素がわからない場合、child::node()と記述します。
1 | //p[@class="recent books"]/child::node() |
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
後ろの全ての要素を取得: following
ある要素の後続にある全ての要素(黄色)を取得するにはfollowingを使います。
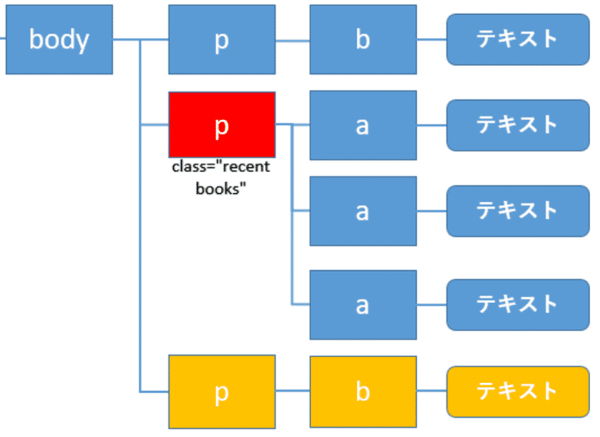
以下のように記述します。
1 | //p[@class="recent books"]/following::node() |
<b> そして、これらの本は好評発売中です。 </b>
そして、これらの本は好評発売中です。
テキストも含めた全ての後ろの要素を取得することができました。
後ろにある兄弟要素を取得: following-sibling
ある要素(ここでは赤色)を起点にして、後ろにある兄弟要素(黄色)を取得するにはfollow-siblingを使います。
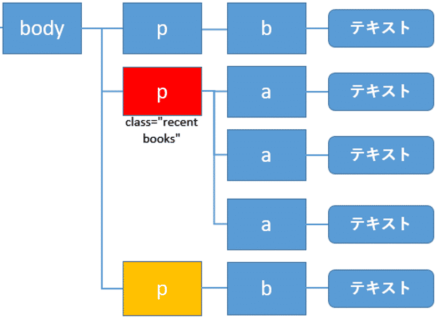
次のようになります。
1 | //p[@class="recent books"]/following-sibling::node() |
ここではbodyの子要素の内、対象の要素以降の兄弟要素を取得しています。
後ろの子孫要素を取得: descendant
ある要素(ここでは赤色)の後続にある全ての子孫要素(黄色)を取得するにはdescendantを使います。
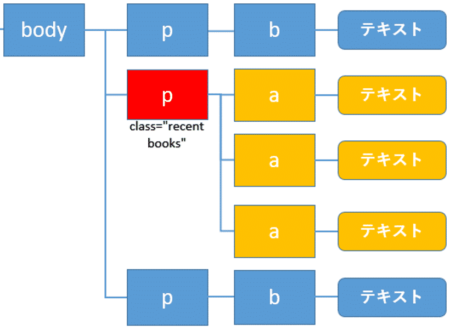
以下のようになります。
1 | //p[@class="recent books"]/descendant::node() |
Python3によるビジネスに役立つデータ分析入門
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
よくわかるPython3入門2.NumPy・Matplotlib編
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
よくわかるPython3入門4.Pandasでデータ分析編
自身を含む後ろの子孫要素を取得: descendant-or-self
先ほどのdescendantには自分自身は含まれません。自身も含めた子孫要素の取得にはdescendant-or-selfを使います。
1 | //p[@class="recent books"]/descendant-or-self::node() |
<a class="book" id="link1" href="https://www.amazon.co.jp/dp/B07TN4D3HG"> Python3によるビジネスに役立つデータ分析入門 </a>
Python3によるビジネスに役立つデータ分析入門
<a class="book" id="link2" href="http://www.amazon.co.jp/dp/B07SRLRS4M"> よくわかるPython3入門2.NumPy・Matplotlib編 </a>
よくわかるPython3入門2.NumPy・Matplotlib編
<a class="book" id="link3" href="http://www.amazon.co.jp/dp/B07T9SZ96B"> よくわかるPython3入門4.Pandasでデータ分析編 </a>
よくわかるPython3入門4.Pandasでデータ分析編
出力結果の最初に自分自身(class属性が"recent books"のp要素)が表示されているのがわかります。
自身の要素を取得: self
自分自身の要素を取得するにはselfを使います。
1 | //a[@id="link2"]/self::node() |
通常は、これらは省略されて//a[@id="link2"]と記述されます。
属性の取得: attribute
自分自身の要素の属性を取得するにはattributeを使います。
1 | //a[@id="link2"]/attribute::node() |
link2
book












