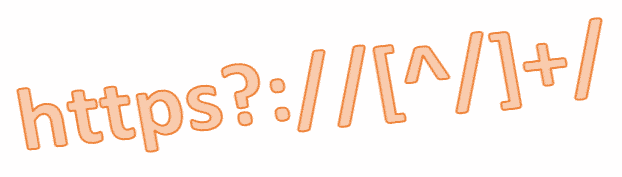
正規表現とは、文字列をあるパターン化された記号で表現する記述方法で、指定したパターンに当てはまる文字列を検索や置換するのに利用します。
正規表現は様々な利用方法がありますが、例えば、次のような事に使うことができます。
- 顧客の住所や電話番号の一覧から、特定の住所、郵便番号や電話番号などを抜き出したい。もしくは、正しい形式になっているかバリデーション(チェック)したい。
- 大量の文章の中から特定の文字列を検索し、別の文字列に置換したい。
- WEBスクレイピングで取得したWEBページの情報の中から、特定の情報を抽出したい。
この記事では、Pythonにおける正規表現の使い方について、初心者でも理解しやすいように、丁寧に解説していきたいと思います。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
正規表現の書き方と使い方
正規表現は、文字列をあるパターン化された記号で表現する記述方法で、指定したパターンに当てはまる文字列を検索や置換するのに利用します。
例えば、あるURL”http://www.amazon.co.jp/dp/B07T9TCPZX”から、ホスト名にあたる” http://www.amazon.co.jp/”までを抽出する正規表現は、次のように記述します。
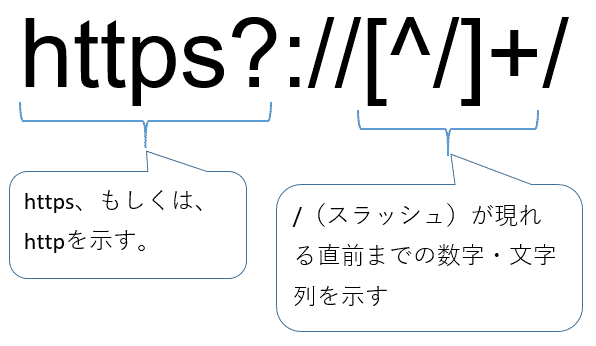
※突然、難しそうな表現が出てきましたが、後で1つ1つ丁寧に解説していきますので、ご安心ください。
これをPythonのコードでは次のように記述します。
|
1 2 3 4 5 |
import re URL = "http://www.amazon.co.jp/dp/B07T9TCPZX" pattern = "https?://[^/]+/" res = re.match(pattern, URL) print(res.group()) |
最初の1行では、Pythonの正規表現のモジュールreをインポートします。
次にホスト名を抽出するURLを、変数URLに格納しています。
そして、正規表現のパターンを記述し、変数patternに格納します。正規表現については、後で詳しく説明いたします。
そして、match関数に変数patternとURLを渡し、実行結果を変数resに格納しています。
正規表現の関数はいくつかありますが、ここでは先頭からパターンに一致しているかチェックするmatch関数を使っています。正規表現で使う関数についても、別途説明いたします。
最後に実行結果を格納した変数resの中身をprintで表示しています。
そして表示された結果が以下になります。URLの内、ホスト名までが抽出されていることがわかります。
実行結果は、パターンに一致するものがあればmatchオブジェクトというもので返ってきます。ここでは、matchオブジェクトのメソッドの1つであるgroupで、マッチした文字列を表示しました。
matchオブジェクトのメソッドには、次のようなものがあります。
| メソッド | 説明 |
| group() | マッチした文字列を取得する。 |
| span() | マッチした文字列の開始、終了位置を取得する。 |
| start() | マッチした文字列の開始位置を取得する。 |
| end() | マッチした文字列の終了位置を取得する。 |
※開始位置は、1文字目は0から始まります。
これらが正規表現を使ってパターンに一致する文字列を抽出する一連の処理になります。
以降の章では、
- 正規表現で使う関数の種類と使い方
- 正規表現におけるパターンの記述方法
を解説していきたいと思います。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
正規表現で使う関数の種類と使い方(文字列の抽出と置換)
正規表現で使う関数には、次のものがあります。
| 関数 | 説明 |
| match | 先頭の文字列からパターンに一致するものを検索する。 |
| search | 先頭に限らずパターンに一致するものがあるかを確認する。 ※但し、複数一致しても1つ目だけを返す。 |
| findall | パターンに一致するものを全てリストで返す。 ※位置情報(開始、終了)は取得不可。 |
| finditer | パターンに一致するものを全てmatchオブジェクトで取得することができる。 ※位置情報(開始、終了)も取得可。 |
| fullmatch | 文字列全体が一致しているかを確認する。 |
| sub | パターンに一致した文字列を別の文字列に置き換える(置換) |
ここでは、それぞれの関数について順に解説していきましょう。
match: 先頭の文字列からパターンに一致するものを検索
match関数は、先頭の文字列からパターンに一致するものを検索する際に利用し、次のように記述します。
