
Pandas(パンダス)には2つの主要なデータ構造があり、Series(シリーズ)が1次元のデータ、DataFrame(データフレーム)が2次元のデータに対応します。
1次元データとは、1つの観測対象に対して、1つの測定値があるデータのことになります。例えば、次のような、あるスーパーでのある日の買い物客毎の購入額は、1次元のデータになります。
| 購入額(円) | 4,500 | 9,000 | 6,800 | 2,800 | 700 |
一方で、2次元データとは、1つの観測対象に対して、2つの測定値があるデータのことになります。例えば、ある会社での広告毎の純利益は、2次元のデータになります。
| 広告費(千円) | 45,000 | 55,000 | 225,000 | 15,000 | 95,000 |
| 純利益(千円) | 5,000 | 6,000 | 17,500 | 12,800 | 8,000 |
1次元のデータを対象に分析する際には、Seriesの知識が必要不可欠になります。またSeriesは1次元のデータを保持しますので、DataFrameの1行や1列の情報もSeriesに対応します。
実務で利用するデータは、Matplotlibの例で出てきた温度とアイスクリームの売上など、2つの軸で表される2次元のデータも多く、DataFrameを利用する機会も多いです。
しかし、SeriesはDataFrameの構成要素となるので、その性質を知っておく事は、DataFrameを理解する上でも、とても重要になります。DataFrameの詳しい説明は、「Pandas DataFrameの基本を徹底解説!」を参照ください。
この記事では、まずはSeriesの基本的な使い方を確認した上で、最後に1次元データの分析事例を確認していきましょう。
SeriesはNumpyの1次元配列に似ていますが、インデックスを使ってデータに名前をつけることができる点が異なります。またそのインデックスを指定して、Seriesに格納したデータを取り出すことができます。
さらに、Seriesは数値だけでなく、文字列など様々なオブジェクトを格納することができます。
Pandasについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用ください。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つデータ分析・可視化入門」(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
PandasにおけるSeriesの作成方法(リスト、ディクショナリ、ndarrayからの作成)
Seriesは、リスト、ディクショナリ、NumPyのndarrayなどから作成することができます。
Seriesは、次のように定義します。
リストからSeriesの作成
まずはリストを元にSeriesを作成してみましょう。
リストlist1に数値「12, 24, 36」を格納し、pd.Seriesの引数dateにlist1を渡します。
...: list1 = [12, 24, 36] ...: pd.Series(data = list1)1 24
2 36
dtype: int64
すると1列目に0, 1, 2、2列目に12, 24, 36、最後に「dtype: int64」と表示されました。
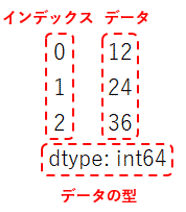
1列目に表示された0, 1, 2という数値がインデックスで、pd.Seriesの引数indexに何も渡さないと、デフォルトでは連番の数値が設定されます。
2列目に表示された12, 24, 36が、先ほど格納したリストlist1の値になります。このようにSeriesではインデックス付きでデータが格納されます。
後ほど説明しますが、データを取り出す際に、このインデックスを指定して取り出すことができます。
また最後に表示された「dtype: int64」は、Seriesに格納されたデータの型になります。
Series作成時にインデックスを指定
先ほどはインデックスを指定しませんでしたが、次はSeries作成時にindexを設定してみましょう。
リストindex1にインデックス["Row1", "Row2", "Row3"]を格納し、pd.Seriesの引数indexにリストindex1を渡します。
...: pd.Series(data = list1, index = index1)Row2 24
Row3 36
dtype: int64
すると次は1行目から順にRow1、Row2、Row3とインデックスが設定されました。
ディクショナリからSeriesの作成
またSeriesは、ディクショナリからも作成することができます。その場合、ディクショナリのキーがインデックスとして設定されます。
...: pd.Series(data = dict1)Row2 22
Row3 33
