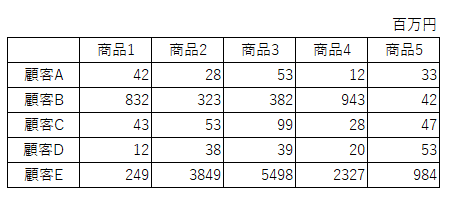
ピボットテーブルは、データの集計や分析において、大変重要なツールになります。ピボットテーブルでは、縦軸と横軸、集計値を選択し、クロステーブルで集計結果をすることにより、様々な角度からデータを確認することができます。
上のピボットテーブルでは、縦軸に顧客、横軸に商品、集計値として売上を表示しています。このようにクロステーブルで結果を表示することによって、どの顧客のどの商品が売れているか、売れていないかを視覚的に確認することができます。
この記事では、Pandasにおけるピボットテーブルの作成方法について、確認していきましょう。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
ビボットテーブルの作成方法(pivot_tableの使い方)
PandasのDataFrameにおいて、ピボットテーブルの作成には、pivot_table()を使い、以下のように記述します。
引数valuesには、集計する値が格納された項目を指定します。
また引数indexには行を、columnsには列に表示される項目を指定します。項目が複数ある場合は、listで指定します。
例えば、indexに指定する項目が1つの場合、index = "項目1" と指定し、2つ以上の場合、index = ["項目1", "項目2", …] というようにlistで指定します。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
事例) ピボットテーブルによるクロス集計
事前準備 - CSVファイルの読み込みと結合
それでは実際にピボットテーブルを作成していきます。ここでは売上ヘッダ情報、売上明細情報を元にピボットテーブルを作成し、販売組織、顧客、製品毎の売上を分析する例をみていくことにしましょう。
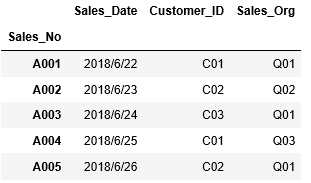
まずは事前準備として、必要なデータをCSVファイルから読み込みます。最初に売上ヘッダ情報が格納されているCSVファイル「T_Sales_Header_pv.csv」をDataFrame df_sales_headerに読み込みます。(※CSVファイルは上のリンクから取得してください。)
1 2 3 4 | import pandas as pd df_sales_header=pd.read_csv("T_Sales_Header_pv.csv", index_col=["Sales_No"]) df_sales_header |
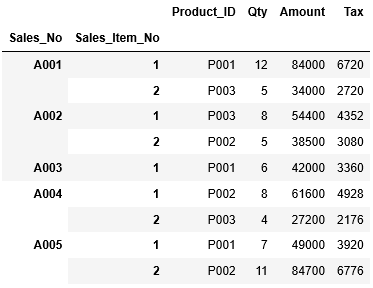
次に売上明細情報が格納されているCSVファイル「T_Sales_Item_pv.csv」をdf_sales_itemに読み込みます。(※CSVファイルは上のリンクから取得してください。)
1 2 3 | df_sales_item=pd.read_csv("T_Sales_Item_pv.csv", index_col=["Sales_No","Sales_Item_No"]) df_sales_item |
そして作成した2つのDataFrameを左外部結合で結合しdf_salesに格納します。左外部結合の詳しい説明は、図解!Pandas DataFrameのmergeによる結合(JOIN)を参照ください。
1 2 3 | df_sales=pd.merge(df_sales_item, df_sales_header, how="left", on="Sales_No") df_sales.head() |
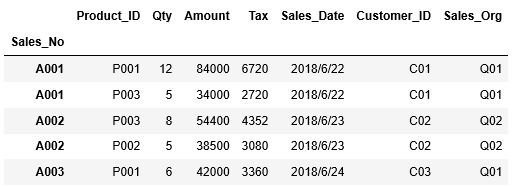
このようにして作成したdf_salesを確認すると、マスタの値がコードで示されており、このままピボットテーブルを作成しても、分析には苦労しそうです。
そこでマスタの値も読み込み、名称を表示するようにしましょう。Customer、Product、Sales Organizationの3つのマスタを順に読み込んでいきます。
まず最初にCSVファイル「M_Customer.csv」を読み込み、df_customerに格納します。(※CSVファイルは上のリンクから取得してください。)
