発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Requestsとは
requestsとは、HTTP通信用のPythonのライブラリです。主にWEBスクレイピングでHTMLやXMLファイルからデータを取得するのに使われます。
インターネット上に公開されているWEBサイトでは広くHTMLやXMLが使われており、これらの情報の取得に大変便利なライブラリです。
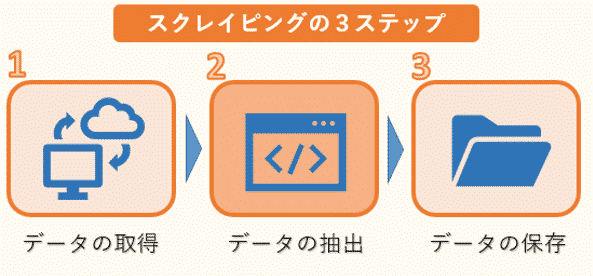
スクレイピングは、大まかに3つのステップに分けることができます。
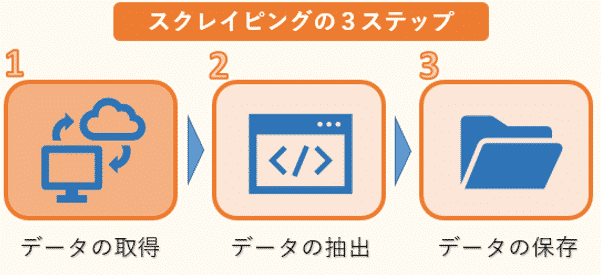
1つ目はWEBサイトのHTMLなどのデータ取得です。ただし、HTMLには必要な文章のデータだけでなく、タグなどのデータも混じっているので、必要なものだけを抽出する作業が必要になります。
そこで2つ目のデータの抽出が欠かせません。ここでは、複雑な構造のHTMLデータを解析し、必要な情報だけを抽出します。
そして最後に抽出した情報をデータベースやファイルなどに保存します。
このWEBスクレイピングの3ステップの中で、requestsは1つ目のHTMLデータの取得によく用いられます。Pythonではrequestsを利用して、簡単にWEBサイトからデータを自動的に取得することができます。
その後、取得したデータからBeautiful Soupなどの別のライブラリを用いて必要な情報のみを抽出します。Beautiful Soupの詳しい説明は、「図解!Beautiful SoupでWEBスクレイピング徹底解説!」を参照ください。
またRequests、BeautifulSoup、Seleniumについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)(Udemyへのリンク)
ここではまず、requestsというライブラリの基本となる使い方を確認していきましょう。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Requestsのインストール(pip・conda)
Requestsは、標準ではインストールされていませんので、pipやcondaを利用して別途インストールする必要があります。
requests をpipでインストールする場合は、次のコマンドを入力してください。
pipの詳しい説明は「Pythonでの外部ライブラリの追加インストール方法」を参照ください。
またcondaでインストールする場合は、次のコマンドを入力してください。
condaの詳しい説明は「Anacondaでの外部ライブラリの追加インストール方法」を参照ください。
これでインストールは終わりました。次に、これらのライブラリを利用する前にはインポートしておく必要があります。
1 | import requests |
以上で、Requestsを使うための準備は終わりです。
Requestsの基本的な使い方
これからrequestsの基本となる使い方を紹介していきます。
requestsで主に使われるメソッドには、次のようなものがあります。
| メソッド | 説明 |
| get() | サーバから情報を取得するのに使用する。 |
| post() | サーバへ情報を登録する時に使用する。 |
| put() | サーバの情報を更新する時に使用する。 |
| delete() | サーバの情報を削除する時に使用する。 |
この中でも、WEBスクレイピングに使われるget()をまず紹介していきます。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
requests.get()の使い方
get()は、サーバからHTML、XMLなどの情報を取得するのに使用します。
requests.get()の記述方法は以下です。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| URL | 必須 | 読み込み対象のURL |
| headers | 任意 | ヘッダとして送信する内容を辞書で指定 |
| timeout | 任意 | リクエストのタイムアウト時間 |
| params | 任意 | URLのクエリパラメータを辞書で指定 |
| cookies | 任意 | クッキーとして送信する内容を辞書で指定 |
戻り値としてresponseオブジェクトが返ってきます。responseオブジェクトには様々な属性値があり、主なものは次になります。
