
WEBスクレイピングとは、WEBサイトから情報を自動的に取得し、必要に応じて、情報の加工などを行うことです。取得したデータは、ファイルやデータベースに保存します。
WEBサイトに公開されている情報は、テキスト情報や画像、動画など様々な情報がありますが、その中の1つとしてテーブルに格納されている情報があります。
Pythonのデータ分析用ライブラリPandasではread_htmlという関数を利用して、WEBサイト上のテーブルに格納されているデータを非常に簡単に取得することができます。
また取得したデータはPandasのDataFrame(データフレーム)と呼ばれるデータ構造を利用してすぐに分析やグラフ化、データ保存することもできます。(DataFrameの詳しい説明は、こちら「Pandas DataFrameの基本」を参照ください。)
これらPandasを用いたWEBスクレイピング方法は、WEBサイト上のテーブルから、
- 統計情報を取得し、マーケットリサーチに活用したい。
- 他社の情報を取得し、競合分析に活用したい。
- 株価情報を取得して、トレンドを把握し分析に利用したい。
という場合に利用すると便利です。
ここではまず、read_html()の基本となる使い方を確認していきましょう。そして、最後に具体的な利用例として、Yahoo Financeから米国株の株価情報を取得、グラフ化し、データを保存する方法も見ていきましょう。日本株の取得方法については、「スクレイピングで株価の取得」を参照ください。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
pandas.read_html()を使うための準備(インストール)
read_html()を利用するには、WEBスクレイピング用のライブラリBeautifulSoup4、html5lib、lxmlをインストールしておく必要があります。
これらのライブラリは、標準ではインストールされていませんので、pipやcondaを利用して別途インストールする必要があります。
pipを利用してインストールする場合は、以下のコマンドを入力してください。
pipの詳しい説明は「Pythonでの外部ライブラリの追加インストール方法」を参照ください。
またcondaを利用してインストールする場合は、次のコマンドを入力してください。
condaの詳しい説明は「Anacondaでの外部ライブラリの追加インストール方法」を参照ください。
これでインストールは終わりました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
pandas.read_html()の基本的な使い方
これからread_html()の基本となる使い方を紹介していきます。
read_html()の記述方法は以下です。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| URL | 必須 | 読み込み対象のURL |
| header | 任意 | ヘッダに指定する行 |
| index_col | 任意 | インデックスに指定する列 |
| skiprows | 任意 | 読み飛ばす行数 |
WEBスクレイピングによるYahoo Financeから米国の株価情報の取得
これからread_html()の使い方の例を紹介していきます。
ここでは、Yahoo Finance(https://finance.yahoo.com/quote/AAPL/history?p=AAPL&.tsrc=fin-srch)からアップルの株価情報を取得してみます。
まず今回は、メインページのトップニュースのタイトル(赤線で囲った箇所)とそのURLを取得したいと思います。
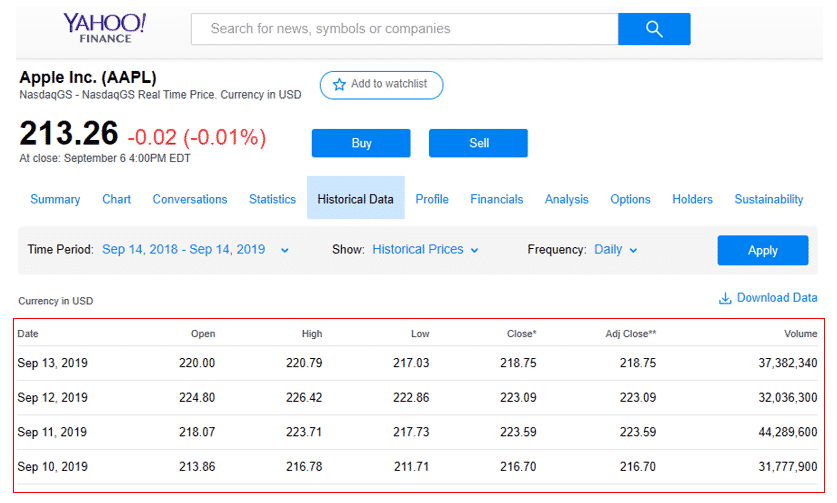
このページでは、1年間のアップルの株価が表示されています。
最初にpandasをインポートします。
次に今回読み込むURLを変数urlに格納します。