1 2 3 4 | df_customer=pd.read_csv("M_Customer.csv", index_col=["Customer_ID"], encoding="SHIFT-JIS") df_customer.head() |

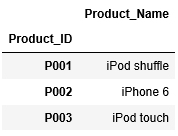
次にCSVファイル「M_Product_pv.csv」を読み込み、df_productに格納します。(※CSVファイルは上のリンクから取得してください。)
1 2 3 4 | df_product=pd.read_csv("M_Product_pv.csv", index_col=["Product_ID"], encoding="SHIFT-JIS") df_product |
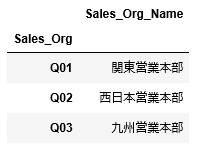
最後にCSVファイル「M_SalesOrganization.csv」を読み込み、df_sales_orgに格納します。(※CSVファイルは上のリンクから取得してください。)
1 2 3 4 | df_sales_org=pd.read_csv("M_SalesOrganization.csv", index_col=["Sales_Org"], encoding="SHIFT-JIS") df_sales_org |
df_salesに対して、これら読み込んだ3つのマスタを左外部結合します。
1 2 3 4 5 6 7 | df_sales = pd.merge(df_sales, df_customer, how="left", on="Customer_ID") df_sales = pd.merge(df_sales, df_product, how="left", on="Product_ID") df_sales = pd.merge(df_sales, df_sales_org, how="left", on="Sales_Org") df_sales.head() |
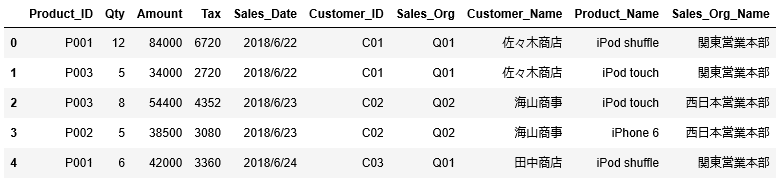
このようにして、df_salesに対してマスタも結合し、名称も表示されるようになりました。
以上で準備が終わり、いよいよピボットテーブルの作成に取り掛かります。
pivot_table()によるピボットテーブルの作成
それでは先ほど準備したDataFrame df_salesを元にピボットテーブルを作成していきます。
まずは顧客、製品毎の売上を見ていきましょう。集計値には”Amount”、行には"Customer_Name"、列には"Product_Name"を指定します。
1 2 | df_sales.pivot_table(values="Amount", index="Customer_Name", columns="Product_Name") |
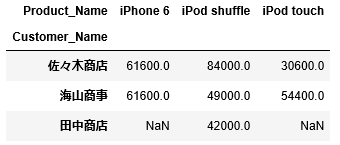
このようにして作成されたピボットテーブルから、顧客、製品毎の売上が確認できます。
例えば、iPod shuffleは佐々木商店によく売れている、海山商事に販売している商品の中ではiPhone 6が売上が高いなどがわかります。
さらに分析軸を増やし、行に"Sales_Org"を追加してみましょう。引数indexにはlistで["Sales_Org_Name","Customer_Name"]を渡します。
1 2 3 | df_sales.pivot_table(values="Amount", index=["Sales_Org_Name","Customer_Name"], columns="Product_Name") |
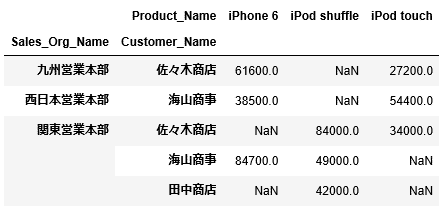
上記のピボットテーブルでは、販売組織、顧客、製品毎の売上が確認できるようになりました。
このようにしてピボットテーブルでは、行や列に項目を増やしたり、集計値を変えてみたりして、様々な切り口からデータを分析することができます。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













