
DataFrameに格納されたデータを取得する方法を確認していきましょう。まずこの章では、1つのインデックスが設定されたDataFrameに対しての検索方法を見ていきます。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
CSVファイルの読み込み
まず初めに次の情報を保持したCSVファイルを読み込みます。実際にビジネスで利用される売上情報(ヘッダ)のイメージになります。
後から読み込みますが、売上明細の情報は別途あり、そこに商品、数量、単価、金額などの情報が格納されています。
このヘッダ情報には、Sales_Noとして売上伝票毎にAから始まる番号の連番が、Sales_dateには売上日が、Customer_IDには顧客IDが、Sales_Orgには販売組織IDが設定されています。顧客IDや販売組織IDは、別途マスタデータがあり、IDと共に名称などの情報を持っています。
| Sales_No | Sales_Date | Customer_ID | Sales_Org |
| A001 | 2018/6/22 | C03 | Q01 |
| A002 | 2018/6/23 | C14 | Q02 |
| A003 | 2018/6/24 | C30 | Q01 |
| A004 | 2018/6/25 | C01 | Q03 |
| A005 | 2018/6/26 | C01 | Q01 |
| A006 | 2018/6/27 | C02 | Q03 |
| A007 | 2018/6/28 | C02 | Q01 |
| A008 | 2018/7/5 | C03 | Q02 |
| A009 | 2018/7/24 | C04 | Q01 |
| A010 | 2018/7/12 | C04 | Q01 |
それでは、CSVファイル「T_Sales_Header.csv」からデータを読み込みます。(※CSVファイルは左のリンクから取得してください。)合わせてインデックスも指定します。
CSVファイルの読み込みは、後の章で詳しく説明しますがpd.read_csvを利用します。その際に引数として読み込むファイル名「T_Sales_Header.csv」とインデックスに列「Sales_No」を指定します。この読み込んだデータをDataFrameとして変数df_salesに格納します。
...: df_sales = pd.read_csv("T_Sales_Header.csv", index_col = ["Sales_No"])
そして次にDataFrameを格納した変数df_salesを入力すると、格納されているデータが表示されました。
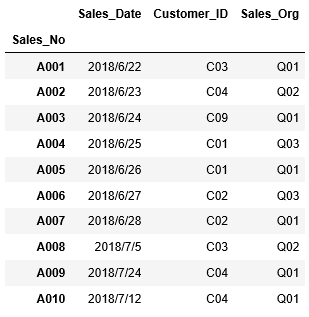
画面上部に表示されているのが、列名になります。”Sales_No”は一段下に表示されています。これはインデックスに指定されていることを示しています。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
先頭、最後から行数指定での抽出
先ほどの例のように、全てのデータを表示するのは、データ件数が多くなると見づらくなります。多くの場合、一部のデータを確認すれば十分です。
そのような場合、DataFrameに格納したデータの内、最初の数行や最後の数行を表示して、確認していきます。DataFrameのデータの内、最初から指定した行数を表示するには、headを利用します。
引数では行数を指定し、head(行数)のように記述します。引数を省略した場合、最初の5行が表示されます。
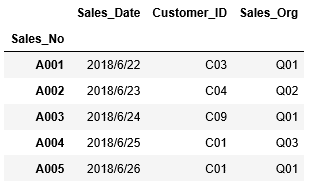
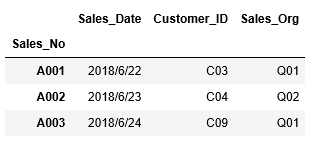
次にheadの引数に3を指定し、最初の3行を表示してみます。
先ほどは先頭行から指定行数を表示しましたが、逆に最後から指定した行数を表示するには、tailを利用します。
引数では行数を指定し、tail(行数)のように記述します。引数を省略した場合、最後の5行が表示されます。
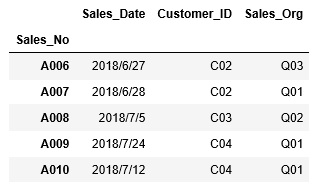
指定行・指定列の抽出
DataFrameのデータ抽出は、行番号、インデックスや列名を指定して行なうことができます。但し、複数の行と列を同時に指定してデータの抽出ができないなどの制限がありますので、後述するloc、ilocを利用することも多いです。
まずは列名を指定して、列”Customer_ID”の情報を表示してみましょう。