一致するものがあった場合、matchオブジェクトを返します。また一致するものが無かった場合、Noneが返ってきます。
注意点としては、あくまでも先頭の文字列から検索しますので、文字列の途中に一致するものがあっても、一致したとはみなされません。
まず簡単な正規表現を使っていくつかの例を確認していきましょう。
正規表現では、.(ドット)は任意の1文字を示します。ここでは、正規表現のパターンとして”x.y”(xとyの間に任意の1文字がある)が、ある文字列の先頭に含まれているかチェックしてみましょう。
match関数に対して、正規表現のパターン”x.y”と、文字列”xyz”を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 |
res = re.match("x.z","xyz") print(res) |
一致した結果として、matchオブジェクトの内容が表示されました。spanでは一致した文字列の範囲(開始位置、終了位置)が、matchには一致した文字列が表示されています。
今度は、文字列”vwxyz”を渡してみましょう。
|
1 2 |
res = re.match("x.z","vwxyz") print(res) |
結果は一致せず、Noneが表示されました。
このようにmatch関数は、あくまでも先頭の文字列から検索しますので、文字列の途中に一致するものがあっても、一致したとはみなされません。
search: 先頭に限らずパターンに一致するものを検索
search関数は、先頭に限らずパターンに一致するものがあるかを検索します。但し、一致したものが複数あっても、1つ目だけを返します。
search関数もmatch関数と同様に、一致するものがあった場合matchオブジェクトを返します。また一致するものが無かった場合、Noneが返ってきます。
まずいくつかの例を確認していきましょう。
search関数に対して、正規表現のパターン”x.y” (xとyの間に任意の1文字がある)と、文字列”vwxyz”を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 |
res = re.search("x.z", "vwxyz") print(res) |
search関数では文字列の途中でも一致するものがあれば一致したとみなされます。一致した結果として、matchオブジェクトの内容が表示されました。
今度は、文字列"vwxyz vwxyz"を渡してみましょう。一致する箇所が2つ含まれているようです。
|
1 2 |
res = re.search("x.z", "vwxyz vwxyz") print(res) |
一致した結果としてmatchオブジェクトが返ってきました。但し、一致した箇所としてspanには(2,5)と表示されています。
つまり、search関数では、2つ一致するものがあっても、返ってくるのは最初のものだけになります。複数取得する場合、次のfindall関数を使うことになります。
findall: パターンに一致するものを全てリストで返す
findall関数は、パターンに一致するものを全てリストで返します。
但し、返ってくるのはリストになりますので、マッチオブジェクトのように一致した位置の情報までは取得できません。一致した位置の情報も必要な場合、finditer関数を使うことになります。
例を確認していきましょう。
findall関数に対して、正規表現のパターン”x.y” (xとyの間に任意の1文字がある)と、文字列"vwxyz vwxyz xaz xbz"を引数として渡し、返ってきたリストの内容をprintで表示します。
|
1 2 |
res = re.findall("x.z", "vwxyz vwxyz xaz xbz") print(res) |
パターンに一致した全てのものがリストで表示されました。
finditer: パターンに一致するものを全てmatchオブジェクトで取得する
finditer関数は、パターンに一致するものを全てイテレータというもので返します。その要素はmatchオブジェクトになりますので、一致した文字列だけでなく、開始位置、終了位置などmatchオブジェクトの内容を表示することができます。
一致した位置の情報も必要な場合、finditer関数を使いましょう。
例を確認していきましょう。
finditer関数に対して、正規表現のパターン”x.y” (xとyの間に任意の1文字がある)と、文字列"vwxyz vwxyz xaz xbz"を引数として渡し、返ってきたイテレータの内容をfor文を使ってprintで表示します。
|
1 2 3 |
res = re.finditer("x.z", "vwxyz vwxyz xaz xbz") for s in res: print(s) |
