
この記事では、時系列データの集計方法について学んでいきましょう。日々の売上データを月、四半期、年度単位に集計する方法を確認します。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
datatimeによる日付型データの作成
年、月、日などを示した数値を日付型に変換するには、次のdatetimeを利用します。
引数には、year、month、day、hour、minute、secondを指定します。hour、minute、secondは省略することもできます。
まずは日付型のデータを作成します。年、月、日をそれぞれ変数year_1、month_1、day_1に格納します。そしてその変数をdatetimeに渡し、日付型に変換します。
date_1の内容を確認すると、datetime.datetime(2018, 1, 23, 0, 0)と表示され、日付型のデータが格納されていることがわかります。
...: from datetime import datetime...: year_1 = 2018...: month_1 = 1...: day_1 = 23...: hour_1 = 17...: minute_1 = 58...: second_1 = 36...: date_1 = datetime(year_1, month_1, day_1)...: date_1
先ほどの実行結果から変数date_1にはdatetime型で値が格納されていることがわかりますが、変数の型を確認できるtypeを使っても、date_1に日付型の値が格納されていることが確認できます。
先ほどは省略しましたが、今度は、引数に時、分、秒を格納した変数hour_1、minute_1、second_1も渡してみましょう。
...: date_2
次に日付毎の売上を格納したDataFrameを作成し、インデックスに日付型のデータを指定していきます。これらdatetimeで作成した日付型のデータを元に、DataFrameに対して、日付型のインデックスを作成してみます。最初にdatetimeで日付型のデータをいくつかリストに格納し、変数date_listに格納します。日付型インデックス作成には、DatetimeIndexを利用します。
...: datetime(2018, 10, 2),...: datetime(2018, 10, 3),...: datetime(2018, 10, 4),...: datetime(2018, 10, 5)] ...: date_index = pd.DatetimeIndex(date_list)
次に売上を格納したリストを変数sales_listに格納します。
これらsales_list、date_indexを元にDataFrameを作成します。
...: df1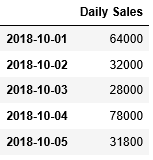
このようにして、日付毎の売上を格納したDataFrameを作成することができました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
日付型インデックスの設定とlocによる期間指定
次にCSVファイルからの読み込み時に日付型インデックスを設定する方法について見ていきましょう。日付型の項目を含んだCSVをread_csvで読み込む際には、インデックスの指定を引数index_colで行い、合わせてparse_datesにTrueを指定します。そうすることにより、index_colで指定された項目は日付型のインデックスとなります。
実際の例として、ある商品の日々の売上が格納されたCSVファイル「T_Daily_Sales.csv」からデータを読み込み、日付型のインデックスを設定してみます。(※CSVファイルは上のリンクから取得してください。)
このCSVファイルから取得した日次売上データには、日付型の列"Sales_Date"、その日の売上を格納した列”Sales_amount”の2つの列があります。
...: parse_dates=True)...: df_daily_sales.head()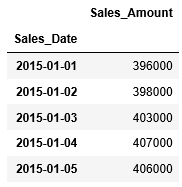
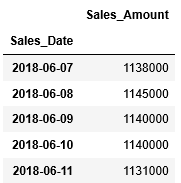
先ほど読み込んだCSVファイルの最後のデータもtailにて確認します。2018/06/11までのデータが格納されているようです。
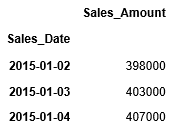
日付毎の売上を格納したDataFrame df_daily_salesからlocを利用して一定期間のデータを抽出してみましょう。ここでは、2015/1/2から2015/1/4までのデータを抽出しています。
resampleによる年・週・月ごとに集計(平均)
次に年・週・月単位の集計を実施していきます。様々な集計単位でデータを集計し直すことにより、傾向を把握することができます。
DataFrameにおいて時系列のデータをある期間でグルーピングし直す場合、resampleを使います。
DataFrameには時系列のデータを格納します。また引数ruleではグルーピングし直す期間を指定します。期間は次のように記号で指定します。
| 記号 | 期間 |
| A | 年 |
| M | 月 |
| Q | 四半期 |
| W | 週 |
このようにresampleを利用して時系列のデータをグルーピングし直し、その結果を元に平均、最大値などを求めていきます。例えば平均を求める場合、以下のようにresampleの後に.mean()を付けて平均を求めます。
最初に、先ほどCSVファイルから取得した日次売上データを元に、年毎の売上の平均を求めてみましょう。resampleへの引数ruleには"A"(年)を渡します。そして年単位でグルーピングしたデータに対してmeanで平均を算出します。その計算結果の小数点以下の数をround()で整数に丸めています。
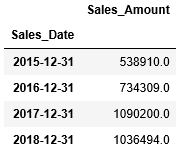
2015年から2017年にかけては売上が増加傾向だったことがわかります。でも2017年から2018年は若干減少しているようです。
月毎の平均を求める場合はresampleへの引数ruleには"M"(月)を渡します。
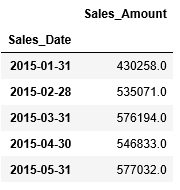
同様に、四半期の平均を求める場合、resampleへの引数ruleには"Q"(四半期)を渡します。
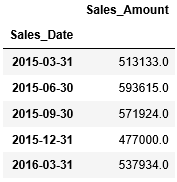
最後に、週の平均を算出する場合、resampleへの引数ruleには"W"(週)を渡します。
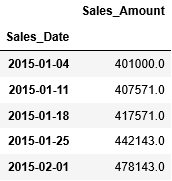
これまで、日次の売上データを元に、年、月、四半期、週毎の平均を求めてきましたが、会社毎に異なる会計年度単位での集計が必要な場合、どのように実現していきましょうか?
