
DataFrameではSeriesと同様にある条件を満たすデータだけを抽出することができます。この章では、様々な条件指定でのデータ抽出の方法をみていきましょう。
まずは前章と同じCSVファイル「T_Sales_Header.csv」からデータを読み込みます。(※CSVファイルは左のリンクから取得してください。)合わせてインデックスも指定します。
取り込んだデータを変数df_salesに格納し、その中身を確認すると、
...: df_sales=pd.read_csv("T_Sales_Header.csv",index_col=["Sales_No"])...: df_sales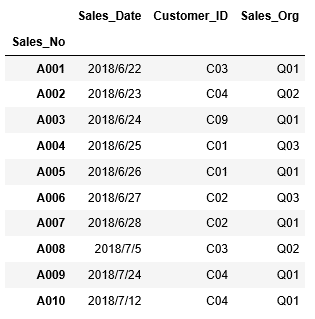
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
単一条件指定してDataFrameからデータ抽出(日時・日付・年月日での抽出)
最初に1つの条件を指定してDataFrameからデータを抽出する方法を試してみます。
列“Customer_ID”の値がC01の明細を抽出してみましょう。次のようにDataFrameに対して、列“Customer_ID”の値がC01となる条件を指定すると、各行について条件を満たすか否かを判定し、True/Falseで結果が返ってきます。
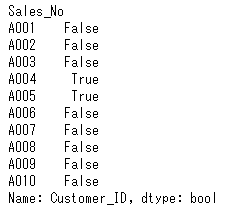
Seriesの時と同様、この条件を[ ] の中に挿入します。すると、条件を満たすTrueの行の情報のみが表示されます。
次に、日付で条件を指定し、日付がある範囲に収まるものを抽出してみましょう。
まずは事前準備として、先ほどのCSVのデータをDataFrameに読み込んだ際、日付は文字列型になっていますので、まずは日付型に変換します。
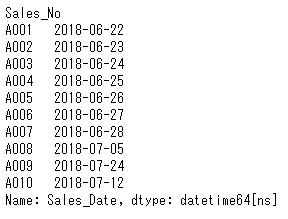
日付型への変換は、pd.to_datetimeを利用します。引数として日付に変換したい文字列、ここでは列"Sales_Date"の値なので、df_sales["Sales_Date"]を渡します。
そして列"Sales_Date"の値を確認すると、” dtype: datetime64[ns]”と日付型になっていることがわかります。
さらに事前準備として、日付や時刻に対して様々な操作をすることができるdatetimeモジュールから、datetimeクラスをインポートしておきます。
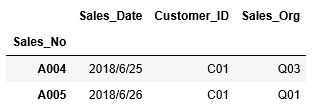
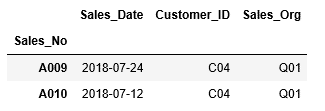
以上で準備が終わりましたので、それでは、列”Sales_Date”の値が2018/07/11以降の行の情報を抽出してみましょう。
まずはdatetimeを利用してdatetimeオブジェクトを作成します。
ここでは2018/07/11以降の日付の行を抽出するので、比較対象となる2018/07/11のdatetimeオブジェクトを作成します。
datetimeに対して、引数として年2018、月7、日11を渡します。時~マイクロ秒までの引数は省略可能です。
そして、列“Sales_Date”の日付が2018/07/11以降となる条件式「df_sales["Sales_Date"] > datetime(2018, 7, 11)」を作成し、この条件式を[ ] の中に挿入します。
すると、条件を満たす行の情報が表示されました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
複数条件/範囲を指定してDataFrameからデータ抽出
次は、複数の条件を指定してDataFrameからデータを抽出する方法を試してみましょう。
まずは注意点が3つあります。
1つ目は、利用する論理演算子が異なるということです。複数の条件を指定するには、条件文同士を論理演算子で繋げる必要がありました。