<_sre.SRE_Match object; span=(8, 11), match='xyz'>
<_sre.SRE_Match object; span=(12, 15), match='xaz'>
<_sre.SRE_Match object; span=(16, 19), match='xbz'>
パターンに一致した全てのものについて、matchオブジェクトが表示されました。
fullmatch: 文字列全体が一致しているかを確認(完全一致)
fullmatch関数は、文字列の一部では無く、全体がパターンに完全一致しているかを確認するのに利用します。
完全一致するものがあった場合matchオブジェクトを返します。また完全一致するものが無かった場合、Noneが返ってきます。
まずいくつかの例を確認していきましょう。
fullmatch関数に対して、正規表現のパターン”x.y” (xとyの間に任意の1文字がある)と、文字列”vwxyz”を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 |
res = re.fullmatch("x.z","vwxyz") print(res) |
文字列“vwxyz”の中には、部分的に”x.z”に一致する”xyz”が含まれますが、文字列全体としては完全一致しませんので、Noneが返ってきます。
今度は、文字列"xyz "を渡してみましょう。
|
1 2 |
res = re.fullmatch("x.z","xyz") print(res) |
完全一致した結果としてmatchオブジェクトが返ってきました。このようにfullmatchでは、文字列全体がパターンに完全一致する場合のみ、matchオブジェクトが返ってきます。
sub: パターンに一致した文字列を別の文字列に置き換え(置換)
今まではパターンに一致するものを検索していましたが、今度は一致するものを別の文字列に置き換える関数を紹介します。sub関数は、パターンに一致している箇所を置換後の文字列に置き換えます。
一致するものがあった場合、置換処理をした後の文字列が返ってきます。
sub関数に対して、正規表現のパターン”x.y” (xとyの間に任意の1文字がある)と、置換後の文字列”abc”、文字列”vwxyz”を引数として渡し、返ってきた置換処理後の内容をprintで表示します。
|
1 2 |
res = re.sub("x.z","abc", "vwxyz") print(res) |
文字列“vwxyz”の内、パターンに一致した”xyz”が”abc”に置き換えられているのがわかります。
正規表現のパターンを表す記号一覧と記述方法
次に正規表現におけるパターンの記号一覧と記述方法を確認していきましょう。これらは、いくつかの分類に分けることができます。
文字列の先頭・末尾を指定する記号一覧
これらの記号は、先頭から、もしくは、末尾から指定したパターンに一致するかを指定します。
| 記号 | 説明 |
| ^ | 文字列の先頭からパターンに一致するかを判定 |
| $ | 文字列の末尾からパターンに一致するかを判定 |
繰り返し回数を指定する記号一覧
これらの記号は、直前の指定された文字列が繰り返し現れる回数を指定します。
| 記号 | 説明 |
| ? | 0回もしくは1回 |
| * | 0回以上 |
| + | 1回以上 |
| {m} | m回 |
| {m,} | m回以上 |
| {m,n} | m回以上、n回まで |
グループ化単位で繰り返し回数を指定する記号一覧
これらの表記は、複数の文字列をグルーピングするのに利用します。そして、繰り返しを指定する記号と合わせて、グルーピングされた塊で指定された回数出現するかを判定するのに使われます。
| 記号 | 説明 |
| ( ) | ( )で囲われた文字列をグルーピングし、パターンに一致するかを判定 |
集合(否定を含む)を指定する記号一覧
正規表現では、[]を使って「全てのアルファベット」など、特定のものの集まりを指定することもできます。またその集合以外を示す場合は、^を使って表現します。次の表に1つの例を挙げます。
| 記号 | 説明 |
| [0-9] | 全ての数字 |
| [a-zA-Z] | 全てのアルファベット |
| [a-zA-Z0-9] | 全てのアルファベットと数字 |
| [^a-zA-Z0-9] | 全てのアルファベットと数字以外 集合に^(ハット)を付けると、集合の条件の否定となり、集合の条件を満たさない場合、一致となります。 |
ORを指定する記号一覧
正規表現では、aかbのいずれかを指定するには、|(縦棒)を使って指定します。また[ ]を使っても指定することもできます。
| 記号 | 説明 |
| | | 例 a|b : a or b(aかbのいずれか) |
| [ ] | 例 [ab] : a or b(aかbのいずれか) |
特殊シーケンス一覧(円マーク・バックスラッシュを用いた記号)