| 属性 | 説明 |
| status_code | ステータスコード |
| headers | レスポンスヘッダの内容 |
| content | レスポンスのバイナリデータ |
| text | レスポンスの内容 |
| encoding | エンコーディング |
| cookies | クッキーの内容 |
※引数、responseオブジェクトの属性の詳細については、後で詳しく解説します。
ここではget()の使い方の例として、yahoo news のページを取得してみましょう。
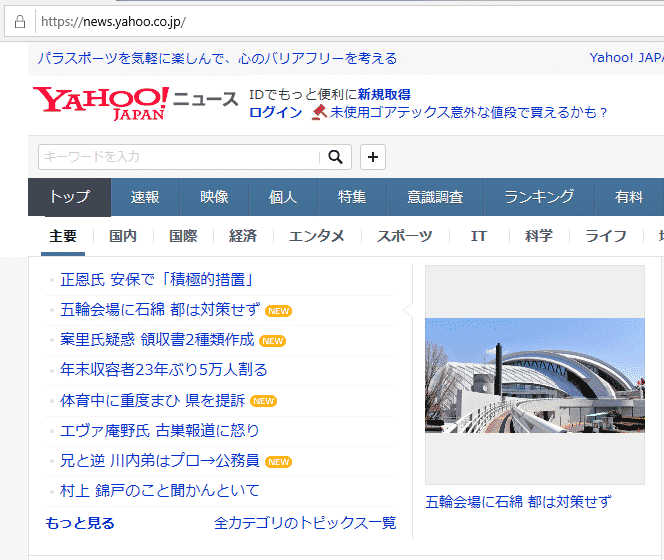
requests.get()を利用して、yahoo newsサイトの情報をダウンロードします。変数urlを定義し、確認したいWEBサイトのアドレスを渡します。
次に、requests.get()に対してurlを渡しています。request.get()で指定されたwebの情報を取得し、その結果は、変数responseに格納します。
1 2 | url = 'https://news.yahoo.co.jp' response = requests.get(url) |
試しに取得した内容を表示してみましょう。textで内容を確認することができます。ここでは最初の500文字だけを表示しています。
1 | response.text[:500] |

取得したHTMLのコードが表示されました。この中にはtitle「Yahoo!ニュース」なども含まれています。
また取得した全ての内容を表示するとわかりますが、主要ニュースのタイトルなど、画面に表示されている内容も取得できていることがわかります。
1 | response.text |
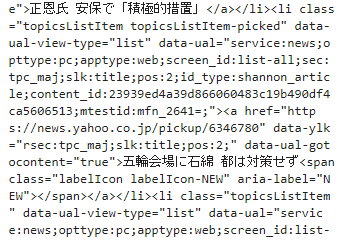
※一部抜粋
このようにWEBサイトの大量の情報が取り込まれています。
これら取得したデータの中から、ニュースのタイトルやURLなどの必要な情報を取得するのは、次のステップ2のデータの抽出になります。
データの抽出については、「図解!Beautiful SoupでWEBスクレイピング徹底解説!」をご確認ください。
Responseオブジェクト
ここでは、requests.get()の戻り値であるresponseオブジェクトの内容を詳しく確認していきましょう。
その前にHTTP通信の流れを確認しておきます。

最初にrequests.get()でサーバにリクエスト(あるURLのページを取得したいなど)を送信します。
そしてサーバで処理が行われ、サーバからレスポンスが返ってきます。その中にはステータスライン、ヘッダ、ボディが含まれます。これらの内容はresponseオブジェクトの属性で確認することができます。
先ほどyahoo newsサイトに対して実行したget()の戻り値を元に、responseオブジェクトの属性を確認していきます。
ステータスコード(status_code)
HTTPステータスコードは、HTTP通信においてWebサーバからのレスポンスの状況を示すコードになります。レスポンスのステータスラインの中に含まれます。
3桁のコードからなり、何番台かによって意味合いが異なってきます。
| ステータスコード | 範囲 | 説明 |
| 100番台 | 100-199 | Informational:リクエストは受け取られ、処理が継続。 |
| 200番台 | 200-299 | Success:リクエストに成功。 |
| 300番台 | 300-399 | Redirection :リダイレクトや移行など、リクエストの完了には追加的な処理が必要。 |
| 400番台 | 400-499 | Client Error:クライアントからのリクエストに誤りあり。 |
| 500番台 | 500-599 | Server Error :サーバ側でリクエストの処理に失敗。 |
400番台と500番台がエラーコードになります。
先ほどのresponseのステータスコードを表示してみます。
1 | response.status_code |
ここではリクエストの成功を表すコード200が表示されました。
レスポンスヘッダ(headers)
HTTPレスポンスヘッダは、HTTP通信においてWebサーバからのレスポンスのヘッダ部分になります。
レスポンスヘッダの内容を表示してみます。
1 | response.headers |
辞書で各要素のキーと値が表示されました。
辞書をそのまま表示するとわかりづらいので、各要素のキーと値をペアに改行して表示してみます。
