発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Seleniumとは
Seleniumとは、ブラウザを自動的に操作するライブラリです。主にWEBアプリケーションのテストやWEBスクレイピングに利用されます。
主にWEBスクレイピングでは、JavaScriptが使われているサイトからのデータの取得や、サイトへのログインなどに使われています。
ここではまずスクレイピングの流れを確認し、その中でSeleniumがどのように使われるかを説明します。
スクレイピングの流れ
スクレイピングは、大まかに3つのステップに分けることができます。
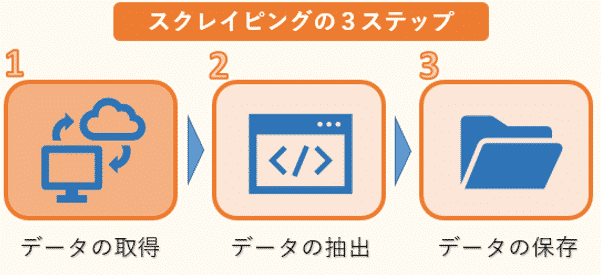
1つ目はWEBサイトのHTMLなどのデータ取得です。ただし、HTMLには必要な文章のデータだけでなく、タグなどのデータも混じっているので、必要なものだけを抽出する作業が必要になります。
そこで2つ目のデータの抽出が欠かせません。ここでは、複雑な構造のHTMLデータを解析し、必要な情報だけを抽出します。データの抽出にはBeautiful Soupなどのライブラリを使います。
そして最後に抽出した情報をデータベースやファイルなどに保存します。
スクレイピングでの使い方
このWEBスクレイピングの3ステップの中で、Seleniumは1つ目のHTMLデータの取得にrequestsと共によく用いられます。
Pythonではrequestsライブラリを利用して、簡単にWEBサイトからデータを自動的に取得することができます。
しかし、近年いくつかのWEBサイトではJavaScriptを用いて、ユーザーが画面のボタンをクリックや、画面をスクロールした時に次の画面を読み込む処理を組み込んでいるサイトがあります。
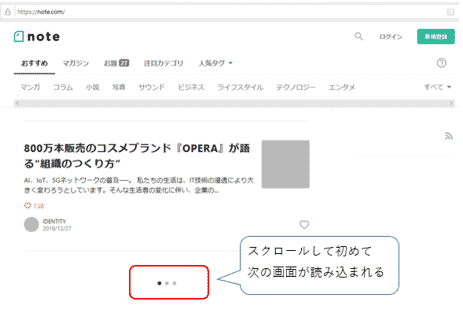
また最初にログインを求められるサイトもあります。

このようなサイトに対しては、機械的にrequestsライブラリだけでデータを取得することができません。
その際に利用するのがSeleniumになります。Seleniumでは、ドライバを経由してブラウザを操作することができます。
つまり、Seleniumでは人間がブラウザを経由して操作しているのと同じ動きを実現することができます。そしてブラウザを操作して、次の画面を読み込んでからrequestsライブラリを使って、画面のデータを取得します。
またSeleniumは、先ほどのWEBスクレイピングの3ステップの中で、2つ目のデータの抽出も行うことができます。
但し、Seleniumはブラウザを操作してデータを取得しますので、動作が遅いことが難点です。従って、できるだけ必要最低限の箇所でSeleniumを使うことをお勧めします。
この記事では、Seleniumというライブラリの基本となる使い方を確認していきます。
requestsの詳しい説明は、以下のリンクを参照ください。
>> 図解!PythonのRequestsを徹底解説!
またデータ抽出に使うBeautiful Soupの詳しい説明は、次のリンクを参照ください。
>> 図解!Beautiful SoupでWEBスクレイピング徹底解説!
またSelenium、BeautifulSoup、Requestsについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Seleniumのインストール
Seleniumは、標準ではインストールされていませんので、pipやcondaを利用して別途インストールする必要があります。
Seleniumは2021/10にSelenium 4が正式にリリースされていますが、この記事ではSelenium 3で解説を進めていきます。スクレイピングの機能向上の観点からはバージョンによる違いはほとんどありませんが、バージョンが異なると一部動作しないコードがありますのでご注意ください。
pipを利用してインストールする場合は、以下のコマンドを入力してください。
pipの詳しい説明は「Pythonでの外部ライブラリの追加インストール方法」を参照ください。
またcondaを利用してインストールする場合は、次のコマンドを入力してください。
condaの詳しい説明は「Anacondaでの外部ライブラリの追加インストール方法」を参照ください。
Seleniumからwebdriverをインポートします。また合わせてtimeからsleepもインポートしておきます。
1 2 | from selenium import webdriver from time import sleep |
sleepは、Seleniumでブラウザを操作した際に一定時間待つのに使います。
WebDriver(ChromeDriver)のインストール
Seleniumでは、WebDriverを仲介してブラウザを操作します。つまりSeleniumを使うにはWebDriverのインストールが不可欠です。
ブラウザの種類はメジャーなものでもいくつかありますが、WebDriverは各ブラウザの固有のものを用意する必要があります。この記事では使いやすさの観点からChromeDriverを元に解説を進めていきます。
もしお使いのパソコンにブラウザChromeがインストールされていない場合、以下のリンクからChromeをダウンロードして、インストールしてください。
>> Google Chrome公式サイト
ChromeDriverのインストールについては、以下のリンクからDriverをダウンロードしてください。
>> Chrome Driver公式サイト
ダウンロードした後、ZIPファイルを解凍し、chromedriver.exeを適当な場所に置いてください。そして次のようにしてChromeDriverを読み込みます。
例えば、私はディレクトリ「C:\Test_Folder\chromedriver_win32」の下にDriverを置きましたので、次のように記述します。
1 | driver = webdriver.Chrome('C:\Test_Folder\chromedriver_win32\chromedriver') |
以上で、Seleniumを使うための準備は終わりです。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Seleniumの基本的な使い方(Googleでの検索結果の取得と保存)
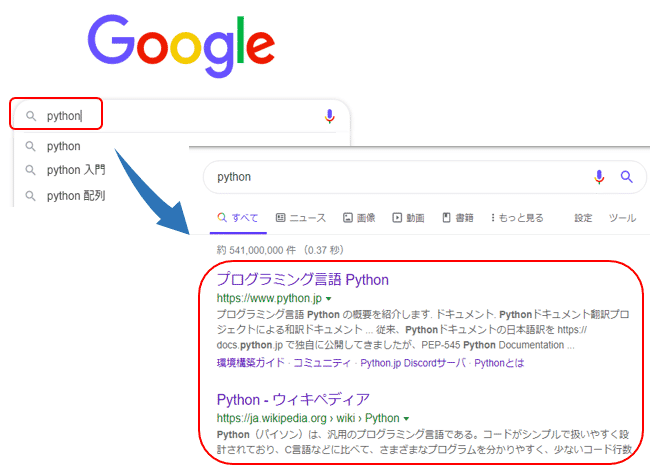
これからSeleniumの基本となる使い方を紹介していきます。ここはでは、Google(https://www.google.co.jp/) に検索条件「python」を入力し、検索結果を取得してみます。
サイトの表示
まずは先ほど読み込みましたdriverのメソッドget()を利用して、WEBサイトを開きます。get()は次のように書きます。
それではGoogleのサイトをオープンしてみましょう。
1 | driver.get('https://www.google.co.jp') |
するとGoogleの画面が開きました。
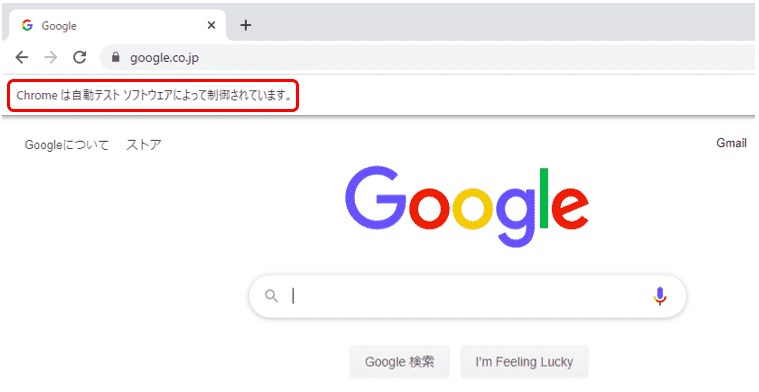