正規表現では、よく使われるパターンについては、特殊シーケンスと呼ばれる円マーク・バックスラッシュを使った簡易的な表現で置き換えることができます。
| 記号 | 説明 |
| \d | 全ての数字 [0-9]と同じ |
| \D | 全ての数字以外 [^0-9]と同じ |
| \w | 全ての英数字と_(アンダーバー) [a-zA-Z0-9_]と同じ |
| \W | 全ての英数字と_(アンダーバー)以外 [^a-zA-Z0-9_]と同じ |
| \s | 空白 |
| \S | 空白以外 |
| \A | 文字列の先頭 ^と同じ |
| \Z | 文字列の末尾 $と同じ |
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
正規表現のパターンをコンパイルする方法
正規表現ではパターンをコンパイルすることによって、同じパターンを効率的に繰り返し利用することができます。
コンパイルにはcompile()を使い、以下のように記述します。
res = pattern.match(検索対象の文字列)
パターンをコンパイルした結果を、変数patternに格納しています。そして、変数patternを元に、match()で検索対象の文字列に対して、パターンに一致するか否かを判定しています。ここでは関数にmatch()を使いましたが、別の関数でも同様です。
一度パターンをコンパイルすることで、次のコードの検索対象の文字列や関数を変更しながら、同じパターンを使いまわすことができます。
compile()に対して、正規表現のパターン”xy+”を引数として渡し、返ってきた値を変数patternに格納します。 変数patternを元に、match()に対して、文字列”xyyyyyy”を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 3 |
pattern = re.compile("xy+") res = pattern.match("xyyyyyy") print(res) |
次回、同じパターンで別の文字列を検索する場合、次のように記述します。
|
1 2 |
res = pattern.search("abcxyyx") print(res) |
ここでは、一度コンパイルした結果を格納した変数pattはそのまま利用しています。そして検索対象の文字列や関数を変更して、同じパターンで検索しています。
特殊文字をエスケープする記号(\)
"*"や"?"のような特殊な文字を検索する場合、\(バックスラッシュ)を付ける必要があります。
例として、"?"を検索してみましょう。
search関数に対して、正規表現のパターン"\?"と、文字列"xy?"を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 |
res = re.search("\?", "xy?") print(res) |
"\?"はバックスラッシュが付いており、"?"と見なされマッチしました。
貪欲マッチ・非貪欲マッチ
繰り返し回数を指定する記号 ? (0回もしくは1回)、*(0回以上)、+(1回以上)については、デフォルトでは貪欲マッチと呼ばれる、できるだけ長いテキストにマッチするよう検索されます。
例えば次のようなケースでは、マッチする文字列として次のようなものが考えられます。
- <html>
- <html><head> など
- <html><head>…</body></html>
但し、デフォルトでは、できるだけ長いテキストである3. にマッチします。ただ、正規表現を使う中で1.の一番短いテキストにマッチして欲しいケースが多々あります。
その場合、??、*?、+?と、各記号の後に?を付けることで、できるだけ短いテキストにマッチさせることができます。
search関数に対して、正規表現のパターン”<.*>”と、文字列”<html><head></head><body></body></html>”を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 3 |
text = "<html><head></head><body></body></html>" res = re.search("<.*>",text) print(res) |
デフォルトでは、できるだけ長い文字列にマッチしようとするので、ここでは’<html><head></head><body></body></html>’がマッチしたようです。
今度は、できるだけ短いテキストにマッチするよう、パターンに"<.*?>"を渡してみます。
|
1 2 |
res = re.search("<.*?>",text) print(res) |
すると先ほどとは異なり、’<html>’がマッチしたようです。このように、正規表現の各記号の後に?を付けることで、できるだけ短いテキストにマッチさせることができます。