次にインデックスA003行の全ての列の情報を抽出します。
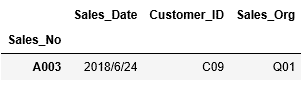
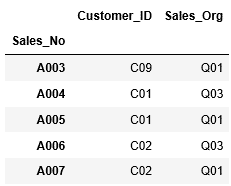
今度はインデックスの範囲を指定して、ある範囲の行を抽出します。A003~A006行までを抽出します。
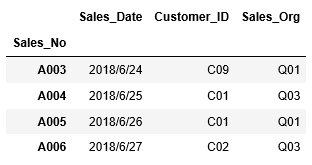
また行番号を指定して、ある範囲の行を抽出することもできます。同様にA003~A006行までを抽出します。
行番号での基本的な指定方法は次のようになります。
行番号は1行目から0で始まります。範囲には終了値に指定された値は含まれず、終了値-1までになります。また開始値、終了値を省略することができ、開始値が省略された場合は0番目からの指定となり、終了値が省略された場合は最後までの指定になります。
従って3行目のA003から6行目のA006までの指定は、[2:6]となります。つまり1行目から0で始まりますので、開始値は3行目の2となり、終了値-1までになりますので、終了値は7行目の6となります。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
ilocによる行・列番号を指定しての抽出
ilocを利用するとDataFrameから行・列番号を指定してデータを抽出することができ、加えて、スライシングも使うことができます。
まずは行を指定してデータの抽出をしてみましょう。行番号は0から始まります。2行目のデータを抽出する場合、次のようにilocに引数1を渡します。

次に4行目から6行目を抽出します。その場合、ilocに引数3:6を渡します。
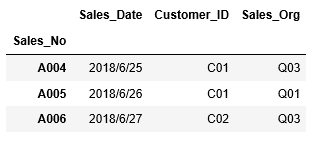
次に列を指定してデータを抽出します。こちらも列番号は0から始まります。全ての行の2列目の”Customer_ID”の値を取得する場合、行の指定を”:”(全行)、列の指定を1(2列目)とします。
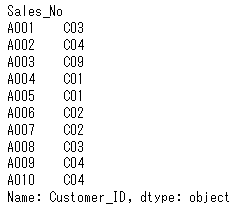
次のようなかたちで、行の範囲、列の範囲を指定して抽出することもできます。2~3行目の1~2列目のデータを抽出します。
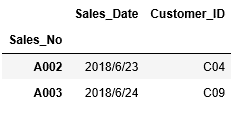
さらには、先ほどの例のように1~2列目というように連続した列では無く、1、3列目というように飛び飛びの列を指定したい場合は、[0,2]というように、[ ]括弧の中に指定したい列をカンマを挟んで記述します。
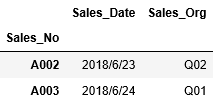
locによる行・列名を指定しての抽出
locを利用するとDataFrameからインデックス、列名を指定してデータを抽出することができます。スライシングも使うことができます。
まずはインデックスを指定してデータの抽出をしてみましょう。A003~A007行のデータを抽出する場合、次のようにlocに引数"A003":"A007"を渡します。
次に列を指定してデータを抽出します。全ての行の列”Customer_ID”の値を取得する場合、行の指定を”:”(全行)、列の指定を”Customer_ID”とします。

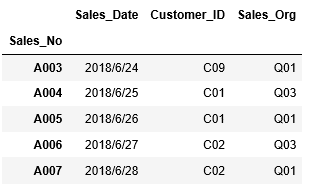
次のようなかたちで、行の範囲、列の範囲を指定して抽出することもできます。A002~A003行目の列”Customer_ID”、 "Sales_Org"のデータを抽出します。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