またSeleniumによって開かれた為、画面の左上には「Chromeは自動テスト ソフトウェアによって制御されています。」とメッセージが表示されています。
テキストボックスの要素の取得(find_element)
次に検索条件「python」を入力して検索します。
最初に検索条件を入力する欄を検索し、その後に検索した入力欄に対して検索条件を渡します。入力欄を検索するメソッドはいくつかありますが、ここではname属性で指定するfind_element_by_name()を利用してみましょう。
find_element_by_nameの記述方法は以下です。
1つ目の引数には、name属性の値を渡します。
Seleniumで使う主な検索メソッドは次のものになります。
| メソッド | 説明 |
| find_element_by_id(id) | id属性で要素を検索する |
| find_element_by_name(name) | name属性で要素を検索する |
| find_element_by_class_name(name) | class属性で要素を検索する |
| find_element_by_tag_name(name) | タグ名で要素を検索する |
| find_element_by_xpath(xpath) | XPathで要素を検索する |
| find_element_by_css_selector(css_selector) | CSSセレクタで要素を検索する |
| find_element_by_link_text(link_text) | リンクテキストで要素を検索する |
| find_element_by_partial_link_text(link_text) | リンクテキストの部分一致で要素を検索する |
Google ChromeでGoogleのページを開きます。検索条件の入力欄にマウスのカーソルを当て、右クリックします。するとメニューが表示されますので、その中から「検証」を選択します。
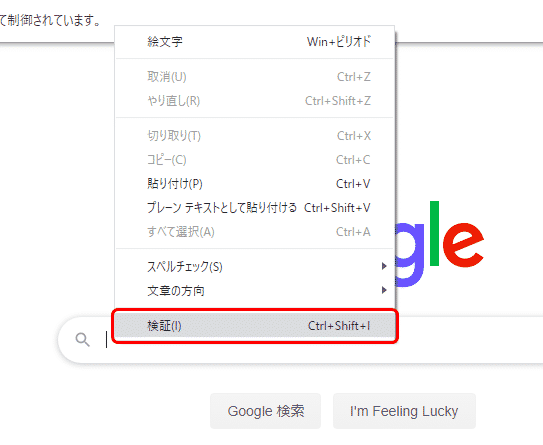
すると、右側にウィンドウが現れ、HTMLが表示されます。先ほどの検索条件の入力欄にカーソルが当たった状態で、背景色が灰色になっている箇所(赤色で囲った箇所)が入力欄に該当する箇所のコードになります。
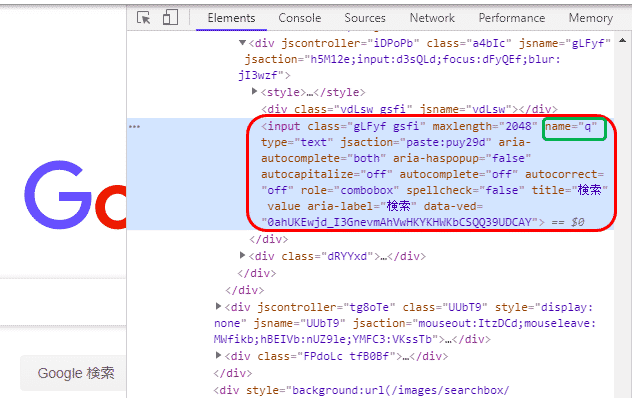
この中からname属性の値「q」(緑色で囲った箇所)を取得します。
そしてfind_element_by_name()の引数として渡し、返ってきた値を変数search_barに格納します。
テキストボックスへの文字入力と検索
次に指定された要素にテキストを送るメソッドsend_keys()に文字列”python”を渡し、実行してみます。
1 2 | search_bar = driver.find_element_by_name("q") search_bar.send_keys("python") |
するとGoogleの検索条件の入力欄に「python」という文字が入力されているのがわかります。
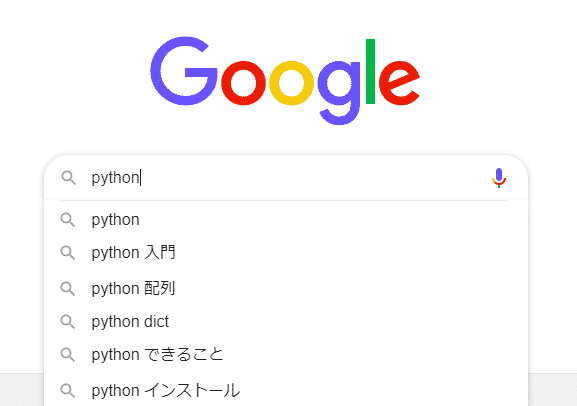
この状態で検索ボタンを押し、検索結果を表示してみましょう。メソッドsubmit()を実行します。
1 | search_bar.submit() |
実行すると、検索結果が表示されました。
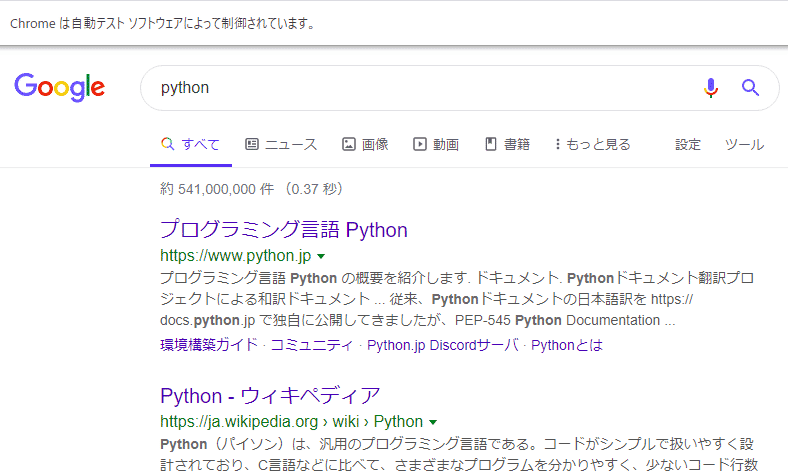
XPathによる検索結果一覧の取得(タイトルとURL)
次に先ほど取得したGoogleの検索結果で表示されているサイトのタイトルとURLを一覧で取得してみましょう。
まずはサイトのタイトルの取得方法を検討します。検索結果の最初のタイトルにマウスのカーソルを当て、右クリックします。
するとメニューが表示されますので、その中から「検証」を選択します。
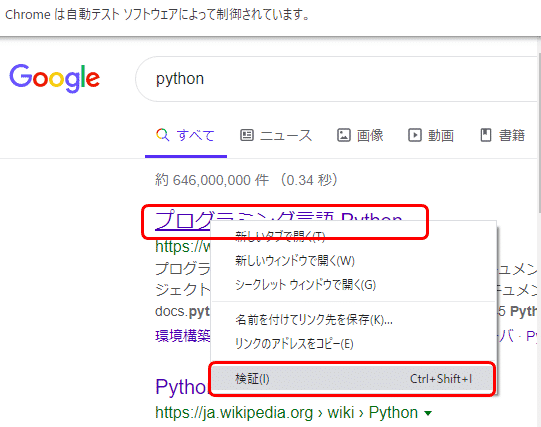
また右側にコードが表示されます。タイトルに該当する箇所(赤色で囲った箇所)が灰色になっています。ここでは、h3タグでタイトルが定義されています。
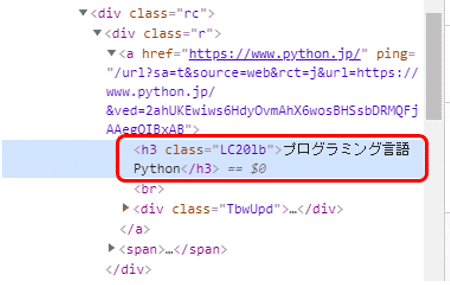
このh3タグを元にタイトルは取得できそうです。
今度はURLの取得方法も検討します。先ほどのコードを見ると、h3タグの上にaタグがあり、href属性でリンク先のURLが指定されています。HTMLは階層構造になっております。

これらの情報を元に検索結果のサイトのタイトルとURLを一覧で表示するコードは次のようになります。
1 2 3 4 | for elem_h3 in driver.find_elements_by_xpath('//a/h3'): elem_a = elem_h3.find_element_by_xpath('..') print(elem_h3.text) print(elem_a.get_attribute('href')) |

タイトルとURLが一覧で表示されました。
それではコードを詳しく解説していきます。
先ほど確認した結果から、タイトルはaタグの配下のh3タグに書かれていました。
但し、テキストボックスの要素を取得したようにh3タグにはname属性はありませんので、別の方法を考える必要があります。
そこで利用できるのがXPathになります。XPathはXMLやHTMLの文章に含まれる要素、属性値などを指定するための言語です。
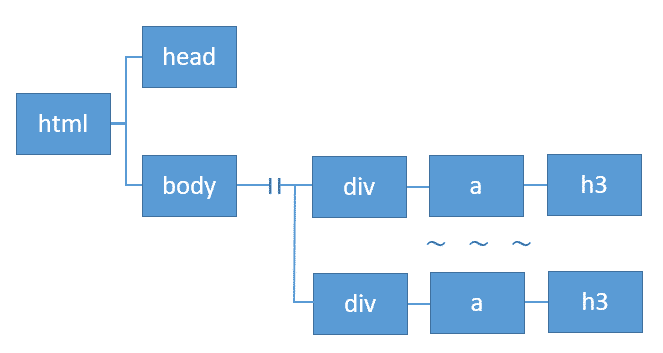
XPathでは、htmlは上記のようなツリー構造として取り扱います。今回はh3タグに取得したいタイトルが含まれており、検索結果に表示されているサイトの数に応じて、繰り返し出現しています。
上記のツリー構造からh3までをXPathで記述すると、
このように各要素の間を" / "(スラッシュ)で区切って記述します。
また" // "(ダブルスラッシュ)で途中の要素を省略して記述することもできます。
ここでa-h3の要素を指定するには、
と記述します。
XPathの詳しい説明は、「図解!XPathでスクレイピングを極めろ!」を参照ください。
下記のコードではfor文で順に、XPathでa-h3の要素を指定し、取得した内容を変数elem_h3に格納しています。for文の詳しい説明は、「図解!Python for ループ文の徹底解説」を参照ください。
次にこのコードではh3タグの親を検索し取得しています。ここではaタグになります。
ここでは取得したh3タグのテキスト(サイトのタイトル)を表示しています。
そしてaタグのhref属性(サイトのURL)を表示しています。
これらの実行結果から、検索結果に表示されているサイトのタイトルとURLを一覧で表示することができました。
ヘッドレスモードで実行する方法
今まではブラウザで画面を表示させていましたが、画面を表示させずにブラウザを起動し、プログラムだけを実行させるヘッドレスモードもあります。
画面を表示しないので途中の経過を画面では確認できなくなりますが、その分速く実行できるというのがメリットです。
