この記事では、newspaper3kというライブラリを使ってPython初心者でも簡単にできるスクレイピングの方法を確認していきます。ここでは、ニュースサイトのトップページに表示されている複数の記事を順に巡回し、記事を取得する方法を紹介いたします。
newspaper3kのインストール方法や基本的な使い方については、以下の記事をご覧ください。リンク先の記事では、newspaper3kの基本的な使い方を理解する為、ニュースサイトから1つの記事をピックアップし、その記事の全文やサマリー、キーワードを取得しています。

この記事では、newspaper3kの基礎からさらに発展させ、記事を1つ1つ指定して取得するのではなく、ニュースサイトのトップページのURLを渡しさえすれば、トップページに表示されている多くの記事を一度に取得する方法を見ていきます。
さらに取得した記事を後から確認できるよう、CSVデータとして保存していきたいと思います。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pythonでのスクレイピングによるニュースサイトから記事一覧の取得方法
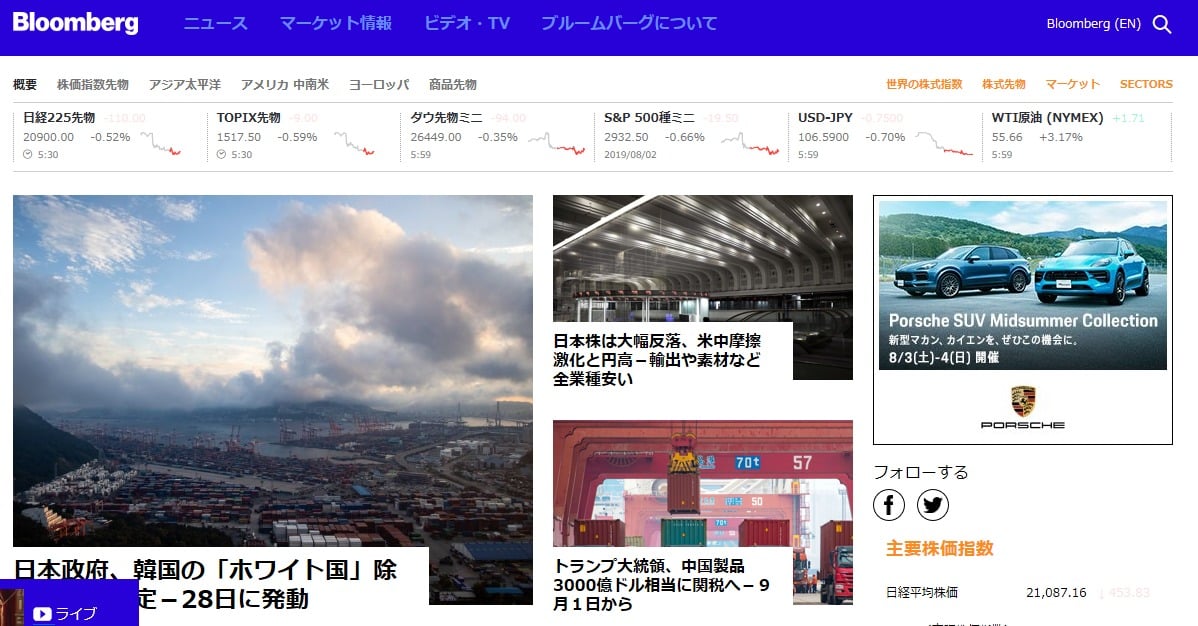
今回は、ブルームバーグのニュースサイト(https://www.bloomberg.co.jp/)をスクレイピングして記事を取得してみましょう。
サイトを訪問すると、次のようなページが表示されます。こちらがトップページで、更新された記事が一覧で掲載されています。
ここではまず、トップページの記事の一覧から各記事のURLとタイトルを取得して表示する例を確認していきます。
最初にnewspaperをインポートします。
次のステップとして、前回はArticle()を利用して1つの記事を取得しましたが、今回はbuild()を使います。build()を使うことによって、サイトのトップページから複数のページをまとめて取得することができます。
build()の引数として、記事を取得したいサイトのurlを渡します。
その他の引数としては、今回はテストの為、次のようなものを利用します。
memoize_articles = True/False : 取得した記事を記憶しておくか否か。Trueにすると、1度目に実行した時に取得した情報が記憶され、build()を再度実行しても、データは取得されません。ここでは、複数回実行しても結果の違いが分かるよう、Falseにしておきます。
MAX_SUMMARY = 文字数 : サマリーとして表示する最大の文字数を指定します。ここではテストの為、サマリーが取得できていることが確認できれば良いので、短くしておきます。
まず変数urlを定義して、ブルームバーグのニュースサイトのアドレスを格納します。次にbuild()に対して、このurlを渡します。また引数memoize_articlesはFalseに、MAX_SUMMARYは300を指定します。
...: website = newspaper.build(url, memoize_articles = False, MAX_SUMMARY = 300)またbuild()からの結果を変数websiteに格納しています。
これらbuild()から取得した記事の情報を確認していきましょう。まずは記事が取得できていることを確認する為、取得した記事のurlとタイトルを表示します。
取得した記事は属性articlesで確認できますので、これをfor文で1つ1つ順に取り出し、変数articleに格納します。そして、その属性urlに記事のURLが、属性titleにタイトルが入っているので、print文で表示します。
...: print(article.url)...: print(article.title)
実行すると、記事のURLが表示され、その下に記事のタイトルが表示されていることがわかります。これらの情報が、トップページに表示されている記事毎に、順に表示されていることがわかります。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pythonでのスクレイピングによるニュースサイトから記事サマリーの取得方法
今度は、記事のサマリーを取得していきましょう。記事のサマリーを取得するには、前回学んだ方法と同様、記事のオブジェクトに対して、download()で記事をダウンロードし、parse()で記事を解析し、nlp()で自然言語処理を実施した後で、summaryの属性を表示します。
サマリーを取得し、表示する例は次のようになります。