フラグ引数
正規表現の関数やcomplie()ではフラグ引数を渡すことによって、マッチする条件を詳細にコントロールできるものがあります。
例えば、search()では次のように記述します。他の正規表現の関数も同様です。
またcompile()では、以下のように記述します。
1.大文字・小文字を区別しないマッチング(re.IGNORECASE)
正規表現の関数に対して、フラグ引数re.IGNORECAEを渡すことにより、大文字・小文字を区別しないマッチングを行ことができます。
search関数に対して、正規表現のパターン"[a-z]+"と、文字列"xyzXYZ"を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 |
res = re.search("[a-z]+", "xyzXYZ") print(res) |
パターン"[a-z]+"として小文字だけを指定しましたので、ここでは小文字だけがマッチしたようです。
今度は、フラグ引数に大文字・小文字を区別しないre.IGNORECAEを渡します。
|
1 2 |
res = re.search("[a-z]+", "xyzXYZ", flags=re.IGNORECASE) print(res) |
ここでは'xyzXYZ'と大文字も含めてマッチしたようです。
2. 各行の先頭(行頭)・末尾(行末)にマッチング(re.MULTILINE)
検索対象の文字列が複数行に渡って記述されている場合、通常、パターン'^' は文字列の先頭にしかマッチしませんが、フラグ引数にre.MULTILINEを渡すことで、各行の先頭(行頭)にもマッチさせることができます。
同様に、パターン'$'は文字列の末尾にしかマッチしませんが、フラグ引数にre.MULTILINEを渡すことで、各行の末尾(行末)にもマッチさせることができます。
findall関数に対して、正規表現のパターン"^[a-z]+"と、複数行に渡る文字列を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 3 4 5 |
text = """abc, 789, RST def, 456, UVW hij, 789, XYZ""" res = re.findall("^[a-z]+", text) print(res) |
パターン"^[a-z]+"として文字列の先頭を指定しましたので、ここでは先頭の’abc’だけがマッチしたようです。
今度は、各行の先頭にもそれぞれマッチするよう、フラグ引数にre.MULTILINEを渡します。
|
1 2 |
res = re.findall("^[a-z]+", text, flags=re.MULTILINE) print(res) |
ここでは各行の先頭(行頭)とマッチしました。
パターンを視覚的に分割し、コメントを付加できる(re.VERBOSE)
正規表現のパターンが長くなった場合、コメントを付けて、わかりやすくする必要があります。
そのような場合に、complie()の引数としてre.VERBOSEを付けることにより、複数行に渡って記述したパターンの間にコメントを挿入することができます。
例えば、正規表現のパターン”[0-9]{4}\/[0-9]{1,2}\/[0-9]{1,2}”を使って、検索対象の文字列から日付(yyyy/mm/dd)を抽出するケースを考えます。
このような長文のパターンについては、"""(ダブルクォーテーションを3つ)や'''(シングルクォーテーションを3つ)で囲うことにより、複数行に渡って記述することができます。
そして、 これらの年、月、日などの論理的な区切り毎に#(ハッシュ)を用いてコメントを挿入していきます。但し、このままでは#(ハッシュ)以降の箇所がコメントと認識されませんので、うまく日付にマッチさせることができません。
そこでcompile()の引数として、re.VERBOSEを渡します。これにより、#年/、#月/、#日がコメントとして扱われ、パターンの中には含まれなくなります。
|
1 2 3 4 5 |
pattern = re.compile(""" [0-9]{4}\/ #年/ [0-9]{1,2}\/ #月/ [0-9]{1,2} #日 """, re.VERBOSE) |
先ほどコンパイルしたパターンを用いて、findall()に検索対象の文字列"The date is 2020/10/23"を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
|
1 2 |
res = pattern.findall("The date is 2020/10/23") print(res) |
日付にマッチし、'2020/10/23'が返ってきました。パターンの文字列に含まれる、#年/、#月/、#日の箇所は正規表現のパターンには含まれず、コメントとして扱われていることがわかります。
