
Pandas(パンダス)とは、データを効率的に扱うために開発されたPythonのライブラリの1つで、データの取り込みや加工・集計、分析処理に利用します。
Pandasには2つの主要なデータ構造があり、Series(シリーズ)が1次元のデータ、DataFrame(データフレーム)が2次元のデータに対応します。
実務で利用するデータは2つの軸で表される2次元のデータが多いので、DataFrameを利用する機会は非常に多く、DataFrameを理解することは、データを効率的に扱う上でとても重要になります。
この記事では、まずはDataFrameの基本的な使い方を確認した上で、最後にDataFrameを用いたデータ分析の事例を確認していきましょう。
Pandasについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用ください。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つデータ分析・可視化入門」(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
DataFrame(データフレーム)とは
DataFrameは2次元のデータに対応するデータ構造で、次のように行と列で表現され、複数の行と列が存在します。また、それぞれの列に対して、文字列型や数値型など、一様なデータ型のデータが格納されています。
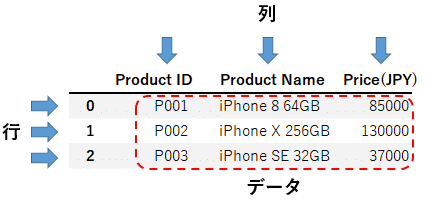
またDataFrameでは、列には列名が、行には行名(インデックス)が付けられており、それぞれの列名や行名を指定してデータを取得し、集計や加工に利用することができます。

なお、DataFrameから取り出した1行や1列の情報は、1次元のデータ構造であるSeriesに対応します。Seriesの詳しい説明は、「Pandas Seriesを徹底解説!」を参照ください。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
DataFrameの作成方法
DateFrameは、リスト、ディクショナリ、NumPyのndarrayなどから作成することができます。またCSVファイルなど、ファイルに格納された情報をDataFrameに取り込むこともできます。
DataFrameは、次のように定義します。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| data | 必須 | DataFrameに格納するデータを配列などで指定 |
| index | 任意 | 各行の行名(インデックス)を配列などで指定 ※何も指定しなければ、1行目から順に0,1,2と連番が振られます。 |
| columns | 任意 | 各列の列名を配列などで指定 ※何も指定しなければ、1列目から順に0,1,2と連番が振られます。 |
リストからDataFrameの作成
まず初めに、リストを元にDataFrameを作成していきます。リストの詳しい説明は、「リスト(List)/配列の使い方」から参照ください。
リストlist1に3つの文字列「”a1”, “a2”, “a3”」を格納し、pd.DataFrameの引数dataにlist1を渡します。
1 2 3 | import pandas as pd list1=["a1","a2","a3"] pd.DataFrame(data=list1) |