dtype: int64
NumPy ndarrayからSeriesの作成
さらには、NumPyで作成したndarrayからもSeriesを作成することができます。その場合、インデックスは必要に応じて別途設定する必要があります。
...: arr1 = np.array([11, 22, 33]) ...: pd.Series(data = arr1, index = index1)Row2 22
Row3 33
dtype: int64
様々なデータ型(数値・文字列など)の要素を持ったSeriesの作成
またSeriesには、先ほどの例のように整数だけでなく、文字列など様々なデータ型のオブジェクトを格納することができます。
それでは文字列"apple", "strawberry", "cherry"を格納してみましょう。インデックスは、先ほど定義したリストindex1を利用します。
Row2 strawberry
Row3 cherry
dtype: object
さらに数値だけ、文字列だけというように1種類のデータ型だけではなく、様々なデータ型のオブジェクトを混合して格納することもできます。
それでは文字列"apple", 整数300, ブール(True/False)のTrueを格納してみましょう。インデックスは、先ほど定義したリストindex1を利用します。
Row2 300
Row3 True
dtype: object
Seriesの作成時に名前(カラム名)の追加(引数name)
またSeriesは作成時にデータの列に名前を設定することができます。
リストを元にSeriesを作成します。その時にpd.Seriesの引数nameに対して列名"column name"を渡します。
...: ser1Row2 24
Row3 36
Name: column name, dtype: int64
すると最後に「Name: column name」と列名が表示されました。
Series作成時に付けた名前(カラム名)の変更(rename)
またSeriesはrenameを使って、作成時に付けた列名(カラム名)を変更することができます。
renameに対して変更後の列名"changed column name"を渡します。
Row2 24
Row3 36
Name: changed column name, dtype: int64
すると最後の列名が変更され、「Name: changed column name」と表示されました。
DataFrameの列を抽出しSeriesを作成
DataFrameの一部の列を抽出し、Seriesを作成することもできます。
まずは例として、次のようなDataFrame df1を作成します。
...: index1 = ["Row1", "Row2", "Row3"] ...: columns1 =["Col1", "Col2", "Col3"] ...: df1 = pd.DataFrame(data=list1, index=index1, columns=columns1) ...: df1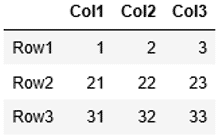
DataFrame df1の列の中から列"Col2"を抽出し、Seriesを作成してみましょう。
DataFrameの1列はSeriesに対応しますので、1つの列をdf1["Col2"]というように抽出するだけでSeriesになります。
....: ser1Row2 22
Row3 32
Name: Col2, dtype: int64
df1の列"Col2"がSeriesとして抽出されました。インデックスも引き継がれています。
SeriesからDataFrameへの変換
参考までにSeriesをDataFrameに変換する方法も紹介します。
DataFrameに対して引数にSeriesを渡すと、Seriesを元にDataFrameが作成されます。DataFrameの詳しい説明は「Pandas DataFrameを徹底解説!」を参照ください。
....: df1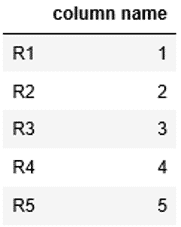
このようにしてSeriesがDataFrameに変換されました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
PandasにおけるSeriesからデータの抽出方法(インデックス・条件指定)
Seriesに格納したデータは、インデックスを指定して値を取得します。
リストを元に作成したSeriesを変数ser1に格納します。Seriesには、先ほどと同様、1行目から順にRow1、Row2、Row3とインデックスが設定されています。
そしてSeriesに対してインデックス”Row2”を指定して2行目の値「2」を取得してみましょう。
...: index1 = ["Row1", "Row2", "Row3"] ...: ser1 = pd.Series(data = list1, index = index1) ...: ser1[“Row2”]