先ほどのコードをヘッドレスモードで実行する場合のコードは、次のようになります。変わった箇所の背景色を変えています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from selenium import webdriver from time import sleep from selenium.webdriver.chrome.options import Options options = Options() options.add_argument('--headless') driver = webdriver.Chrome('C:\Test_Folder\chromedriver_win32\chromedriver',options=options) driver.get('https://www.google.co.jp') search_bar = driver.find_element_by_name("q") search_bar.send_keys("python") search_bar.submit() for elem_h3 in driver.find_elements_by_xpath('//a/h3'): elem_a = elem_h3.find_element_by_xpath('..') print(elem_h3.text) print(elem_a.get_attribute('href')) |
プログラムを実行すると、今度はブラウザの画面が表示されません。
しかし、ヘッドレスモードで実行しても結果には変わりなく、タイトルとURLが一覧で表示されます。
前の章のコードからの追加・変更箇所を抜粋します。以下のコードを追加・変更することにより、ヘッドレスモードで実行することができました。
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome('C:\Test_Folder\chromedriver_win32\chromedriver',options=options)
ヘッドレスモードを無効にする場合、次の箇所をコメントアウトすると無効になります。
コードはヘッドレスモードで実行できるように記述しておき、上記の箇所をコメントアウトする・しないでヘッドレスモードの無効・有効を切り替えれば良いでしょう。
次のページへ遷移(「次へ」のリンクをクリック)
先ほどは、Googleで検索した結果の1ページ目の情報を取得しましたが、今度は、2ページ目以降の情報も取得してみましょう。
まずはいつものように情報の取得方法の確認を行います。
Chromeブラウザで「次へ」のリンクにカーソルを当て、右クリックのメニューから「検証」を選択しましょう。
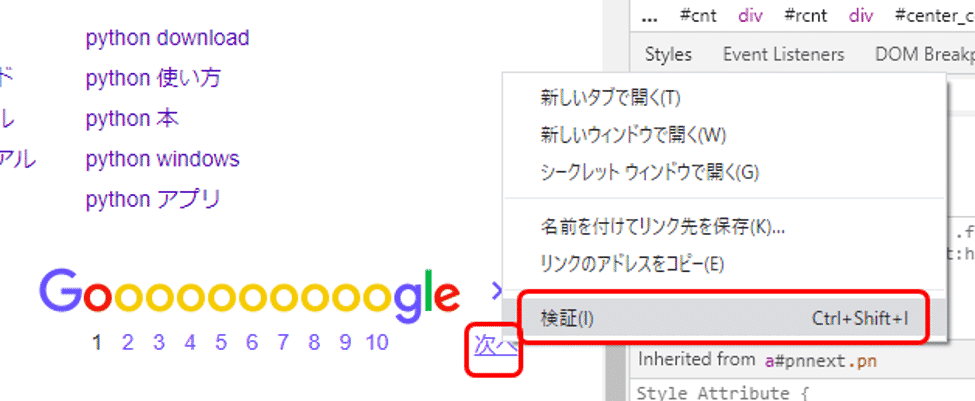
すると次のようなHTMLが表示されました。
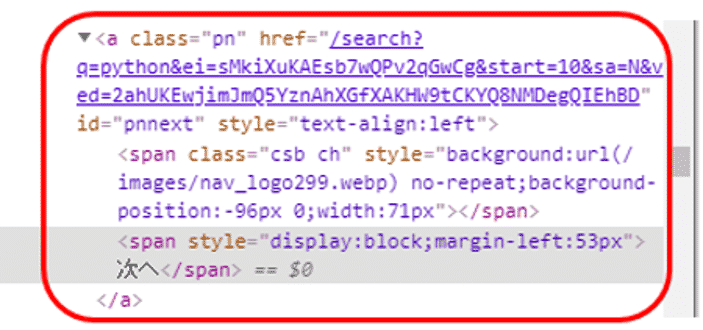
ここでは、aタグのhref属性に次のページのURLの一部が埋め込まれているようです。これを取得するには、id = “pnnext”が使えそうです。
これらの確認した情報を元に、2ページ目以降の検索結果の情報を一覧で表示するコードは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 | i = 0 while True: i = i + 1 sleep(1) for elem_h3 in driver.find_elements_by_xpath('//a/h3'): elem_a = elem_h3.find_element_by_xpath('..') print(elem_h3.text) print(elem_a.get_attribute('href')) next_link = driver.find_element_by_id('pnnext') driver.get(next_link.get_attribute('href')) if i > 4: break |

2ページ目以降もタイトルとURLが一覧で表示されました。※ここでは簡略の為、5ページまでの情報を取得しております。
それではコードを詳しく解説していきます。
全体の構成として、While True:で無限ループの繰り返し処理となっています。While Trueの詳しい説明は、「図解!Python while True 無限ループの抜け方と使い方を解説!」を参照ください。
1ページ毎に繰り返し処理を行い、変数iのカウントを増やしていき、5ページまでの処理が終わった時点でif文の中のbreakで繰り返し処理を抜けています。
while True:
i = i + 1
(…省略…)
if i > 4:
break
※「i > 4」の数値を変えると、ページ数を変更することができます。
先ほど省略した処理の中で前半のfor文の箇所は、前の章で説明したとおりサイトのタイトルとURLを一覧で取得して表示しています。
そして次の箇所で、先ほど確認した次ページのURLを取得し、そのURLでブラウザをオープンしています。
driver.get(next_link.get_attribute('href'))
このようにして、ページの上限に達するまで、処理が繰り返されていきます。
データのCSVファイルへのダウンロード・保存
前回は画面に表示していた検索結果のサイトのタイトルとURLを、今度はCSVファイルに保存しましょう。ファイルに出力することにより、取得した情報が保存され、後から見直すことも可能になります。
PythonでCSVファイルの読み書きを行うには、Pythonの標準ライブラリの中にCSVという便利なモジュールがあります。まずはCSVモジュールをインポートします。
1 | import csv |
またCSVファイルのファイル名には、後から見た時にいつの記事かがわかりやすいよう、記事を取得した日付を付けたいと思いますので、合わせて日付の取得に必要なライブラリdatetimeもインポートします。
1 | import datetime |
CSVのファイル名に付ける日付は、datetime.datetime.today()で当日の日付を取得し、strftime()で文字列に変換します。
その際に書式として、西暦4桁「%Y」、月「%m」、日「%d」の形式で表示されるよう”%Y%m%d”を渡します。このようにして取得した日付を変数csv_dateに格納しています。
1 | csv_date = datetime.datetime.today().strftime("%Y%m%d") |
先ほど作成した変数csv_dateと合わせて、CSVファイル名を保存する変数csv_file_nameを作成します。
日付の前にはGoogleから検索条件「python」で取得したデータとわかるように、「google_python_」を付けています。またファイルの末尾には、csvファイルとなるように「.csv」を付けています。
1 | csv_file_name = 'google_python_' + csv_date + '.csv' |
次にCSVファイルへの書き込みの処理を記述していきます。何かを書き込む前に、open()を利用して、空のCSVファイルをオープンすることが必要になります。
open()の記述方法は次のようになります。