実行した結果、一番上に0という数値とその下に横線が、その下には1列目に0, 1, 2、2列目にa1, a2, a3が表示されています。
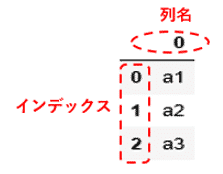
まず横線以下に表示されている1列目の数値0, 1, 2はインデックスで、引数indexに何も渡さないと、デフォルトでは0から始まる連番の数値が上の行から順に設定されます。
2列目には、引数dataに渡したリストlist1の値a1, a2, a3が表示されています。Seriesと同様、DataFrameでも、それぞれの行に対応するインデックスが付くかたちでデータが格納されています。
このインデックスを指定することで、指定した行のデータを取り出すことができます。詳細は後述致しますが、例えば、インデックス0を指定すると、対応する行のデータa1を取得でき、インデックス2を指定すると、対応する行のデータa3を取得できます。
また一番上に表示されている0は列名で、その下のa1, a2, a3に対応する列の名称を表しています。こちらもインデックスと同様、引数columnsに何も渡さないと、デフォルトでは0から始まる連番の数値が左の列から順に設定されます。
NumpyのndarrayからDataFrameの作成
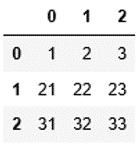
次に、NumPyで作成したndarrayからDataFrameを作成してみましょう。NumPyの詳しい説明は、「NumPyのインストールから使い方徹底解説」からご参照ください。
1 2 3 | import numpy as np arr1 = np.array([[1,2,3], [21,22,23], [31,32,33]]) pd.DataFrame(data=arr1) |
辞書からDataFrameの作成
そして、辞書(ディクショナリ)からDataFrameを作成する例も確認していきましょう。
辞書の詳しい説明をご覧になる場合、こちらのリンク「Dictionary(辞書)」から参照ください。
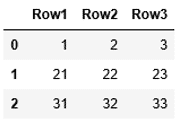
辞書のキーと合わせて、列単位でデータを設定していくかたちになります。そしてキーRow1、Row2、Row3が列名として設定されます。
1 2 | dict1=dict(Row1=[1,21,31], Row2=[2,22,32], Row3=[3,23,33]) pd.DataFrame(data=dict1) |
行名(index)・列名(column)を指定してDataFrameの作成
今度はインデックスや列名を指定してDataFrameを作成してみましょう。
まずはリストlist1に3行3列のリスト[[1,2,3],[21,22,23],[31,32,33]]を格納し、pd.DataFrameの引数dataにリストlist1を設定します。
次に、リストindex1にインデックス["Row1", "Row2", "Row3"]を格納し、引数indexにリストindex1を渡します。また、リストcolumns1に列名["Col1", "Col2", "Col3"]を格納し、引数columnsにリストcolumns1を渡します。
1 2 3 4 | list1=[[1,2,3], [21,22,23], [31,32,33]] index1 = ["Row1", "Row2", "Row3"] columns1 =["Col1", "Col2", "Col3"] pd.DataFrame(data=list1, index=index1, columns=columns1) |
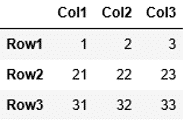
このようにインデックス、列名を指定すると、今回は連番では無く、1行目から順にRow1、Row2、Row3と指定したインデックスが設定され、また列名も1列目から順にCol1、Col2、Col3と設定されました。
関連記事です。
EXCELやCSVからデータをDataFrameに読み込む方法に関して、詳しい説明はこちらをご覧ください。

SeriesからDataFrameへの変換・DataFrameの列を抽出しSeriesを作成
SeriesからDataFrameへ変換することも、DataFrameの列の中から1つの列を抽出しSeriesを作成することもできます。
詳しい説明は、それぞれ以下のリンクを参照ください。
>> SeriesからDataFrameへの変換方法
>> DataFrameの列を抽出しSeriesを作成する方法
DataFrameへの行・列の追加と削除
DataFrameへの行の追加(append)
DataFrameに行を追加するには、追加したいデータのDataFrameを作成し、既存のDataFrameに対して、appendを利用して行を追加します。
appendは、次のように記述します。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| 追加するDataFrame | 必須 | 既存のDataFrameに追加するDataFrame |
| ignore_index | 任意 | True:インデックスを新たに振りなおす False:元のDataFrameのインデックスを継承する。 |
| inplace | 任意 | True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 |
引数ignore_indexは、Trueを渡した場合、設定してあるインデックスは使われずに、新たに0から番号が再設定されます。Falseを渡した場合、前のインデックスが変更されずに残ります。引数ignore_indexを省略すると、Falseになります。
それでは例を見てみましょう。まずは既存のDataFrameに該当するdf1を用意します。
1 2 3 4 5 6 | list2 = [["P001", "iPhone 8 64GB", 85000], ["P002", "iPhone X 256GB", 130000], ["P003", "iPhone SE 32GB", 37000]] columns2 = ["Product ID", "Product Name", "Price (JPY)"] df1 = pd.DataFrame(data=list2, columns=columns2) df1 |

次に追加するDataFrameを定義します。列名は同じですので、先ほど定義したリストcolumns2を使います。
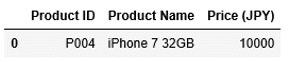
1 2 3 | df2 = pd.DataFrame(data = [["P004", "iPhone 7 32GB", 10000]], columns = columns2) df2 |
最後に、既存のDataFrameであるdf1に対して、appendを利用しdf2を追加します。ignore_indexは、Trueにしてインデックスの番号を振り直します。(参考までにFalseにすると、インデックスの番号はそのまま残り、上から順に0、1、2、0となります。)
1 2 | df1=df1.append(df2, ignore_index = True) df1 |
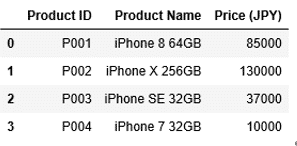
このようにして、DataFrameに対して行を追加することができました。
関連記事です。
DataFrameへの行の追加に関して、詳しい説明はこちらをご覧ください。