またSeriesへ格納されたデータは、条件を指定して取得することもできます。先ほど定義したser1を使って確認してみましょう。
Seriesに対して条件を指定すると、格納された値と条件を照らし合わせて、結果としてTrue/Falseが返ってきます。
例えばser1に格納された値で2以上のものという条件を指定すると、次のように各値と条件を比較した結果がTrue/Falseとして表示されます。
Row2 True
Row3 True
dtype: bool
SeriesではTrueのデータのみを表示するので、この性質を利用し、次のようにして、条件を満たしたデータを抽出することができます。2以上となるRow2、Row3値が表示されました。
Row3 3
dtype: int64
またSeriesでは、リストの章で学習したスライスを利用してデータを抽出することもできます。0:2と指定することにより、Row1、Row2が抽出されます。
Row2 2
dtype: int64
PandasにおけるSeriesへのデータ(要素)の追加・削除・変更
次にSeriesへデータを追加します。Seriesへのデータの追加は、インデックスを指定して値を代入します。
先ほどのser1に対して、インデックス”Row4”で値4を、インデックス”Row5”で値5を追加してみましょう。次のように記述します。
...: ser1["Row5"] = 5 ...: ser1Row2 2
Row3 3
Row4 4
Row5 5
dtype: int64
今度はSeriesのデータを削除します。削除する場合は、次のようにdropを利用します。引数には削除したい要素のインデックスを渡します。
先ほど追加したインデックス”Row5”の要素を削除します。
...: ser1Row2 2
Row3 3
Row4 4
dtype: int64
インデックス”Row5”の要素が削除され、無くなりました。
またSeriesに格納された要素の変更方法も確認しましょう。値を変更するには、変更したい要素のインデックスを指定して、変更後の値を代入します。ここでは、インデックス”Row3”の値を3から5に変更してみます。
Row2 2
Row3 5
Row4 4
dtype: int64
実行結果から、”Row3”の値が5に変更されていることが確認できました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
PandasにおけるSeriesのインデックスを利用した演算
複数のSeriesがある場合、インデックスが同じものについては、そのまま演算をすることができます。
例えば、2つのSeries”ser2”と”ser3”で同じインデックス”R1”の要素があった場合、ser2 + ser3と足し算をすると、インデックス”R1”同士の要素を足してくれます。
ここでは、Series”ser2”のインデックス”R1”の値は1、一方で、Series”ser3”のインデックス”R1”の値は10なので、ser2 + ser3 = 1 + 10 = 11 となっています。
その他の要素も同様に計算されていることがわかります。
...: list3 = [10, 20, 30, 40, 50] ...: index2 = ["R1", "R2", "R3", "R4", "R5"] ...: ser2 = pd.Series(data = list2, index = index2) ...: ser3 = pd.Series(data = list3, index = index2) ...: ser2 + ser3R2 22
R3 33
R4 44
R5 55
dtype: int64
PandasにおけるSeriesのソート方法(sort_index、sort_values)
Seriesに表示されているデータは、次の方法でソートすることができます。
・インデックスによるソート
・指定した列の値によるソート
また昇順、降順のいずれも指定することができます。
ここでは、次のような商品毎の売上情報を格納するSeries ser1を元に、2つのソート方法を確認していきます。
...: index1 = ["P001","P002","P003","P004"] ...: ser1 = pd.Series(data = list1, index = index1) ...: ser1P002 4000
P003 200
P004 12000
dtype: int64
インデックスによるソート
Seriesにおいてインデックスによるソートは、sort_indexを利用します。
引数ascendingにTrueを指定すると昇順、Falseを指定すると降順にソートされます。何も指定しなければ、Trueの昇順になります。