...: website_article = website.articles[item] ...: website_article_url = website_article.url ...: try:...: website_article.download()...: website_article.parse()...: website_article.nlp()...: print("記事[" + str(item) + "]: "+ website_article_url +" : "...: + website_article.summary + "\n")...: except:...: print("記事[" + str(item) + "]: "+ website_article_url +" : "...: + "取得エラー" + "\n")...: continue
1つずつ順に解説しますと、まず、for item in range(len(website.articles)):では、len(website.articles)で読み込んだ記事数を取得し、rangeで0から記事数まで、順に数値を1ずつ増やしながら、itemにその数値を格納し、for文で以降の処理を繰り返しています。
website_article = website.articles[item]では、取得した記事の内、item番目の記事を変数website_articleに格納しています。
そして、website_article_url = website_article.urlでは、属性urlでitem番目の記事のurlを取得し、変数website_article_urlに格納しています。この内容は、後にprint文でurlとして表示しています。
最後に、取得したitem番目の記事に対して、先ほど説明したdownload()、parse()、ntp()を実行して、サマリーをwebsite_article.summaryとして、print文で表示しています。
print文では、urlとサマリーの他に、"記事[" + str(item) + "]: "で何番目の記事かも表示しています。また最後に"\n"を付けて、1つの記事のサマリーを表示したら、改行するようにしています。
また、これらの一連の処理については、try:とexcept:を用いて、try以下の処理の実行中に何らかのエラーが発生した場合、except:でエラーが発生した記事番号、URLと合わせて、エラーが発生した旨をメッセージとして表示し、continueで次の記事の処理を続けるようにしています。
実行結果は次のようになります。

記事毎に番号が0から振られて記事[0]から順に、URLとサマリーが表示されていきます。サマリーは300文字だけを表示しています。
このようにして、ニュースサイトのトップページに表示されている複数の記事を、順に取得し、表示することができました。次回の章では、取得した記事を後から確認できるようファイルに保存する方法を見ていきましょう。
Pythonでのスクレイピングによりニュースサイトから取得した記事データのCSVファイルへの保存方法
今回は、その記事を後から確認できるよう、データを保存していきたいと思います。データはEXCELファイルで読み込んだり、データベースに取り込み易いよう、CSVファイルの形式で出力していきましょう。
前章のプログラムを元に、取得した記事のサマリーをCSVファイルに書き込むコードを追加していきたいと思います。
PythonでCSVファイルの読み書きを行うには、Pythonの標準ライブラリの中にCSVという便利なモジュールがあります。まずはCSVモジュールをインポートします。
またCSVファイルのファイル名には、後から見た時にいつの記事かがわかりやすいよう、記事を取得した日付を付けたいと思いますので、合わせて日付の取得に必要なライブラリdatetimeもインポートします。
CSVのファイル名に付ける日付は、datetime.datetime.today()で当日の日付を取得し、strftime()で文字列に変換します。その際に書式として、西暦4桁「%Y」、月「%m」、日「%d」の形式で表示されるよう”%Y%m%d”を渡します。このようにして取得した日付を変数csv_dateに格納しています。
先ほど作成した変数csv_dateと合わせて、CSVファイル名を保存する変数csv_file_nameを作成します。日付の前にはブルームバーグから取得したデータとわかるように、「bloomberg_」を付けています。またファイルの末尾には、csvファイルとなるように「.csv」を付けています。
次にCSVファイルへの書き込みの処理を記述していきます。何かを書き込む前に、open()を利用して、空のCSVファイルをオープンすることが必要になります。
open()の記述方法は次のようになります。
引数として、最初にファイルの保存先ディレクトリとファイル名を指定します。ここでは、先ほどの変数csv_file_nameを指定します。ここでは、ディレクトリは指定せず、プログラムを実行するディレクトリにファイルを出力してみます。