1 2 | for key,value in response.headers.items(): print(key,' ',value) |
Content-Encoding gzip
Content-Type text/html;charset=UTF-8
Date Mon, 30 Dec 2019 00:47:30 GMT
Set-Cookie B=2cf6nhhf0ii92&b=3&s=g7; expires=Thu, 30-Dec-2021 00:47:30 GMT; path=/; domain=.yahoo.co.jp, XB=2cf6nhhf0ii92&b=3&s=g7; expires=Thu, 30-Dec-2021 00:47:30 GMT; path=/; domain=.yahoo.co.jp; secure; samesite=none
Vary Accept-Encoding
X-Content-Type-Options nosniff
X-Download-Options noopen
X-Frame-Options DENY
X-Vcap-Request-Id 74c556c6-726b-42c4-5eeb-c0a009486b0c
X-Xss-Protection 1; mode=block
Age 0
Server ATS
Transfer-Encoding chunked
Connection keep-alive
Via http/1.1 edge1554.img.bbt.yahoo.co.jp (ApacheTrafficServer [c sSf ])
レスポンスヘッダのキー毎の値が確認しやすくなりました。
エンコーディング(encoding)
レスポンスヘッダの中の項目にエンコーディングがあります。
レスポンスボディにはバイナリデータがありますが、バイナリデータは、テキスト以外のコンピュータで扱えるデータで、人間が見て理解できるものではありません。
バイナリデータをこのエンコーディングでデコード(復元)し、人間が確認できるようにしたものがテキストデータになります。
先ほどのresponseのエンコーディングを表示してみます。
1 | response.encoding |
UTF-8が表示されました。
レスポンスのバイナリデータ(content)
この属性により、レスポンスボディに含まれるバイナリデータを確認することができます。
画像などはバイナリデータをそのまま利用しますが、テキストの情報は人間が理解できるようデコード(復元)している属性textを使って確認します。
先ほどのresponseのバイナリデータを表示します。最初の500文字だけを表示します。
1 | response.content[:500] |
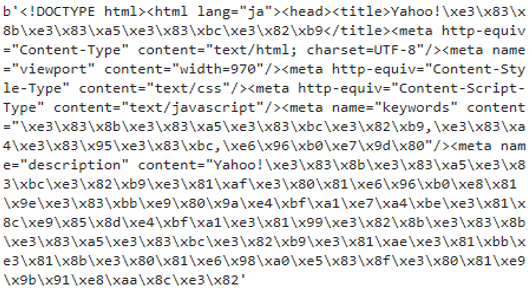
バイナリデータは、テキスト以外のコンピュータで扱えるデータなので、人間が見て理解できない文字が並んでいます。
レスポンスのテキストデータ(text)
レスポンスボディに含まれるバイナリデータを、ヘッダのエンコーディングでデコード(復元) し、人間が確認できるようにしたものがテキストデータになります。
テキスト情報は、この属性の内容で確認することができます。
responseの属性textの内容を表示してみましょう。ここでも最初の500文字だけを表示しています。
1 | response.text[:500] |
取得したHTMLのコードが表示されました。この中にはタイトルなどで日本語も含まれています。
レスポンスのクッキー(cookies)
クッキー(cookie)とは、参照しているWebサイトから送られて来る情報で、端末の中に保存されます。その中にはサイトを訪れた日時や、訪問回数など、さまざまな情報が記録されています。
この属性では、レスポンスに含まれるクッキーの内容を確認することができます。
responseの属性cookiesの内容を表示してみましょう。
1 | response.cookies |

レスポンスに含まれているクッキーの内容が表示されました。
requests.get()の引数
次にrequests.get()の引数の内容を詳しく見ていきましょう。
ヘッダ(headers)
リクエストにHTTPヘッダを追加することができます。その際にはheadersパラメータに辞書を渡します。
辞書のキーとなるリクエストヘッダの項目はたくさんありますが、その中でよく使うのがUser-Agentです。User-Agentにはアプリケーション名、バージョン、ホストオペレーティングシステムなどの情報が格納されています。