引数として、最初にファイルの保存先ディレクトリとファイル名を指定します。ここでは、先ほどの変数csv_file_nameを指定します。ここでは、ディレクトリは指定せず、プログラムを実行するディレクトリにファイルを出力してみます。
引数modeでは、ファイルを読み込むモードを指定します。'w'を指定すると、書き込み用に開きます。
引数encodingでは、CSVファイルの文字コードを指定します。ここでは、コンピュータ上で日本語を含む文字列を表現するために用いられる文字コードの一つであるShift_JIS(シフトジス)を指定します。Shift_JISを指定するには、引数に’cp932’(Shift_JIS)を渡します。
ここでは次のように記述します。
1 | f = open(csv_file_name, 'w', encoding='cp932', errors='ignore') |
CSVファイルのオープンが終わりましたら、次にヘッダを書き込んでみましょう。CSVファイルへの書き込みには、csv.writer()を利用します。
csv.writer()の最初の引数には、open()で開いたファイルオブジェクトを指定します。ここでは、open()から返されたオブジェクトを変数fに代入していますので、fを指定します。
引数lineterminatorでは、改行方法を指定します。ここでは改行時に通常用いる'\n'を指定しています。
そして、CSVファイルに1行を書き込むには、writerow()を使います。
writerow()には、CSVファイルに書き込みたい内容をリスト型で渡します。
1 2 3 | writer = csv.writer(f, lineterminator='\n') csv_header = ["検索順位","URL","サマリー"] writer.writerow(csv_header) |
ヘッダの書き込みが終わりましたので、前章で作成したGoogleの検索結果を取得して表示しているプログラムに、CSVファイルへの書き込みを追加してみましょう。
CSVファイルへ書き込みするプログラムは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | i = 0 item = 1 while True: i = i + 1 sleep(1) for elem_h3 in driver.find_elements_by_xpath('//a/h3'): elem_a = elem_h3.find_element_by_xpath('..') csvlist = [] csvlist.append(str(item)) csvlist.append(elem_h3.text) csvlist.append(elem_a.get_attribute('href')) writer.writerow(csvlist) item = item + 1 next_link = driver.find_element_by_id('pnnext') driver.get(next_link.get_attribute('href')) if i > 4: break f.close() |
基本的な流れは前のプログラムと同じになりますので、今回はCSVファイルへの書き込みの箇所に絞って解説します。
1つずつ順に解説しますと、csvlist = [] では、空のリストを変数csvlistに渡し、初期化しています。これからcsvlistには、ファイル出力する1行の情報を格納し、writerow()に渡して1行ずつ書き込んでいくことになります。
次に、1つのサイトタイトルとURLの取得が終わりましたら、リスト型の変数csvlistに対して、ファイル出力する1行の情報を格納していきます。
csvlist.append(str(item))で検索順位を、csvlist.append(elem_h3.text)でサイトタイトルを、csvlist.append(elem_a.get_attribute('href'))でURLを順にcsvlistに対して格納しています。
そして最後に、writerow()に対してcsvlistを渡して、1行の情報をCSVファイルに書き込んでいます。
またfor文が終わりましたら、f.close()でopen()で開いたファイルオブジェクトを閉じます。
実行後に出力されたCSVファイルを開けると、
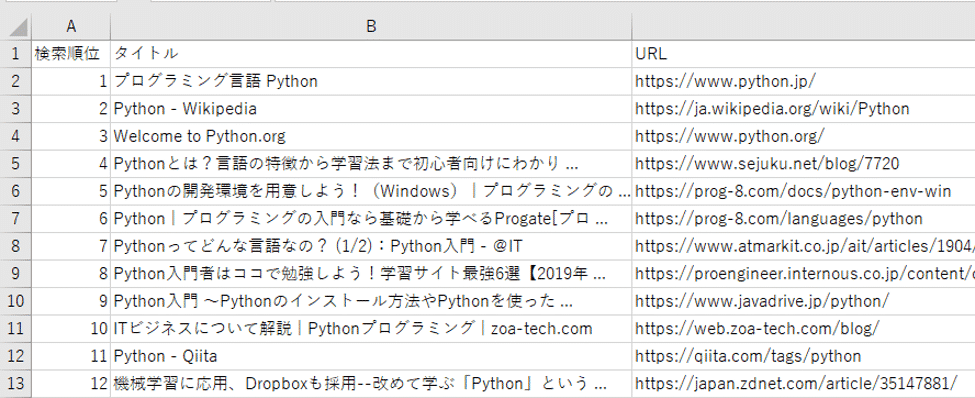
Googleで検索したサイト毎に、検索順位、タイトル、URLと出力されています。
このようにして、スクレイピングで取得した情報を後から確認できるよう、CSVファイルの形式で出力し、データを保存することができました。
ブラウザを閉じる
一連の処理が終わりましたら、最後にブラウザを閉じましょう。driver.close()で閉じることができます。
1 | driver.close() |
このようにして、Seleniumではブラウザを操作して、WEBサイトから必要な情報を取得していきます。
全コード掲載
これまでの「Googleでの検索結果の取得と保存」について、全てのコードを以下に置いておきます。必要に応じて開いてご確認ください。ご参考になれば幸いです。
Seleniumでログインする方法(インスタグラムへのログイン)
次にSeleniumでパスワード入力を求められるサイトでのログイン方法を確認していきましょう。ここはでは、インスタグラム(https://www.instagram.com) にログインします。
インスタグラムの最初の画面では「アカウントをお持ちですか?」と下にメッセージが表示されます。そこで「ログインする」のリンクをクリックします。
そして次の画面で「電話番号、ユーザーネーム、メールアドレス」と「パスワード」を入力しログインボタンを押します。
ログインしたら、最初に以下のような「お知らせをオンにする」を確認するメッセージが表示されるので、「後で」をクリックします。
するとメイン画面が表示されます。
このログインに必要な一連の操作を、Seleniumを使って自動的にしてみましょう。
ログインに必要なインスタグラムのアカウントをお持ちでない場合は、最初の画面からユーザー登録を事前に行ってください。
以下の赤で囲った箇所に必要な情報を入力の上、「登録する」ボタンを押すと、ユーザー登録できます。
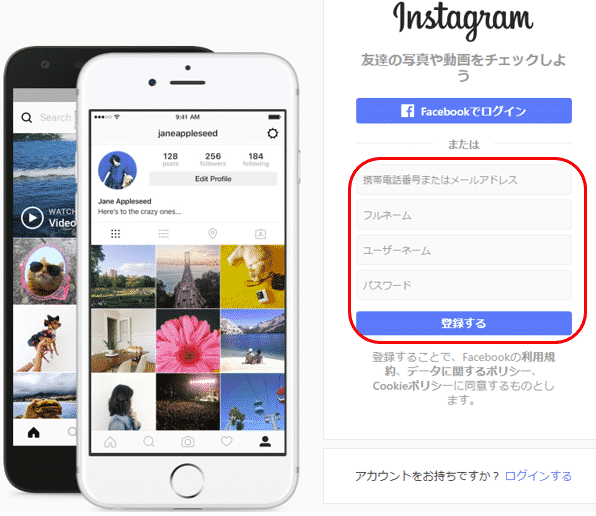
ログイン用リンクのクリック
最初のステップとして、インスタグラムのサイトを表示し、リンク「ログインする」をクリックしましょう。
コードは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | from selenium import webdriver from time import sleep USERNAME = 'インスタグラムのユーザー名' PASSWORD = 'インスタグラムのパスワード' driver = webdriver.Chrome('ChromeDriverのディレクトリ + chromedriver') error_flg = False target_url = 'https://www.instagram.com' driver.get(target_url) sleep(3) try: login_button = driver.find_element_by_link_text('ログインする') login_button.click() sleep(3) except Exception: error_flg = True print('ログインボタン押下時にエラーが発生しました。') |