特に日本では4月ー3月決算の会社が多く、このように会計年度単位の期間で集計を求められるケースも良くあります。この会計年度単位の集計には、ちょっとしたテクニックが必要になります。これについては、後で解説していきたいと思います。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
resampleによる年・週・月ごとに集計(合計、最大値の取得方法)
一方で、集計方法については、平均以外についても見ていきましょう。次に、合計、最大値の集計の例を確認します。
月の合計をする場合、引数ruleに”M”(月)を指定し、その結果をsumで合計します。
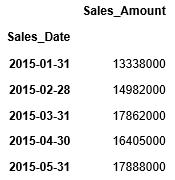
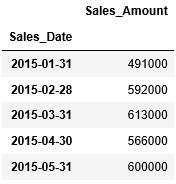
また月の最大値を取得する場合は、maxにて最大値を取得することができます。
shiftによる日付の操作
時系列のデータにおいては、データの時間軸を前や後ろにずらして集計をする必要があるケースが生じます。その場合、shiftを利用します。
DataFrameには時系列のデータを格納し、shiftで時間軸をずらしていきます。引数にはずらす数を指定し、もう1つの引数freqでずらす単位を指定します。freqの指定は任意で、省略すると日単位となります。
freqに指定する記号は、先ほどと同じ次のようなものになります。
| 記号 | 期間 |
| A | 年 |
| M | 月 |
| Q | 四半期 |
| W | 週 |
まずは先ほどの日次売上のデータを再度、確認します。最初の5件を表示してみましょう。
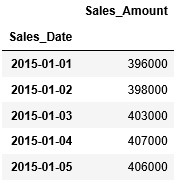
1日前へずらす場合、shiftへ引数に1を渡します。
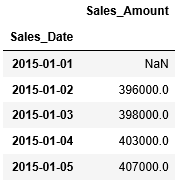
一日後へずらす場合、shftへ引数-1を渡します。

また引数freqで、どの単位で日付をずらすかを指定することができます。"M"を指定すると月単位で日付をずらすことができます。
一ヶ月後へずらす場合は、shiftの引数に-1を指定し、freqへ"M"(月)を指定します。
会計年度の集計
ここまで学習した事の応用事例として、多くの日本企業が採用している4月から3月までを1つの会計年度として、年度毎の売上を集計する例を確認していきましょう。
まずは月単位で日々の売上を集計します。resampleの引数ruleに”M”を指定して月単位にまとめたものをsumで合計し、df_monthly_salesに格納します。そして、df_monthly_salesの最初の15件をheadで確認すると、日付は2015/1/31から始まっています。
...: df_monthly_sales.head(15)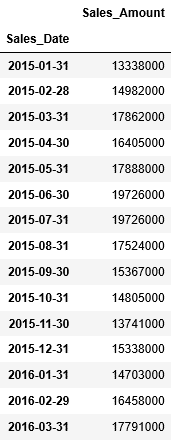
次に月単位で集計したものを3ヶ月後ろへずらしていき、その結果をdf_monthly_sales_shiftに格納します。df_monthly_sales_shiftの最初の15件を確認すると、日付が2014/10/31から始まり、3ケ月後ろへずれていることがわかります。
...: df_monthly_sales_shift.head(15)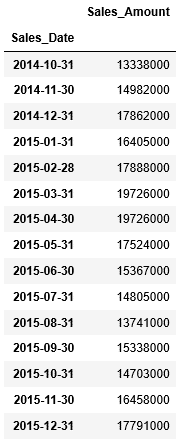
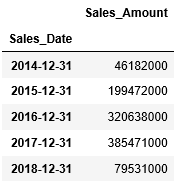
このように3ケ月後ろへシフトされたデータを元にresampleで年間集計します。引数ruleに対して”A”(年)を渡し、sumで合計します。すると、会計年度に基づき集計することができました。
移動平均の算出
最後に移動平均の算出方法について確認していきましょう。移動平均の算出には、日付を固定して、値だけをずらすrollingを利用します。rollingの引数には、何行分ずらすのかを指定します。それでは、ここではrollingで10行、値をずらし、その結果をmeanで平均を取ります。こうすることにより、10日の移動平均を算出することができます。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