また引数inplaceは、ソート結果でSeriesを置き換えるか否かを指定します。何も指定しなければ、Falseの置き換えないになります。
それでは、先ほど定義したSeries ser1をインデックスの降順でソートしてみます。引数ascendingにはFalse(降順)を指定します。
P003 200
P002 4000
P001 9000
dtype: int64
インデックスについて、上から”P004”、”P003”、”P002”、”P001”というように降順でソートされていることがわかります。
但し、ここでは引数inplaceに何も指定していなので、Falseの置き換えないになっています。つまり、ソートされた内容でSeries ser1の内容は書き換えられていません。
再度ser1の内容を表示させると、
P002 4000
P003 200
P004 12000
dtype: int64
ソート順は元の状態のままということがわかります。
ソートされた内容でSeries ser1の内容を書き換えたい場合、次のように引数inplaceにTrueを指定しましょう。すると、次回 ser1を表示しても、表示内容はソートされたままになります。
指定した列の値によるソート
Seriesにおいて指定した列の値によるソートは、sort_valuesを用います。引数ascendingにTrueを指定すると昇順、Falseを指定すると降順にソートされます。
Series ser1に格納された内容を元に、昇順にソートします。引数ascendingに何も指定しなければ、昇順になります。
P002 4000
P001 9000
P004 12000
dtype: int64
上から200, 4000, 9000, 12000と昇順に並んでいることがわかります。
関連記事です。
Seiresのソートに関する詳しい解説は「図解!Pandas DataFrameのソート徹底解説(sort_values・index)」を参照ください。Seriesもソートについては一部制限があるものの、ほぼDataFrameと同じです。
PandasにおけるSeriesの結合方法(append、concat)
データを分析する上で、1つのSeriesだけではなく、複数のSeriesを組み合わせて、データを確認していくことが求められる場合があります。その際に必要となるのが、結合の処理です。
ここでは、先ほど作成したSeries ser1に加えて、新たなSeries ser2を作成し、そしてこの2つのSeriesを結合して、Series ser3を作成しながら、結合方法を確認していきます。
Series ser1はこのように作成しました。
...: index1 = ["P001","P002","P003","P004"] ...: ser1 = pd.Series(data = list1, index = index1) ...: ser1P002 4000
P003 200
P004 12000
dtype: int64
またSeries ser2は次のように定義します。
...: index2 = ["P005","P006","P007"] ...: ser2 = pd.Series(data = list2, index = index2) ...: ser2P006 31000
P007 60
dtype: int64
appendでのSeriesの結合
Seriesの結合には、appendを使います。2つのSeriesをそれぞれ、Series1、Series2とすると、以下のように記述します。
引数ignore_indexでは、元のSeriesのインデックスを破棄して新たに振りなおす場合、Trueを、元のインデックスを継承する場合はFalseを指定します。何も指定しないとFalseになります。
ser1とser 2を結合し、ser 3を作成します。ignore_indexには何も指定せず、元のインデックスを継承します。
...: ser3P002 4000
P003 200
P004 12000
P005 1000
P006 31000
P007 60
dtype: int64
ser3の内容を表示すると、このようにser1とser2を合わせたものになっていることがわかります。またインデックスは元のものが引き継がれています。
concatによるSeriesの結合
appendでは無く、concatでも同様にSeries同士を結合することができます。
appendとの違いは、concatはリスト型でSeriesを渡すので、2つ以上のSeriesをまとめて結合することができます。
concatの例としては、先ほどのappendと同様、2つのSeries ser1、ser2を結合し、ser3に格納します。
...: ser3P002 4000
P003 200
P004 12000
P005 1000
P006 31000
P007 60
dtype: int64
ser3の内容を表示すると、appendの時と同じ結果が表示されているのがわかります。