プログラムを実行すると、
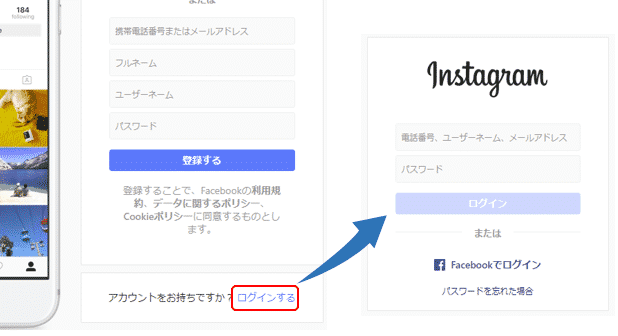
インスタグラムの画面が表示された後「ログインする」のリンクがクリックされ、ログイン画面が表示されました。
それではコードを詳しく解説していきましょう。
次の変数USERNAME、PASSWORDには、お持ちのインスタグラムのアカウント情報を入力下さい。この情報を元にログインします。
PASSWORD = 'インスタグラムのパスワード'
また「WebDriverのインストール」の章で説明したように、ChromeDriverを格納したディレクトリとファイル名「chromedriver」を入力してください。
そして読み込んだdriverのメソッドget()を利用して、インスタグラムのサイトを開きます。
target_url = 'https://www.instagram.com'
driver.get(target_url)
変数error_flgはエラーの判定に使うフラグです。最初はFalseを設定しておきます。
そして途中でエラーが発生した場合はTrueを設定して、以降の処理をスキップする判定に使います。
次に「ログインする」のリンクをクリックしています。
login_button.click()
リンクはfind_element_by_link_text(‘リンク名’)で該当のリンクを検索し、click()でクリックすることができます。
例外処理
先ほどのコードでは処理全体をtry~exceptで囲っており、try以下の処理でエラーが発生した場合は、except以下の例外処理に移るようにしています。
~
except Exception:
error_flg = True
print('ログインボタン押下時にエラーが発生しました。')
exceptでの処理は、変数error_flgにTrueを設定し、エラーメッセージをprint()で表示しています。
また以降の処理では、最初に「if error_flg is False:」と記述し、error_flgがFalseの時(エラーが発生しなかった時)のみ、処理を実行するようにしています。
ログイン画面でのユーザーネーム・パスワードの入力
次に、ログイン画面でユーザーネームとパスワードを入力し、インスタグラムにログインしましょう。
まずはログイン画面でユーザーネームとパスワードの入力欄の検索方法を確認します。それぞれの入力欄にカーソルが当たっている状態で右クリックし、メニューから「検証」を選択します。
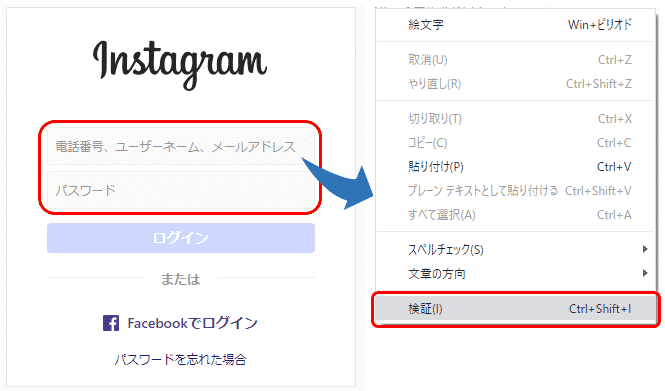
すると、ユーザーネームとパスワードで次のコードが表示されました。

ここではinputタグの属性aria-labelで検索することができそうです。
XPathである特定のタグの属性を指定する方法は、次になります。
例えば、inputタグの属性aria-labelがパスワードのものを検索するには、
と記述します。
これらの情報を元に記述したコードは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | if error_flg is False: try: username_input = driver.find_element_by_xpath('//input[@aria-label="電話番号、ユーザーネーム、メールアドレス"]') username_input.send_keys(USERNAME) sleep(1) password_input = driver.find_element_by_xpath('//input[@aria-label="パスワード"]') password_input.send_keys(PASSWORD) sleep(1) username_input.submit() sleep(1) except Exception: print('ユーザー名、パスワード入力時にエラーが発生しました。') error_flg = True |
プログラムを実行すると、
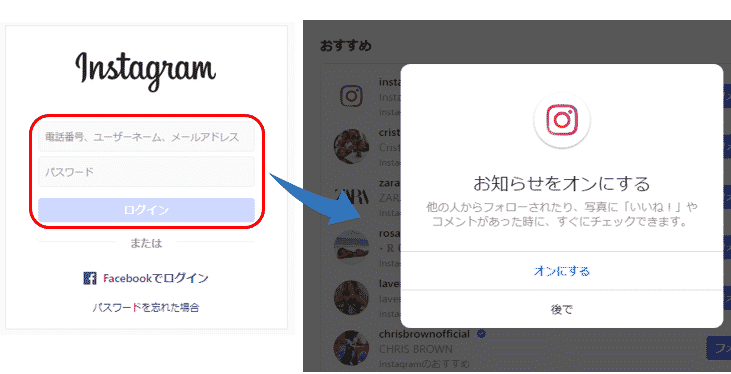
インスタグラムにログインできましたが、ポップアップ画面で「お知らせをオンにする」かの確認メッセージが表示されています。
ポップアップ画面を操作し閉じる方法
次にポップアップ画面で「後で」を選択し、インスタグラムのメイン画面を表示させましょう。
ここでもまず、「後で」の検索方法を確認します。「後で」にカーソルを当てた状態で右クリックし、メニューから「検証」を選択します。
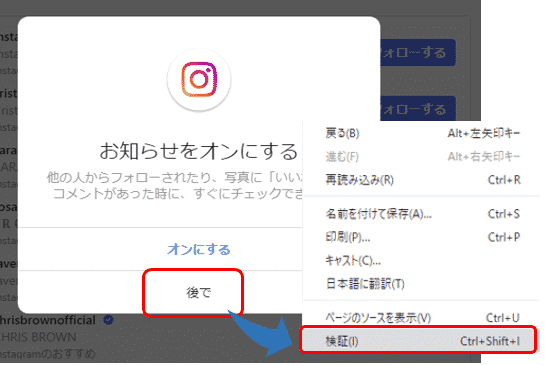
すると次のコードが表示されました。

buttonタグのテキスト「後で」で検索してみましょう。
XPathでは、テキストに含まれている文字で検索する場合、text()を使います。
最終的にコードは次のようになります。
1 2 3 4 5 6 7 8 9 10 | if error_flg is False: try: sleep(1) notnow_button = driver.find_element_by_xpath('//button[text()="後で"]') sleep(1) notnow_button.click() sleep(1) except Exception: pass |
プログラムを実行すると、
インスタグラムのメイン画面が表示されました。
このようにしてパスワードの入力を求められるサイトでも、Seleniumを使って自動的にログインすることができます。
Seleniumで画面スクロールする方法(インスタグラムで全ての画像を表示)
インスタグラムでは最初にいくつかの投稿された画像が表示され、画面をスクロールさせるにつれて、次のいくつかの画像が表示されます。
このようにして、全ての画像を確認するには、何度と画面をスクロールさせる必要があります。この章ではSeleniumで画面をスクロールさせる方法を確認していきましょう。
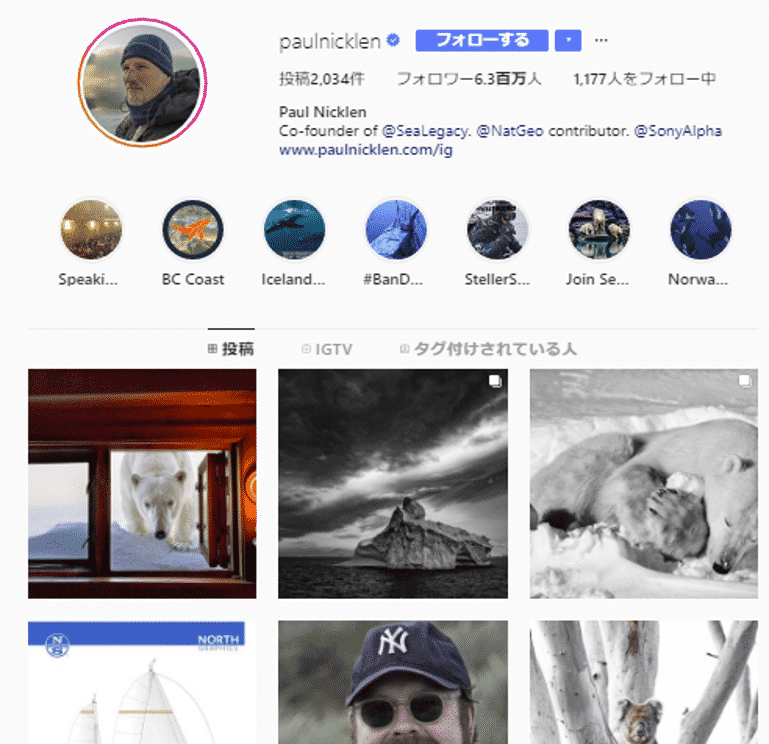
ここでは、インスタグラムにログインした後、有名な写真家であるポール・ニックレンさんのページを表示します。
ポール・ニックレンさんは、極圏を中心に野生動物を撮影する写真家です。彼の写真は「ナショナル ジオグラフィック」誌にも掲載され、また数多くの賞も受賞されています。
ポール・ニックレンさんのページが表示されたら、投稿件数を確認します。

インスタグラムでは、1行に画像が3つ並んでおり、4行分の12画像が表示されたら、次の画像を読み込んでいるようです。

先ほど取得した投稿件数を元に、必要な画面スクロールの回数を計算します。そしてSeleniumで画面をスクロールさせながら、全ての画像を表示させてみましょう。

対象のページを表示