DataFrameへの列の追加
今度は列を追加してみましょう。列の追加は、次のようにDataFrameに対して列名を指定して、対象の列の情報をリストで渡します。
1 2 | df1["Screen Size (in.)"] = [4.7, 5.8, 4, 4.7] df1 |
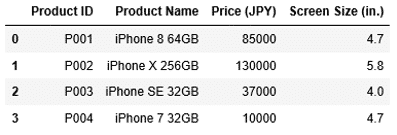
実行結果から、列「Screen Size (in.)」が新たに追加されたことがわかります。
DataFrameから行・列の削除(drop)
次にDataFrameからのデータの削除方法を見ていきましょう。
削除はdropを利用し、引数には削除したい要素のインデックスを渡します。その他にもよく利用する引数がありますが、詳細はこの後に紹介します。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| インデックス | 必須 | 削除する行をインデックス番号で指定する。複数指定する場合、リストでの指定も可能。 |
| axis | 任意 | 0:行を削除する。 1:列を削除する。 ※何も指定しなければ、0となる。 |
| inplace | 任意 | True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 |
先ほど作成した以下のDataFrameのdf1から、インデックス2の行を削除します。
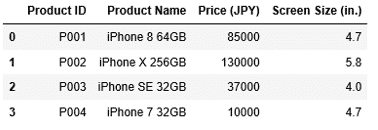
dropに削除したい行のインデックス2を設定し実行します。
1 | df1.drop(2) |
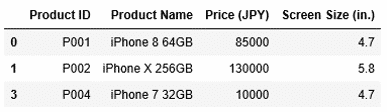
実行結果を確認すると、該当行が削除されました。
但し、このままでは、もう一度df1の内容を確認すると、先ほど削除した行が復活しています。
1 | df1 |
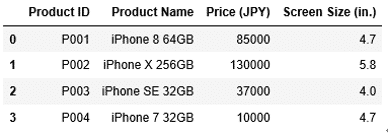
削除の実行結果をdf1に保存するには、dropには引数inplaceというものがあり、inplaceに対してTrueを渡してやる必要があります。何も指定しなければ、Falseとなり、先ほどのように実行結果が保存されません。
それでは、引数inplaceにTrueを渡して再実行します。今回は、df1からインデックス2、3の複数の行を削除してみましょう。複数の行を指定する場合、インデックスをリストで指定します。この場合は、[2, 3]を指定します。
1 2 | df1.drop([2, 3], inplace = True) df1 |
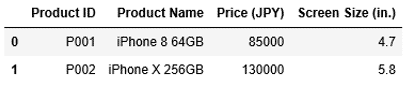
引数inplaceにTrueを指定してdropを実行した後、DataFrameの中身を確認すると、削除した結果が保存されていることがわかりました。
DataFrameは、行と列とで表されるので、行だけではなく、列を削除したい場合も出てきます。その場合はどのようにすればいいのでしょうか。
列を削除する場合は、dropの引数axisで1(列)を指定します。何も指定しなければ、0(行)を指定したことになります。
それでは、列"Screen Size (in.)"を削除してみましょう。この場合は、dropにはインデックスの代わりに列名"Screen Size (in.)"を渡し、また引数axisに1を指定します。
1 2 | df1.drop("Screen Size (in.)",axis=1,inplace=True) df1 |

列"Screen Size (in.)"が削除されました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
DataFrameへのインデックス指定・変更・解除
DataFrameへのインデックス指定
インデックスについては、DataFrame作成時だけでなく、後から特定の列をインデックスに指定することもできます。
各行の情報をユニークに指定できる列をインデックスに指定することで、インデックスを指定して情報を取り出しやすくすることができます。
インデックスは一度設定すると変更できませんので、変更が発生しない列に設定すべきです。(但し、設定したインデックスを外して、再度設定し直すことは可能です。)
インデックスの指定には、set_indexを使います。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| インデックス | 必須 | インデックスとなる列名を指定する。 ※複数の列をインデックスに指定することも可能で、その場合、リストで指定する。 |
| inplace | 任意 | True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 |
例として、次のような商品マスタの情報を格納するDataframe df1に対して、インデックスを設定してみましょう。
1 2 3 4 5 6 | list1 = [["P001","iPhone 8 64GB",85000], ["P002","iPhone X 256GB",130000], ["P003","iPhone SE 32GB",37000]] columns1 = ["Product ID","Product Name","Price (JPY)"] df1 = pd.DataFrame(data=list1,columns=columns1) df1 |