Seriesから統計情報の取得(要素数、最大値、最小値、標準偏差など)
Seriesにあらかじめ用意されているメソッドdescribe()を用いると、Seriesに格納されているデータの件数(要素数)、最大値、最小値、標準偏差などの統計情報を取得することができます。
例として、先ほどser1とser2を結合させて作成したser3の統計情報を表示すると、
mean 8180.000000
std 11065.387476
min 60.000000
25% 600.000000
50% 4000.000000
75% 10500.000000
max 31000.000000
dtype: float64
ser3の統計情報が表示されました。countからデータ件数(要素数)は7、平均値は8180、最大値は31000、最小値は60などが一覧でわかり、データを分析する上で非常に便利です。
主な表示内容をまとめると次のようになります。
| 記号 | 意味 |
| count | データ件数(要素数) |
| mean | 平均値 |
| max | 最大値 |
| min | 最小値 |
| std | 標準偏差 |
| 50%/td> | 中央値 |
これらの統計情報は、必要なものだけを個別に取得することもできます。例えば、最大値を取得したい場合、次のようにmax()を利用すれば、
ser3の最大値だけが表示されました。
Seriesを使ったデータ分析事例
ここではSeriesを使って、あるスーパーマーケットチェーンでのある期間の買い物客毎の購入額を分析してみましょう。
あるスーパーマーケットチェーンの本部に勤めるAさんは、新たな地域Cに新規のスーパーを開店する計画を立てています。その中で新規店の売上の計画を立てる為、客単価の予測を立てる必要があります。
ただ、このスーパーマーケットは、他の地域にはいくつか既存の店舗がありますが、地域Cには初めての出店で、すぐに使えるデータがありません。
そこでAさんは、地域Cの近隣で、既存の店舗が存在する地域A、Bのある期間の買い物客毎の購入額を分析し、そこから地域Cでの客単価を予測することにしました。
まず既存店から情報を収集し、地域毎に情報がまとまった2つのcsvファイル(Sales_Area_A.csv、Sales_Area_B.csv)を入手することができました。それぞれのcsvファイルには、次のように買い物客毎の購入金額(円)が記載されています。
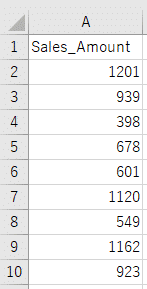
これらの収集した情報は測定値が1つの1次元データになりますので、PandasのSeriesを活用して、分析を進めていきましょう。
CSVファイルの読み込み
それでは最初にCSVファイル「Sales_Area_A.csv」からデータを読み込みます。CSVファイルの読み込みは、pd.read_csvを利用します。
CSVファイルの読み込みについて、詳しい説明をご覧になる場合、こちらのリンク「Pandas Excel、CSVファイルの読み込み、書き込み」から参照ください。
その際に引数として読み込むファイル名「Sales_Area_A.csv」と、squeezeにTrue(Seriesとしてデータを読み込む)を指定します。この読み込んだデータを変数ser_aに格納します。
type()を利用して、変数ser_aのデータ型を確認してみましょう。すると、Seriesと表示され、期待通りにSeries型のデータとして格納されていることがわかりました。
そして次にSeriesを格納した変数ser_aを入力すると、格納されているデータが表示されます。
1 939
2 398
3 678
… … … …
599 590
600 484
601 508
Name: Sales_Amount, Length: 602, dtype: int64
先頭、最後から行数指定でのデータ取得
先ほどの例のように、全てのデータを表示するのは、データ件数が多くなると見づらくなります。多くの場合、一部のデータを確認すれば十分です。
そのような場合、Seriesに格納したデータの内、最初の数行や最後の数行を取得して、確認していきます。
Seriesのデータの内、最初から指定した行数を表示するには、headを利用します。引数では行数を指定し、head(行数)のように記述します。引数を省略した場合、最初の5行が表示されます。
1 939
2 398
3 678
4 601
Name: Sales_Amount, dtype: int64
一方で、最後から指定した行数を表示するには、tailを利用します。引数では行数を指定し、tail(行数)のように記述します。引数を省略した場合、最後の5行が表示されます。
598 1053
599 590
600 484
601 508
Name: Sales_Amount, dtype: int64
データは0~601までの602件あるようです。
統計情報の取得・表示