そして、read_html()に対して、変数urlを渡し、引数headerに0行目を指定します。取得した結果は、変数dataに格納されます。
それではWEBページから取得したテーブルの情報を表示してみましょう。結果はリストの形式で取得されます。例えば、読み込み対象のWEBページに複数のテーブルがある場合、1つ目のテーブルは[0]、2つ目のテーブルは[1]で確認することができます。
ここではテーブルが1つしかありませんので、[0]で確認します。head()を使って最初の5行を表示してみましょう。
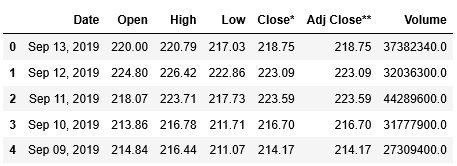
合わせて、tail()を用いて、後ろからの5行も内容を確認しましょう。
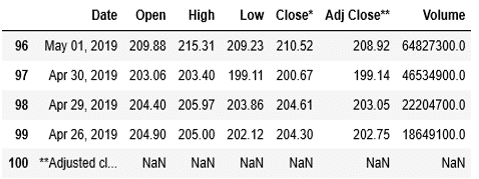
ここまでで、Yahoo Financeからアップルの株価を取得することができました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
WEBスクレイピングで取得した株価情報のグラフ表示
取得データの問題点の確認
次に、これらの取得した情報を用いてグラフを表示してみたいと思います。但し、取得したデータを確認した結果、2つの問題があるようです。
- 数値が入るべき列に欠損値を示すNaN(Not a number)が入っている行がある。
- 列Dateに格納されている日付が、Apr 26, 2019のように文字列になっていて、時系列にグラフを表示できない。
このような問題はWEBスクレイピングでは良く起こり得ます。日付、数値、欠損値にかかわらず、WEBサイト上はテキスト型で表示することができます。
しかし、その情報をグラフ化したり、適切な形式で保存しようとすると、これらの情報を適切に処理してからでないと、グラフ表示やデータ保存することはできません。1つ1つ対処していきましょう。
不要な行の削除
まず1つ目のNanが含まれている行を削除するにはdropna()を利用します。記述方法は次のようになります。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| axis | 任意 | 0:欠損値を含む行を削除 1: 欠損値を含む列を削除 |
| inplace | 任意 | True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 |
dropna()で欠損値NaNが含まれている行を削除します。その際に引数inplaceにはTrueを指定して、実行結果をDataFrameに保存します。そして最後の5行を表示して、NaNが削除されていることを確認してみましょう。
...: data[0].tail()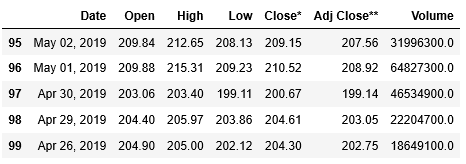
最終行にあった欠損値NaNを含む行が消えています。
日付型インデックスの設定
次に2つ目の問題である「列Dateに格納されている日付が、Apr 26, 2019のように文字列になっていて、時系列にグラフを表示できない。」に対応していきます。
ここでは文字列を日付型に変換するdatetime. strptime()を使います。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| 文字列 | 必須 | 日付型に変換したい文字列 |
| 日付書式 | 必須 | 文字列の書式を次の記号で指定(文字列がどのような書式で書かれているかを指定) %b:月名の短縮形Aprなど %d:0埋めした10進数の日にち 01、02など %Y:西暦4桁の10進表記 2019、2020など |
まずはdatetimeをインポートします。
次にstrptime()を元に列Dateに格納されている日付を示した文字列を日付型に変換し、元のDataFrameに対して列Date2を追加して日付型の値を格納します。