ここでは、df1に対してインデックスは0、1、2と連番になっています。
このような連番では、後々インデックスを指定して行の情報を取得したい場合、思い出すことができず、都度都度インデックスを調べるか、インデックスを使わずに、別の方法で検索することになり、不便です。
この商品マスタの行をユニークに識別する列は”Product ID”になりますので、”Product ID”をインデックスに設定しましょう。引数inplaceにはTrueを指定して、設定したインデックスをDataFrameに保存します。
1 2 | df1.set_index("Product ID",inplace=True) df1 |

列”Product ID”がインデックスに指定されました。
インデックスの解除・変更
インデックスの解除はreset_indexを使用します。インデックスの解除により、インデックスは連番に戻ります。inplaceは指定しなければFalseになり、インデックスの解除がDataFrameに保存されません。
reset_indexは、インデックスを変更したい場合にも利用されます。一度設定したインデックスは直接変更できません。set_indexで設定したインデックスが間違っていた場合、reset_indexで一度解除してから、再びset_indexで正しいインデックスに設定し直します。
先ほどインデックスに"Product ID"を指定したDataFrame df1のインデックスを解除します。
1 2 | df1.reset_index(inplace=True) df1 |

インデックスが解除され、連番に戻っていることがわかりました。
関連記事です。
DataFrameのインデックスに関して、詳しい説明はこちらをご覧ください。

DataFrameからデータの抽出方法
DataFrameに格納されたデータを取得する方法を確認していきます。
DataFrameからデータを抽出する方法は、大きく分けて次の3つに分類されます。
- 先頭、最後から行数指定での抽出
- 行・列番号を指定しての抽出
- 行・列名を指定しての抽出
- 条件指定での抽出
1つずつ確認していきましょう。
サンプルデータの読み込み
まず初めに次の情報を保持したCSVファイル「T_Sales_Header.csv」を読み込みます。実際にビジネスで利用される売上情報(ヘッダ)のイメージになります。
後から読み込みますが、売上明細の情報は別途あり、そこに商品、数量、単価、金額などの情報が格納されています。
このヘッダ情報には、Sales_Noとして売上伝票毎にAから始まる番号の連番が、Sales_dateには売上日が、Customer_IDには顧客IDが、Sales_Orgには販売組織IDが設定されています。顧客IDや販売組織IDは、別途マスタデータがあり、IDと共に名称などの情報を持っています。
| Sales_No | Sales_Date | Customer_ID | Sales_Org |
| A001 | 2018/6/22 | C03 | Q01 |
| A002 | 2018/6/23 | C14 | Q02 |
| A003 | 2018/6/24 | C30 | Q01 |
| A004 | 2018/6/25 | C01 | Q03 |
| A005 | 2018/6/26 | C01 | Q01 |
| A006 | 2018/6/27 | C02 | Q03 |
| A007 | 2018/6/28 | C02 | Q01 |
| A008 | 2018/7/5 | C03 | Q02 |
| A009 | 2018/7/24 | C04 | Q01 |
| A010 | 2018/7/12 | C04 | Q01 |
それでは、CSVファイル「T_Sales_Header.csv」からデータを読み込みます。(※CSVファイルは左のリンクから取得してください。)合わせてインデックスも指定します。