引数modeでは、ファイルを読み込むモードを指定します。'w'を指定すると、書き込み用に開きます。
また引数encodingでは、CSVファイルの文字コードを指定します。ここでは、コンピュータ上で日本語を含む文字列を表現するために用いられる文字コードの一つであるShift_JIS(シフトジス)を指定します。Shift_JISを指定するには、引数に’cp932’(Shift_JIS)を渡します。
ここでは次のように記述します。
CSVファイルのオープンが終わりましたら、次にヘッダを書き込んでみましょう。CSVファイルへの書き込みには、csv.writer()を利用します。
csv.writer()の最初の引数には、open()で開いたファイルオブジェクトを指定します。ここでは、open()から返されたオブジェクトを変数fに代入していますので、fを指定します。
引数lineterminatorでは、改行方法を指定します。ここでは改行時に通常用いる'\n'を指定しています。
そして、CSVファイルに1行を書き込むには、writerow()を使います。writerow()には、CSVファイルに書き込みたい内容をリスト型で渡します。
一連のプログラムは次のようになります。
....: csv_header = ["記事番号","URL","サマリー"] ....: writer.writerow(csv_header)
ヘッダの書き込みが終わりましたので、いよいよニュースサイトから1つ1つの記事を取得して表示しているプログラムに、CSVファイルへの書き込みを追加してみましょう。
サマリーを取得し、表示、CSVファイルへ書き込みするプログラムは次のようになります。
....: csvlist = [] ....: website_article = website.articles[item] ....: try:....: website_article.download()....: website_article.parse()....: website_article.nlp()....: print("記事[" + str(item) + "]: "+ website_article_url +" : "....: + website_article.summary + "\n")....: csvlist.append(str(item))....: csvlist.append(website_article.url)....: csvlist.append(website_article.summary)....: writer.writerow(csvlist)....: except:....: print("記事[" + str(item) + "]: "+ website_article_url +" : "....: + "取得エラー" + "\n")....: continue....: f.close()
基本的な流れは前のプログラムと同じになりますので、今回はCSVファイルへの書き込みの箇所に絞って解説します。該当箇所の背景色を変更しています。
1つずつ順に解説しますと、csvlist = [] では、空のリストを変数csvlistに渡し、初期化しています。これからcsvlistには、ファイル出力する1行の情報を格納し、writerow()に渡して1行ずつ書き込んでいくことになります。
次に、1つの記事のサマリーの取得が終わり、画面表示が終わりましたら、リスト型の変数csvlistに対して、ファイル出力する1行の情報を格納していきます。
csvlist.append(str(item))で記事番号を、csvlist.append(website_article.url)で記事のURLを、csvlist.append(website_article.summary)で取得した記事のサマリーを順にcsvlistに対して格納しています。
そして最後に、writerow()に対してcsvlistを渡して、1行の情報をCSVファイルに書き込んでいます。またfor文が終わりましたら、f.close()でopen()で開いたファイルオブジェクトを閉じます。
実行結果は次のようになります。

画面に表示される内容は、前の章と同じです。記事毎に番号が0から振られて記事[0]から順に、URLとサマリーが表示されていきます。サマリーは300文字だけを表示しています。
また出力されたCSVファイルを開けると、

1つ1つ取得した記事毎に順に、記事番号、URL、サマリーと出力されています。
このようにして、スクレイピングで取得した記事を後から確認できるよう、CSVファイルの形式で出力し、データを保存することができました。
関連記事です。
Pythonを使ったスクレイピングについての詳細は、こちらをご覧ください。