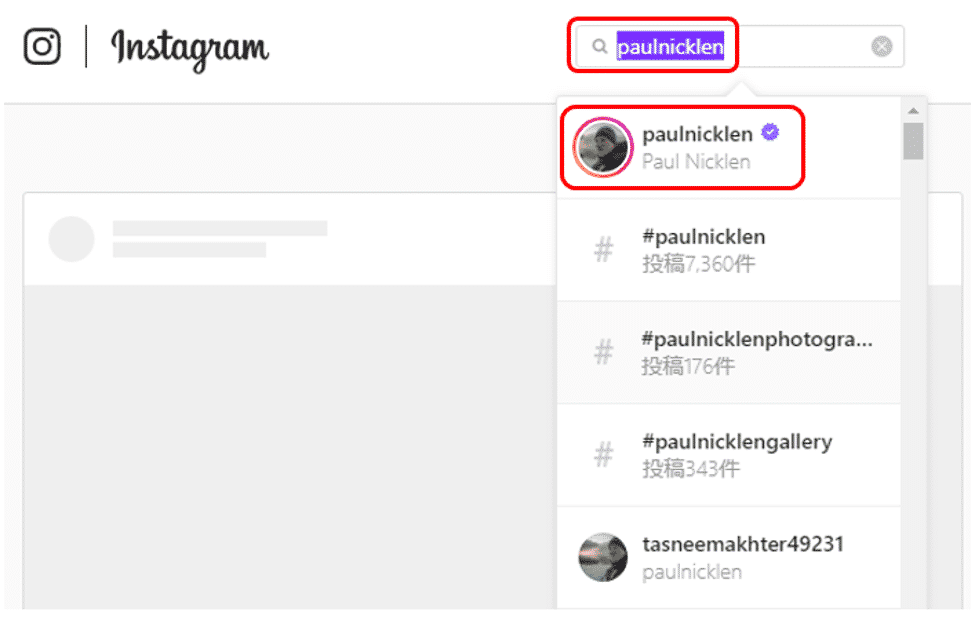
まずはインスタグラムの検索欄に「paulnicklen」と入力し、ポール・ニックレンさんのページを表示しましょう。
まずはポール・ニックレンさんのページを表示する方法を確認します。
検索欄に「paulnicklen」と入力し、表示された検索候補を確認すると、一番上が対象のページのようです。ここを右クリックし、メニューの中から「検証」を選択します。
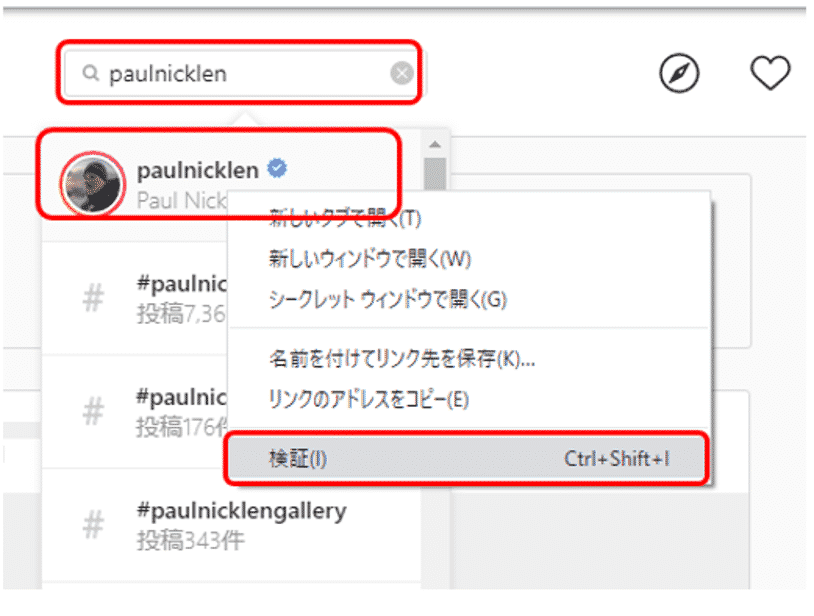
表示されたHTMLの中で、赤色で囲った箇所が対象ページのURLが格納されているようです。
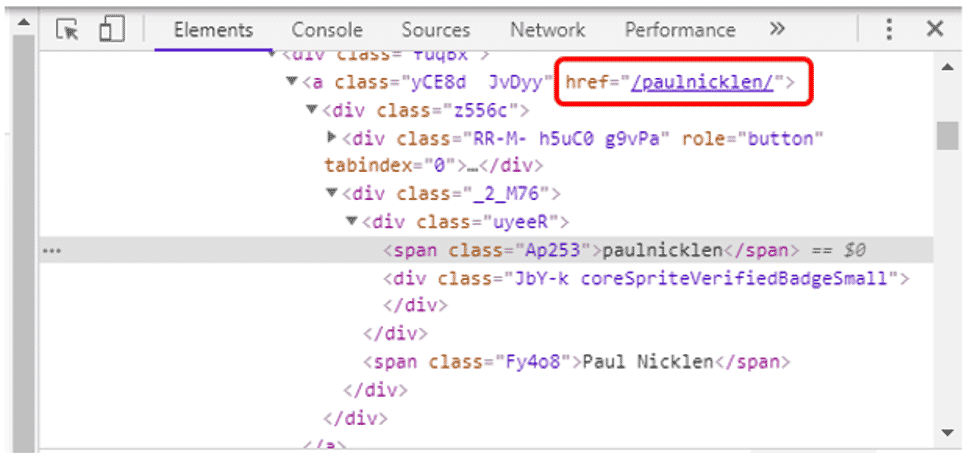
また検索欄で表示された検索候補を選択すると、ポール・ニックレンさんのページが表示され、URLは「https://www.instagram.com/paulnicklen/」と表示されています。
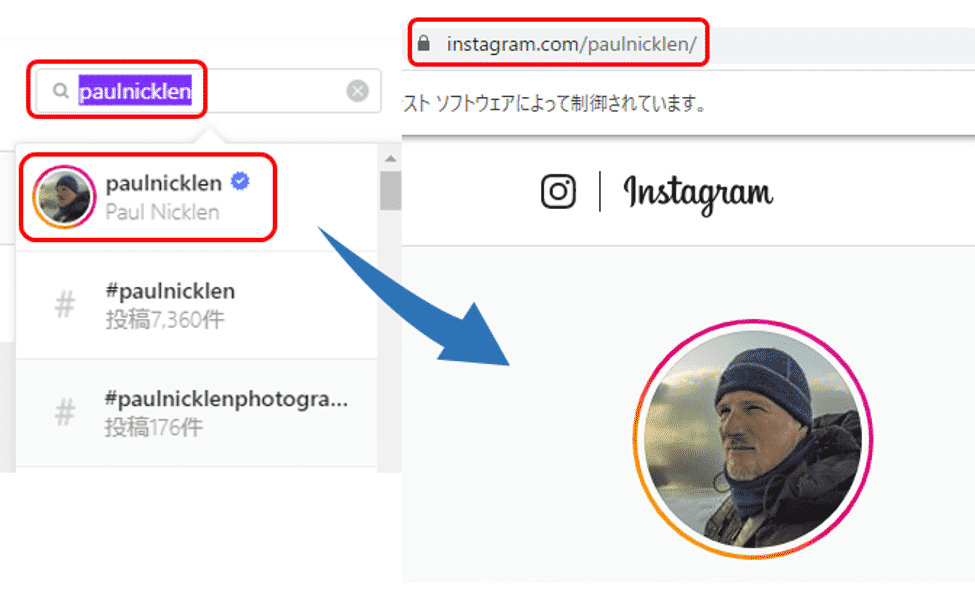
ということで、対象のページを取得するには、インスタグラムのURL「https://www.instagram.com/」に対して、ユーザーID「paulnicklen/」を付け、「https://www.instagram.com/paulnicklen/」で検索すれば良いようです。
対象ページを検索するコードは、次のようになります。
1 2 3 4 5 6 7 8 9 10 | target_username = "paulnicklen" if error_flg is False: try: target_profile_url = target_url + '/' + target_username + '/' driver.get(target_profile_url) sleep(3) except Exception: print('検索時にエラーが発生しました。') error_flg = True |
実行するとポール・ニックレンさんのページが表示されました。
投稿件数を取得
次にポール・ニックレンさんのページで投稿件数を取得し、画面スクロールに必要な回数を計算し、画面スクロールしていきます。
まずは投稿件数を取得する方法を確認します。

投稿件数が表示されている箇所にカーソルを当て、右クリックしてメニューを表示します。そして「検証」を選択します。
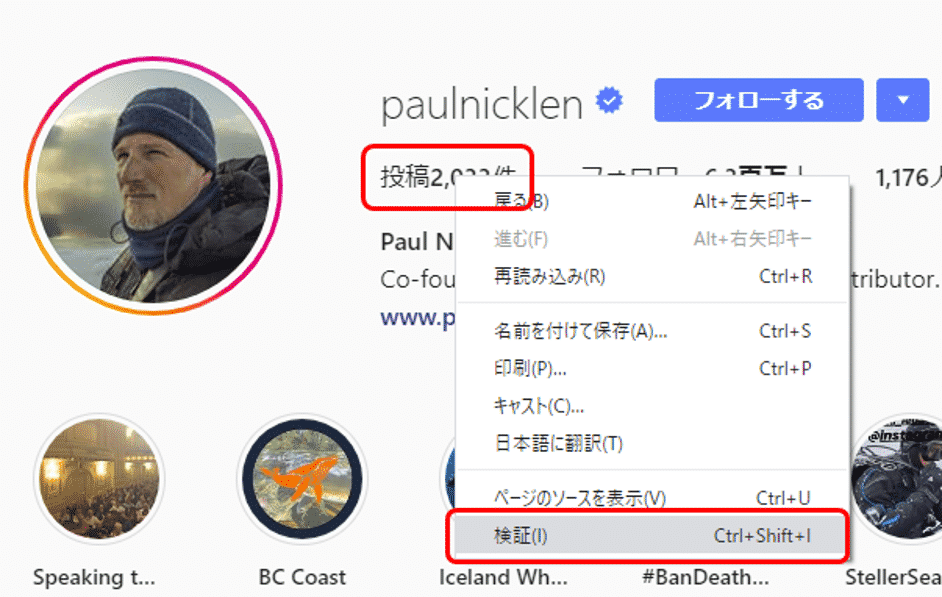
表示されたHTMLから、テキスト「投稿」、もしくは、「件」を元にその間に挿入されている件数「2,033」を取得できそうです。
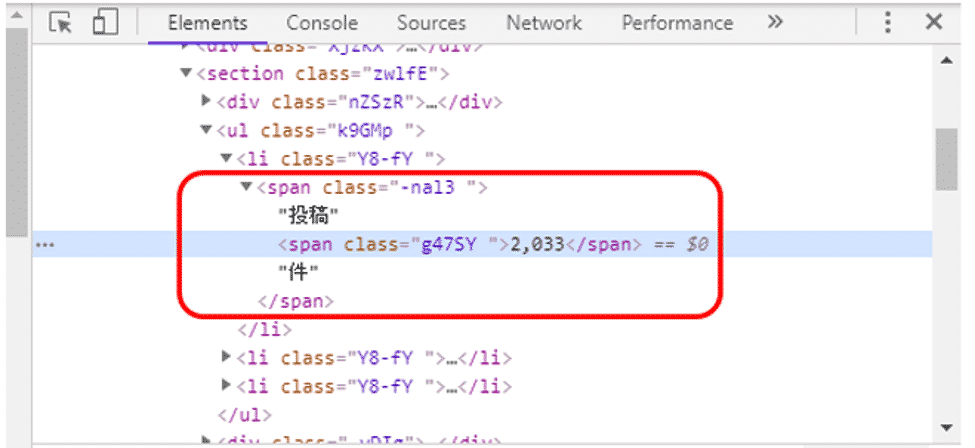
ここではspanタグのテキスト「投稿」で検索します。
前出のとおり、XPathではテキストに含まれている文字で検索する場合、text()を使います。
投稿件数を取得し画面に表示するコードは、次のようになります。
1 2 3 4 5 6 7 8 | if error_flg is False: try: post_count = driver.find_element_by_xpath('//span[text()="投稿"]').text post_count = post_count.replace('件', '').replace('投稿', '').replace(',', '') print("投稿数: " + post_count) except Exception: print('投稿数が取得できませんでした。') error_flg = True |
コードを詳しく解説していきます。
投稿件数が格納されているテキストの内容を取得し、変数post_countに格納しています。
この変数の中には、「投稿2,033件」というテキストが格納されています。この中から数値「2033」だけを抽出しましょう。
投稿件数の数値以外で含まれている「投稿」・「,」・「件」を取り除くにはreplaceを使います。
ここで置き換え後の文字に""を指定すれば、置き換え対象の文字は元の文字列から消えてなくなります。
以下が「投稿2,033件」から数値だけを抽出するコードになります。
このようにreplaceは連続して繋げて記述することもできます。
最後に取得した投稿件数の数値をprintで画面に表示しています。
実行結果は次のようになります。
投稿件数2033が表示されました。
画面スクロールし全てのページを表示
次に先ほど取得した投稿件数を元に画面スクロールに必要な回数を計算し、画面スクロールしていきます。
投稿件数を取得するコードに対して、画面スクロールするコードを追加したものは、次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | if error_flg is False: try: post_count = driver.find_element_by_xpath('//span[text()="投稿"]').text post_count = post_count.replace('件', '').replace('投稿', '').replace(',', '') print("投稿件数: " + post_count) post_count = int(post_count) if post_count > 12: scroll_count = int(post_count/12) + 1 try: for i in range(scroll_count): driver.execute_script('window.scrollTo(0, document.body.scrollHeight);') sleep(2) except Exception as e: error_flg = True print(e) print('画面スクロール中にエラーが発生しました。') sleep(10) except Exception: print('投稿数が取得できませんでした。') error_flg = True |
コードを詳しく解説していきます。
先ほど取得した投稿件数は変数post_countに格納されていました。これをまずは整数型に変換します。
インスタグラムでは1行に画像が3つ並んでおり、4行分の12画像が表示されたら次の画像を読み込んでいます。従って、投稿件数が12を超えたらスクロール回数を計算します。
投稿数を12で割り1を加えて算出したスクロール回数は、変数scroll_countに格納しています。
スクロール回数だけ繰り返し処理を行います。この中で画面スクロールを行います。
Seleniumでは、画面のスクロールはdriver.execute_script()でJavaScript APIを呼び出して実現します。
コードを実行すると、画面が次々にスクロールされていくのがわかります。

このようにして、取得した投稿件数を元に画面スクロールに必要な回数を計算し、画面スクロールさせることができました。
Requests、Beautiful Soupと連携し画像ファイルをダウンロード・保存する方法