「10. 条件分岐(If文)」の章では、複数の条件を指定する場合、全ての条件を満たすものを抽出するには論理演算子andを用いて、いずれかの条件を満たすものを抽出するにはorを用いて、条件文同士を繋いでいました。
また他の論理演算子としてnotがあり、 not以降の条件式がTrueの時にFalse、Falseの時にTrueを返すというように、条件を反転させるものもありました。
但し、ここでは論理演算子andの代わりに&(アンパサンド)、orの代わりに|(バーティカルバー)、notの代わりに~(チルダ)を用いる必要があります。
2つ目は、比較演算子を使うときは条件ごとに括弧で囲む必要があります。括弧が無いとエラーになります。
3つ目は、条件文が3つ以上ある場合、演算子の優先順位に気を付ける必要があるということです。
優先順位が高い順から、~ (not)、& (and)、| (or)となり、順番によって結果が異なってきます。これを避ける為、予め優先したい処理を() 括弧で括った方が良いです。
これらの注意点を踏まえて、実際の例をみてみましょう。
まず始めに、| (or)を使って、Customer_IDがC01、もしくは、C03の情報を取得します。
注意点を踏まえて、比較演算子を使った条件文「df_sales["Customer_ID"]=="C01"」、「df_sales["Customer_ID"]=="C03"」をそれぞれ括弧で括り、また論理演算子は、| (or)を使って2つの条件文を繋げます。
...: (df_sales["Customer_ID"] == "C03")]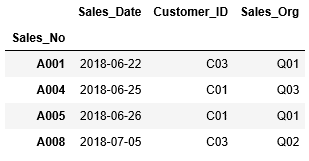
次に&(AND)を使って、Customer_IDがC03、かつ、Sales_Dateが2018/07/1以降の情報を抽出してみましょう。
...: (df_sales["Sales_Date"] > datetime(2018, 7, 1))]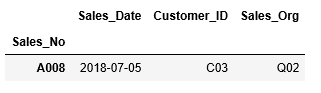
また~(NOT)を使って、Customer_IDがC03以外、かつ、Sales_Dateが2018/07/1以降の情報を抽出します
...: (df_sales["Sales_Date"] > datetime(2018, 7, 1))]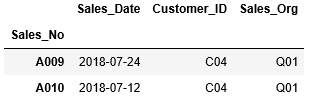
今度は3つの条件を繋げた例をみてみます。
Customer_IDがC03以外、もしくは、Sales_OrgがQ01のデータの中で、さらにSales_Dateが2018/06/29以前の情報を抽出します。
この場合、「Customer_IDがC03以外、もしくは、Sales_OrgがQ01のデータ」に当たる箇所が処理の1つの括りとなりますので、( ) 括弧で括ります。
...: (df_sales["Sales_Org"] == "Q01")) &...: (df_sales["Sales_Date"] < datetime(2018, 6, 29))]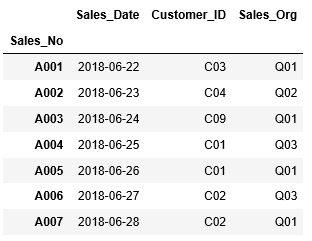
この場合、括弧を付けないと処理の優先順位が変わってきます。
...: (df_sales["Sales_Org"] == "Q01") &...: (df_sales["Sales_Date"] < datetime(2018, 6, 29))]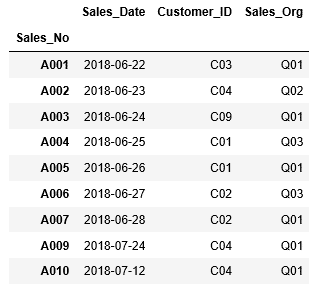
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。

DataFrame(データフレーム)の検索方法で、1つのインデックスが設定されたDataFrameの検索については、こちらをご覧ください。

複数のインデックスが設定されたDataFrame(データフレーム)に対しての検索方法については、こちらが参考になります。