データ件数と前後の数値の確認が終わったら、次にser_aの統計情報を表示し、統計的に全体の傾向を確認しましょう。
mean 811.524917
std 236.318055
min 396.000000
25% 591.250000
50% 831.000000
75% 1037.750000
max 1246.000000
Name: Sales_Amount, dtype: float64
ser_aの統計情報が表示されました。countからデータ件数は602件、平均値は811円、最大値は1246円、最小値は396円、標準偏差236などが一覧で表示されました。
ただ標準偏差236だけの数値では、偏りは良くわかりません。そこで、グラフで可視化してみましょう。
ヒストグラムによる可視化
まずはPythonのグラフの描画用ライブラリMatplotlib(マットプロットリブ)からmatplotlib.pyplot クラスをインポートします。その際にpltという別名を付け、後からpltだけで使えるようにします。
Matplotlibで作成可能なグラフの中から、ここではヒストグラムを用いて、購入金額毎の頻度を表示します。
ヒストグラムの表示には、hist()を利用します。引数として、データの格納されたSeries ser_aを渡します。
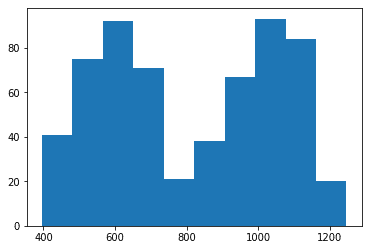
グラフの下に表示されているのが購入金額の範囲で、横軸に表示されているのが頻度になります。このようなヒストグラムを表示することで、それぞれの購入金額の範囲毎に、どのくらいの頻度があるのか、一目瞭然となります。
describe()で表示した統計情報から平均値は811円となっていましたが、平均値近くの購入頻度はほとんど無く、600円の前後と、1050円の前後の頻度が高いようです。
これらの地域Aの情報を元に推測すると、地域Cの客単価は、平均の811円あたりになるというよりは、ワーストケースとして600円あたりや、ベストケースとして1050円あたりに偏る可能性もありそうです。
次に地域Bのデータとして、CSVファイル「Sales_Area_B.csv」からデータを読み込み、変数ser_bに格納します。
ser_bも同様にヒストグラムで表示してみましょう。
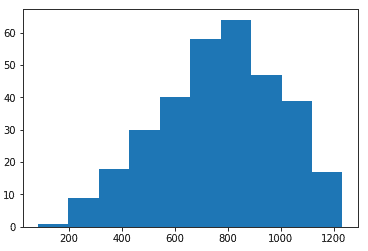
こちらの地域Bのグラフは、800円を中心とした正規分布に近い形になっています。
これらの情報からは、地域Cも地域Bと同様の性質を持つならば、客単価は800円くらいになる可能性が高く、そこから外れる可能性は800円から離れれば離れるほど、低くなりそうです。
Seriesの結合
今までは地域A、地域Bを個別に確認してきましたが、地域Cの近隣の地域として、地域A、Bを合わせて、全体像を確認していきましょう。
ser_aとser_bを結合させたものを変数ser_abに格納します。
ここではSeriesの結合の章で学んだconcat()を利用していますが、append()でも結果は同じです。後から別の地域のデータを結合させる必要が生じた場合に対応しやすいよう、concat()を使っています。
そして、ser_abの統計情報を表示すると、
mean 794.842162
std 236.112126
min 84.000000
25% 602.000000
50% 805.000000
75% 1016.000000
max 1246.000000
Name: Sales_Amount, dtype: float64
ser_abの統計情報が表示されました。平均は794円と800円あたりにあるようです。
次にser_abのヒストグラムを表示します。
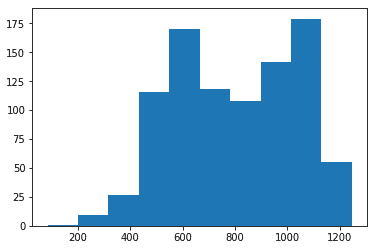
データ件数の多い地域Aの影響を受け、地域Aに近い形にはなっていますが、800円あたりでへこんでいた所は地域Bの影響により、無くなっているようです。
地域Cでも、近隣の地域A、Bと同じような販売活動や消費行動がとられるとするならば、客単価は平均を元に推定すると800円あたりになります。
また上下にぶれるリスクを考えると、最頻値のある1100円あたりがベストケースで、さらに次の最頻値がある600円あたりがワーストケースとして考えられ、この範囲に落ち着くであろうと推測されます。
一方で今後さらに、これらの地域A、地域Bの販売活動や消費行動も含めた詳細な特性と地域Cの類似性を検証していくことで、予測の精度は上がっていくことでしょう。
ここではSeriesを用いたデータ分析の1つの例を紹介しました。
関連記事です。
Seriesの次には、Pandasの中心となる、2次元のデータ構造であるDataFrame(データフレーム)について学んでいくのが良いと思います。

またPythonに関する重要なトピック全般について学んでいきたいと考えておられる方には、次のリンクをお勧めします。