先ほどの章では、Seleniumで有名な写真家ポール・ニックレンさんのインスタグラムのページを表示し、画面をスクロールさせながら、全ての画像を表示しました。
この章ではSeleniumと他のスクレイピング用ライブラリRequests、Beautiful Soupを組合せて、これらの表示された画像をパソコンに保存する方法を確認していきましょう。

Beautiful Soupを使って画像ファイルのリンクを取得
今まではSeleniumだけを使ってスクレイピングを進めてきました。しかし最初にSeleniumのスクレイピングでの使い方で説明したとおり、Seleniumはブラウザを経由して処理を行うので、処理速度が遅いのが難点です。
ということで、SeleniumはJava Scriptを利用したページの読み込みやログインなど、Seleniumを使わなければいけないケースのみで利用し、後は別のライブラリを利用する方が望ましいです。
ここでは画像のリンクの取得について、Beautiful Soupと一緒に利用する方法も確認していきましょう。Beautiful Soupの詳しい説明は、「図解!Beautiful SoupでWEBスクレイピング徹底解説!」を参照ください。
ポール・ニックレンさんのページで表示された画像について、それぞれのリンクを取得していきます。
前の章で記述しました画面スクロールするコードに対して、Beautiful Soupで画像のリンクを取得するコードを追加したものは、次のようになります。
追加・変更された箇所の背景色を変えています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | from bs4 import BeautifulSoup if error_flg is False: try: post_count = driver.find_element_by_xpath('//span[text()="投稿"]').text post_count = post_count.replace('件', '').replace('投稿', '').replace(',', '') print("投稿件数: " + post_count) post_count = int(post_count) if post_count > 12: scroll_count = int(post_count/12) + 1 try: all_images = [] for i in range(scroll_count): #画像リンクの取得 soup = BeautifulSoup(driver.page_source, 'html.parser') for image in soup.find_all('img'): all_images.append(image) #画面スクロール driver.execute_script('window.scrollTo(0, document.body.scrollHeight);') sleep(2) #取得した画像リンクの確認 all_images = list(set(all_images)) for index, image in enumerate(all_images): print("画像番号: " + str(index)) print("image['src'] = " + image['src'], end = "\n\n") except Exception as e: error_flg = True print(e) print('画面スクロール中にエラーが発生しました。') sleep(10) except Exception: error_flg = True print('投稿数が取得できませんでした。') |
コードを詳しく解説していきます。
まずはBeautifulSoupをインポートします。
空のリストを作成し、変数all_imagesに格納しています。
今後、取得した画像のリンクは、この中に格納していきます。
そして次のコードで画面をスクロールさせながら、画像リンクの取得を行っています。
#画像リンクの取得
soup = BeautifulSoup(driver.page_source, 'html.parser')
for image in soup.find_all('img'):
all_images.append(image)
#画面スクロール
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
sleep(2)
画像リンクの取得に関するコードについて、さらに詳しく見ていきます。
page_sourceでは、現在表示しているページのコードをダウンロードすることができます。
このダウンロードしたコードをBeautifulSoup()を用いて解析します。BeautifulSoup()の記述方法は以下です。
1つ目の引数には、解析対象のHTML/XMLを渡します。
2つ目の引数として解析に利用するパーサー(解析器)を指定します。
| パーサー | 引数での指定方法 | 特徴 |
| Python’s html.parser | “html.parser” | 追加ライブラリが不要 |
| lxml’s HTML parser | “lxml” | 高速に処理可 |
| lxml’s XML parser | “xml” | XMLに対応し、高速に処理可 |
| html5lib | “html5lib” | 正しくHTML5を処理可 |
この中でも、今回はPythonの標準ライブラリに入っており、追加でライブラリのインストールが不要なPython’s html.parserを利用します。
BeautifulSoup()に先ほど取得した現在のページの情報とパーサー"html.parser"を渡してあげます。
これらの情報を用いてBeautiful SoupではHTMLを解析していきますが、必要な箇所を解析するために、該当箇所を指定、検索する方法がいくつかあります。
その中の1つがfind_allメソッドになります。
find_all()では、引数に一致する 全ての 要素を取得します。
HTMLでは画像へのリンクはimgタグに格納されます。ここではfind_all()への引数として’img’を渡し、全てのimgタグの情報を取得しています。
all_images.append(image)
そして取得した1つ1つのimgタグの情報を、先ほどの変数all_imagesにappend()で格納しています。
最後にこれらの取得したimgタグの情報を画面に表示しています。
all_images = list(set(all_images))
for index, image in enumerate(all_images):
print("画像番号: " + str(index))
print("image['src'] = " + image['src'], end = "\n\n")
表示する画像ファイルはsrc属性に格納されていますので、この属性の内容を表示しています。
これらのコードを実行結果は次のようになります。
画像番号: 0