CSVファイルの読み込みはpd.read_csvを利用します。CSVファイルの読み込みは、「Pandas Excel、CSVファイルの読み込み、書き込み(出力)」を参照ください。
その際に引数として読み込むファイル名「T_Sales_Header.csv」とインデックスに列「Sales_No」を指定します。この読み込んだデータをDataFrameとして変数df_salesに格納します。
1 | df_sales = pd.read_csv("T_Sales_Header.csv", index_col = ["Sales_No"]) |
そして次にDataFrameを格納した変数df_salesを入力すると、格納されているデータが表示されました。
1 | df_sales |
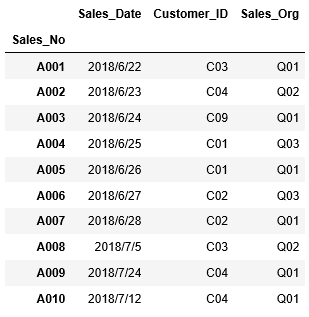
画面上部に表示されているのが、列名になります。「Sales_No」は一段下に表示されています。これはインデックスに指定されていることを示しています。
先頭、最後から行数指定での抽出
先ほどの例のように、全てのデータを表示するのは、データ件数が多くなると見づらくなります。多くの場合、一部のデータを確認すれば十分です。
そのような場合、DataFrameに格納したデータの内、最初の数行や最後の数行を表示して、確認していきます。
DataFrameのデータの内、最初から指定した行数を表示するには、headを利用します。引数では行数を指定し、head(行数)のように記述します。引数を省略した場合、最初の5行が表示されます。
headの引数に3を指定し、最初の3行を表示してみます。
1 | df_sales.head(3) |
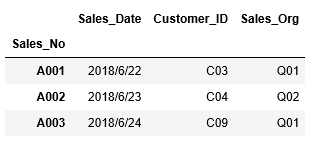
先ほどは先頭行から指定行数を表示しましたが、逆に最後から指定した行数を表示するには、tailを利用します。
引数では行数を指定し、tail(行数)のように記述します。引数を省略した場合、最後の5行が表示されます。
1 | df_sales.tail() |
ilocによる行・列番号を指定しての抽出
ilocを利用するとDataFrameから行・列番号を指定してデータを抽出することができ、加えて、スライシングも使うことができます。
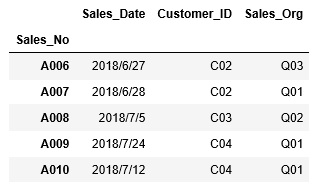
まずは行を指定してデータの抽出をしてみましょう。行番号は0から始まります。4行目から6行目を抽出する場合、ilocに引数3:6を渡します。
1 | df_sales.iloc[3:6] |
次に列を指定してデータを抽出します。こちらも列番号は0から始まります。全ての行の2列目の”Customer_ID”の値を取得する場合、行の指定を”:”(全行)、列の指定を1(2列目)とします。
1 | df_sales.iloc[:, 1] |
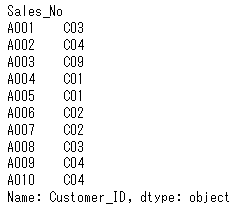
次のようなかたちで、行の範囲、列の範囲を指定して抽出することもできます。2~3行目の1~2列目のデータを抽出します。
1 | df_sales.iloc[1:3, 0:2] |
locによる行・列名を指定しての抽出
locを利用するとDataFrameからインデックス、列名を指定してデータを抽出することができます。スライシングも使うことができます。
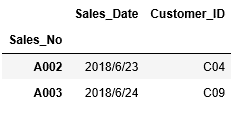
まずはインデックスを指定してデータの抽出をしてみましょう。A003~A007行のデータを抽出する場合、次のようにlocに引数"A003":"A007"を渡します。
1 | df_sales.loc["A003":"A007"] |
次に列を指定してデータを抽出します。全ての行の列”Customer_ID”の値を取得する場合、行の指定を”:”(全行)、列の指定を”Customer_ID”とします。
1 | df_sales.loc[:,"Customer_ID"] |