列Dateに格納されている日付が、Apr 26, 2019の書式ですので、strptime()の引数には、"%b %d, %Y"を指定しています。
また[dt.strptime(i, "%b %d, %Y") for i in data[0]["Date"]]の箇所では、リスト内包表記という方法を用いています。
data[0]["Date"]に格納されている値(日付を示した文字列)をfor文で1行目から順に読み込んで変数iに格納し、その値がstrptime()で日付型に変換しています。
その結果は、全体が[ ]で囲われていますのでリスト型となり、リストの中には、全ての行の文字列が日付型に変換された結果が格納されています。
まずは列Date2に格納した値を確認してみましょう。
0 2019-09-13
1 2019-09-12
2 2019-09-11
3 2019-09-10
4 2019-09-09
Name: Date2, dtype: datetime64[ns]
日付型で値が格納されていることがわかります。変換がうまくいったようです。
そして、data[0]の最初の5行を確認します。
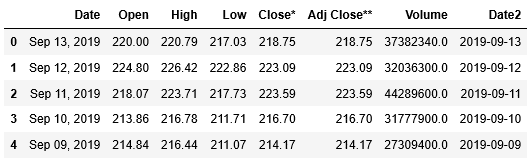
列Date2が追加されていることも確認できました。これで全ての問題は解決されました。
グラフの作成に取り掛かる前に、列Date2をインデックスに指定します。(DataFrameへのインデックスの設定に関する詳しい説明は、「Pandas DataFrameへのインデックスの指定と削除、変更」を参照ください。)
インデックスの設定にはset_index()を利用します。また引数inplaceにTrueを指定して、インデックス設定の実行結果をDataFrameに保存します。
data[0].head()
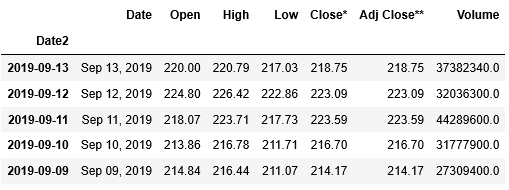
列Date2がインデックスに指定されました。
株価グラフの表示
それでは、グラフを表示してみましょう。DataFrameからグラフを表示するには、plot()を使えば簡単にできます。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| title | 任意 | グラフのタイトル |
| grid | 任意 | 目盛線の表示有無 |
| kind | 任意 | グラフの種類。何も指定しなければ’line’ ‘line’:折れ線グラフ ‘bar’:棒グラフ ‘scatter’:散布図 ‘pie’:円グラフ |
ここでは、調整後の株価であるAdj Close**を縦軸に、日付を横軸にして折れ線グラフを描きます。またタイトルと目盛線も追加しましょう。
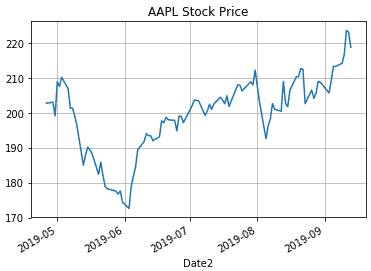
このようにして、Yahoo Financeから取得したアップルの株価を元にグラフを描画することができました。
WEBスクレイピングで取得した株価情報の保存(CSVファイル)
最後に取得した株価のデータを後から確認できるよう、CSVファイルに保存していきましょう。
DataFrameに保持しているデータをCSVファイルへ書き込むには、to_csvを使います。
CSVファイルへの書き込みに関する詳しい説明は、こちら「Pandas Excel、CSVファイルの読み込み、書き込み(出力)」を参照ください。
それでは先ほど読み込んだdf_salesの内容を、ファイル名”AAPL_Stock.csv”で、ディレクトリは指定せずに作業を行っているディレクトリにCSVファイルとして保存します。
保存されたCSVファイルをEXCELで開いてみると、次のように表示されました。
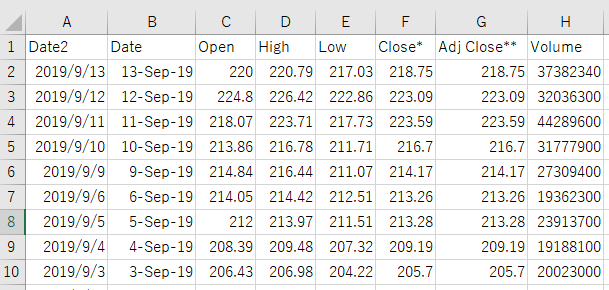
このようにして、Yahoo Financeから取得した株価情報を保存することができました。
関連記事です。
Pythonを使ったスクレイピングについての詳細は、こちらをご覧ください。