WEBサイトでは、ボットなどのコンピュータによるアクセスと人間によるアクセスはすぐに判別することができます。
これにより、アクセスを禁止するなどレスポンスが変わるサイトもあります。その判別に使われるのが、User-Agentになります。
スクレイピングをする際、User-Agentを設定するのに便利なのが、fake-useragentになります。fake-useragentを利用することにより、人間がアクセスしているのと変わらないUser-Agentの値を自動的に設定することができます。
fake-useragentのインストールは、次のコマンドを入力してください。
最初にインポートします。
1 | from fake_useragent import UserAgent |
UserAgent()のインスタンスuaを作成し、ua.chromeにてUser-Agentへの設定値を確認できます。ブラウザchromeでアクセスしているのと同様の設定値になります。
1 2 | ua = UserAgent() ua.chrome |
次にua.ieにて、ブラウザIEでアクセスしているのと同様のUser-Agentを表示します。
1 | ua.ie |
先ほどと表示されている内容が変わりました。
実際にリクエストヘッダのUser-Agentに設定する方法は次のようになります。ヘッダへ設定したい項目'user-agent'の設定値ua.chromeを辞書で定義します。そしてget()の引数headersに渡します。
1 2 3 | ua = UserAgent() header = {'user-agent':ua.chrome} response = requests.get('https://news.yahoo.co.jp',headers=header) |
タイムアウト(timeout)
リクエストの際、タイムアウトの時間(秒)を設定することができます。いつまでもレスポンスを待ち続けるのではなく、この時間が過ぎるとタイムアウトとして処理が終了します。
例えば、タイムアウト3秒を指定する方法は次のように記述します。get()の引数timeoutに秒数を渡します。
1 | response = requests.get('https://news.yahoo.co.jp',timeout=3) |
クエリパラメータ(params)
クエリパラメータとは、サーバに情報を送るためにURLの末尾につけ足す文字列のことです。
例えば、googleで「python」と検索すると、
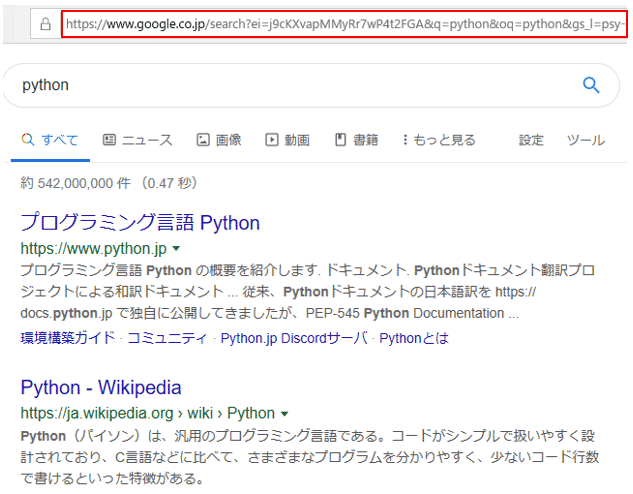
次のようなURLが表示されます。「https://www.google.co.jp/search?ei=j9cKXvapMMyRr7wP4t2FGA&q=python…以降、省略」。
この場合「?ei=j9cKXvap…」の箇所がクエリパラメータになります。ここでは、クエリパラメータで検索条件が指定されています。
この中の「q=python」の箇所で検索条件「python」を指定していますので、「https://www.google.co.jp/search?q=python」で検索しても、先ほどと同様の結果が得られます。
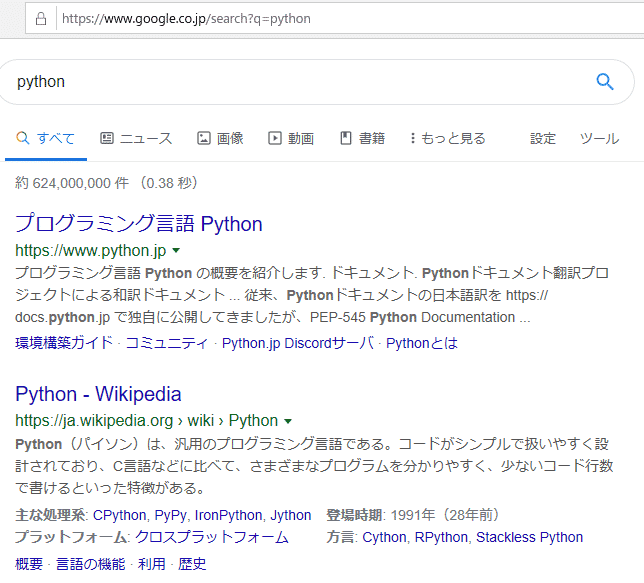
リクエストの際にクエリパラメータを指定するには、get()の引数paramを用います。引数paramには、辞書で値を渡します。
先ほどと同様、googleに対して検索条件「python」を入力した結果を、今度はrequestsを使って取得しましょう。
get()に対してURL'https://www.google.co.jp/search'とparamsに辞書で{'q': 'python'}を渡します。そして返ってきたresponseオブジェクトのテキスト属性を表示します。
1 2 3 | param = {'q': 'python'} response = requests.get('https://www.google.co.jp/search',params=param) response.text |
省略
すると結果として大量のHTMLが表示されました。
その中には、先ほどブラウザで検索して1番目に表示されていたページのタイトル「プログラミング言語 Python」と、説明文「プログラミング言語 Pythonの概要を紹介します。」も含まれています。
関連記事です。
Pythonを使ったスクレイピングについての詳細は、こちらをご覧ください。