image['src'] = https://scontent-nrt1-1.cdninstagram.com/v/t51.12442-15/e15/c78.267.1001.1001a/s150x150/28763943_1983888588605962_9076461727012356096_n.jpg?_nc_ht=scontent-nrt1-1.cdninstagram.com&_nc_cat=110&_nc_ohc=FfOntf-v-AAAX8yWzWb&oh=eda4656e99230611435d472b7e022dca&oe=5E2F255A
画像番号: 1
image['src'] = https://scontent-nrt1-1.cdninstagram.com/v/t51.2885-15/e35/c0.248.639.639a/81981387_167465077808057_7132941963051318183_n.jpg?_nc_ht=scontent-nrt1-1.cdninstagram.com&_nc_cat=1&_nc_ohc=FBNuWmzPOSwAX9kp3ly&oh=ca38765907c2d4f67bfefa435ae303a1&oe=5E2EF61F
…
…(以下、省略)
画像のリンクが順番に表示されています。
Requestsを使って画像ファイルをダウンロード・保存
先ほどはBeautiful Soupも使い画像のリンクを取得しました。ここでは画像のリンクを元にRequestsを使って画像をダウンロードし、パソコンに保存しましょう。
Requestsの詳しい説明は、「図解!PythonのRequestsを徹底解説!」を参照ください。
取得した画像リンクを元に、画像をダウンロード・保存するコードは、次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import requests import re import os import shutil path = r"C:\Users\Yoshi\Instagram\photo" if error_flg is False: all_images = list(set(all_images)) for index, image in enumerate(all_images): filename = 'image_' + str(index) + '.jpg' image_path = os.path.join(path, filename) image_link = image['src'] #URLのチェック URL_PTN = re.compile(r"^(http|https)://") res = URL_PTN.match(image_link) if res: #画像のダウンロード response = requests.get(image_link, stream=True) try: #画像の保存 with open(image_path, 'wb') as file: shutil.copyfileobj(response.raw, file) except Exception as e: print(e) print(str(index) + '番目の画像が見つかりませんでした。 ') print('画像へのリンク: ' + image_link) |
コードを詳しく解説していきます。
まずは必要なライブラリをインポートします。
import re
import os
import shutil
それぞれのライブラリについては、後でそのライブラリを使うコードと合わせて解説します。
画像ファイルの保存するフォルダを指定しています。ご自身のパソコンで好きなフォルダを指定してください。
前の章で取得したimgタグの情報は全て変数all_imagesに格納されています。そして、この内容を順次取り出してfor文で繰り返し処理を行います。
for index, image in enumerate(all_images):
変数indexには画像の順番が、imageにはimageタグの内容が格納されています。
そしてfor文の繰り返し処理の中では、まず次の処理を行っています。
最初に事前準備として、以下の情報をそれぞれの変数に格納します。
image_path:パソコンへ保存する際のフルパス(保存先のフォルダへのパス+ファイル名)
image_link:データを取得する画像のリンク(URL)
まず変数filenameには画像のファイル名を格納します。
次に画像ファイルの保存するフォルダへのパスとファイル名を合わせたフルパスを、変数image_pathに格納します。
またimgタグの中からsrc属性の情報を取得し、変数image_linkに格納します。
さらに取得した画像のリンクが正しいURLの形式になっているかチェックします。
チェックには正規表現のreモジュールを使い、変数image_linkに格納された文字列の最初の文字が、http://、もしくは https://から始まっているかどうかをチェックしています。
URL_PTN = re.compile(r"^(http|https)://")
res = URL_PTN.match(image_link)
そして正しいURLの形式になっている場合のみ、以降の画像のダウンロード処理へと続けていきます。
#画像のダウンロード
正規表現の詳しい説明は、「図解!Python 正規表現の徹底解説!」を参照ください。
これで事前準備は終わりました。次にこれらの情報を元に画像を取得します。
画像のダウンロードのコードは次になります。
response = requests.get(image_link, stream=True)
画像のダウンロードにはライブラリRequestsを使います。事前にインストールも必要になりますので、Requestsの記事をご確認ください。
>> 図解!PythonのRequestsを徹底解説!
requestsにはいくつかメソッドがありますが、ここではサーバから情報を取得するのに使用するget()を使います。
requests.get()の記述方法は次のとおりです。
引数として取得元のURL、その他の任意の引数を渡します。ここでは任意の引数の1つstreamにTrueを渡し、イテレータで結果を取得しています。
サーバから返ってきたレスポンスは、responseオブジェクトの属性で確認することができます。
画像のダウンロードが終わりましたら、画像を指定したフォルダに保存します。
with open(image_path, 'wb') as file:
shutil.copyfileobj(response.raw, file)
書き込み用のバイナリモードでファイルをオープンします。ファイルが無ければ新規作成されます。
書き込み先は変数image_pathで指定した場所になります。
response.rawには、先ほどrequests.get()で取得した画像データが入っています。そしてshutil.copyfileobj()でresponse.rawの内容をオープンしたファイルへコピーし格納します。
上記のコードを実行すると、

画像が指定されたフォルダに格納されているのがわかります。
このようにして、インスタグラムから取得した画像ファイルをパソコンのフォルダに格納することができました。
関連記事です。
Pythonを使ったスクレイピングについての詳細は、こちらをご覧ください。