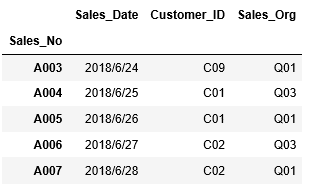
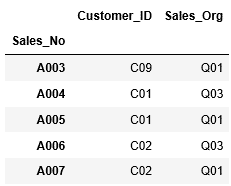
次のようなかたちで、行の範囲、列の範囲を指定して抽出することもできます。A002~A003行目の列”Customer_ID”、 "Sales_Org"のデータを抽出します。
1 | df_sales.loc["A003":"A007",["Customer_ID","Sales_Org"]] |
条件指定でのデータ抽出
次に条件を指定してDataFrameからデータを抽出する方法を試してみます。
列「Customer_ID」の値がC01の明細を抽出してみましょう。次のようにDataFrameに対して、列「Customer_ID」の値がC01となる条件を指定すると、各行について条件を満たすか否かを判定し、True/Falseで結果が返ってきます。
1 | df_sales["Customer_ID"] == "C01" |
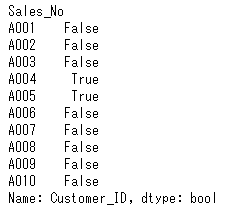
そして、この条件を[ ] の中に挿入します。すると、条件を満たすTrueの行の情報のみが表示されます。
1 | df_sales[df_sales["Customer_ID"] == "C01"] |
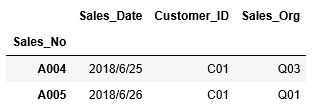
関連記事です。
1つのインデックスが設定されたDataFrameの検索方法に関して、詳しい説明はこちらをご覧ください。

様々な条件を組み合わせてDataFrameからデータを抽出する方法に関して、詳しい説明はこちらをご覧ください。


DataFrameのソート
DataFrameに表示されているデータは、様々な方法でソートすることができます。
主なソート方法は、
- インデックスによるソート
- 指定した列の値によるソート
また昇順、降順のいずれも指定することができます。
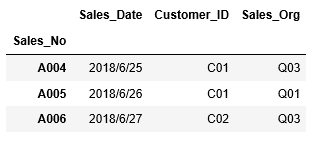
次のような商品マスタの情報を格納するDataframe df1を元に、様々なソートの方法を見ていきましょう。
1 2 3 4 5 6 7 | list1 = [["P001","iPhone 8 64GB",85000], ["P002","iPhone X 256GB",130000], ["P003","iPhone SE 32GB",37000]] columns1 = ["Product ID","Product Name","Price (JPY)"] df1 = pd.DataFrame(data=list1,columns=columns1) df1.set_index("Product ID", inplace=True) df1 |

インデックスによるソート
インデックスによるソートは、sort_indexを利用します。引数ascendingにTrueを指定すると昇順、Falseを指定すると降順にソートされます。何も指定しなければ、Trueの昇順になります。
それでは、先ほど定義したDataFrame df1をインデックス「Product ID」の降順でソートしてみます。引数ascendingにはFalse(降順)を指定します。
1 2 | df1.sort_index(ascending=False, inplace=True) df1 |

インデックス「Product ID」について、上から”P003”、”P002”、”P001”というように降順でソートされていることがわかります。
指定した列の値によるソート
指定した列の値によるソートは、sort_valuesを用います。引数byで値に基づくソートを行う対象の列を指定します。
DataFrame df1の列「Price (JPY)」の値を元に、昇順にソートします。引数ascendingに何も指定しなければ、昇順になります。
1 2 | df1.sort_values(by="Price (JPY)") df1 |
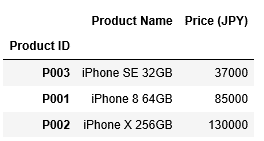
df1の列「Price (JPY)」の値について、上から37000, 85000, 130000と昇順に並んでいることがわかります。
関連記事です。
DataFrameのソートに関して、詳しい説明はこちらをご覧ください。

DataFrameを活用したデータ分析
最後にDataFrameを活用したデータ分析に関連する記事をいくつかご紹介いたします。この記事で学んだ基本を元に、これらの応用的なトピックに進んで頂ければと思います。
時系列データの集計・分析
この記事では、時系列データの集計・分析方法について学ぶことができます。日々の売上データを月、四半期、年度単位に集計し、分析する方法を確認します。

WEBスクレイピングによるデータ収集と分析
この記事では、WEBスクレイピングによりデータを取得する方法とその分析方法について学ぶことができます。


ピボットテーブル(クロス集計)による分析
この記事では、ピボットテーブル(クロス集計)を用いたデータ分析方法について理解を深めることができます。ピボットテーブルでは、行や列に項目を増やしたり、集計値を変えてみたりして、様々な切り口からデータを分析することができます。
複数のDataFrameを結合させての分析
この記事では、複数のDataFrameを結合させる方法について学ぶことができます。売上データをマスタデータと結合させ、データ分析していく方法を確認します。

関連記事です。
Pythonに関する重要なトピック全般について学んでいきたいと考えておられる方には、次のリンクをお勧めします。