パターンをグループ化し名前を付けて参照する方法
正規表現のパターンはグループ化し、グループ毎に名前を付けて、それぞれにマッチしたものを名前で参照することができます。
グループ化は、パターンのグルーピングしたい単位に、(?P<name>...) を付けていきます。<name>のnameにグループの名前を記述し、... の箇所にグループに含まれるパターンを記述します。
マッチしたものを参照するには、matchオブジェクトのメソッドgroup()に対して、先ほど付けたグループの名前nameを引数として渡します。
ここでも例として、正規表現のパターン”[0-9]{4}\/[0-9]{1,2}\/[0-9]{1,2}”を使って、検索対象の文字列から日付(yyyy/mm/dd)を抽出するケースを考えます。そして、 これらの年、月、日などの論理的な区切り毎に(?P<name>...)を用いてグループ化していきます。
例えば、年にマッチするパターンは”[0-9]{4}”になりますので、(?P<name>...)のnameには”year”を、…の箇所には”[0-9]{4}”を挿入します。またグループに関係の無い” \/”は、(?P<name>...)の外に記述します。
|
1 2 3 4 5 |
pattern = re.compile(""" (?P<year>[0-9]{4})\/ #年/ (?P<month>[0-9]{1,2})\/ #月/ (?P<date>[0-9]{1,2}) #日 """, re.VERBOSE) |
先ほどコンパイルしたパターンを用いて、findall()に検索対象の文字列"The date is 2020/10/23"を引数として渡し、返ってきたmatchオブジェクトの内容をprintで表示します。
その際にgoup()に対して引数”year”、”month”、”date”を渡します。
|
1 2 3 4 |
res = pattern.findall("The date is 2020/10/23") print(res.group("year")) print(res.group("month")) print(res.group("date")) |
10
23
すると、年、月、日のパターンにマッチした値がそれぞれ表示されました。このようにして正規表現のパターンをグループ化し、マッチした箇所をグループ毎に参照することができます。
正規表現を使ったバリデーション用の関数(URLの形式チェック)
正規表現を使った例として、引数で渡された値が正しいか否かをバリデーション(チェック)する関数を作ってみましょう。
ここでは、引数に渡されたURLが正しい形式であるか否かをチェックする関数を作成してみます。URLの形式としては、文字列が"http://"、もしくは"https://"で始まるかをチェックするとします。
コーディングの例は次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 |
#バリデーションの例 def validate_url(url): #URLのチェック URL_PTN = re.compile(r"^(http|https)://") res = URL_PTN.match(url) #正しい場合、urlを返す if res: return url #正しくない場合、例外を発生させる else: raise ValueError("This is not URL: {}".format(url)) |
正規表現のパターン"^(http|https)://"で、先頭が"http://"、もしくは"https://"のいずれかから始まるかをチェックしています。
そしてマッチした場合はurlを返し、マッチしなかった場合はraise ValueError()で例外を発生させています。
このようにして作成したバリデーション用の関数にURL"https://www.google.co.jp/"を渡すと、
|
1 |
validate_url("https://www.google.co.jp/") |
パターンに一致するので、URLが返ってきました。
今度はバリデーション用の関数に"ftp://public.ftp-servers.example.com/"を渡します。
|
1 |
validate_url("ftp://public.ftp-servers.example.com/") |

この場合は"ftp://"から始まりURLではないので、ValueErrorの例外が発生しました。
このようにして正規表現を用いて、特定のパターンに一致する・しないのバリデーションを行う関数を作成することができました。
関連記事です。
Pythonに関する重要なトピック全般について学んでいきたいと考えておられる方には、次のリンクをお勧めします。











