
Python3におけるWEBスクレイピングのやり方について初心者向けに解説した記事です。
Requests、Beautiful Soup、Selenium、Pandas、newspaper3kなどの基本的なライブラリの使い方を、サンプルコード付きのチュートリアル形式で、具体的な例を用いて解説していきます。
またこれらのライブラリについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
WEBスクレイピングとは、スクレイピングのやり方
WEBスクレイピングとは、WEBサイトからデータを自動的に取得し、必要な情報の抽出・加工などを行うことです。取得したデータは、ファイルやデータベースに保存します。
WEBスクレイピングでできること
WEBスクレイピングでは、様々な情報をWEBサイトから取得することができます。
この記事ではWEBスクレイピングを利用して、
- ニュースサイトからデータを取得し、自然言語処理を用いて要約し、これらの情報を保存する。
- Yahoo Financeから株価情報を取得し、グラフの描画とデータの保存を行う。
- Googleで検索条件を入力し、複数のページから検索結果を取得し保存する。
- インスタグラムにログインし、画面スクロールしながら全ての画像をダウンロードする。
- Yahooニュースのトップニュースから、タイトルとURLの一覧を取得する。
を行っていきたいと思います。これらのことがツールを使って自動的にできたら便利ですよね。
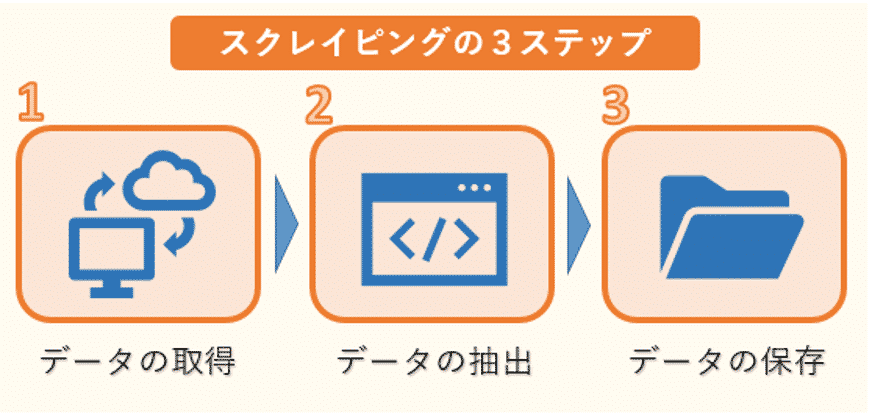
WEBスクレイピングの手順
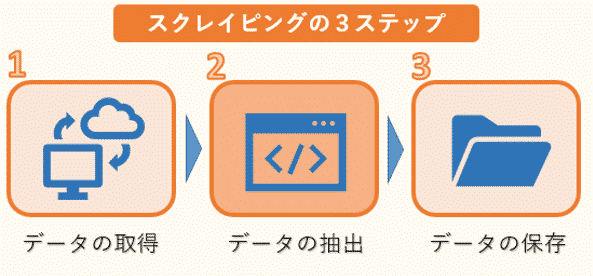
スクレイピングは、次の3ステップで行われます。
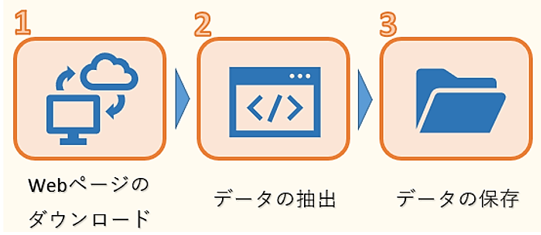
1つ目はWEBページのHTMLデータのダウンロードです。ただし、HTMLには必要な文章のデータだけでなく、タグなどのデータも混じっているので、必要なものだけを抽出する作業が必要になります。
そこで2つ目のデータの抽出が欠かせません。ここでは、複雑な構造のHTMLデータを解析し、必要なデータだけを抽出します。
そして最後に抽出したデータをデータベースやファイルなどに保存します。
スクレイピングに利用するライブラリ(Requests、Beautiful Soup、Selenium、Scrapy)
Pythonでデータ取得によく使われるライブラリとしては、Requests、Beautiful Soup、Selenium、Scrapyがあります。
先ほどのデータ取得の3ステップの中で、それぞれのライブラリがどこで使われるのかをまとめると次のようになります。
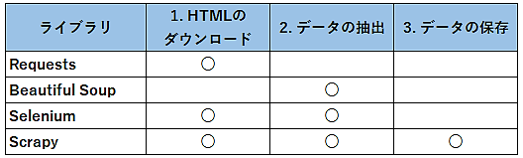
Requestsは1つ目のHTMLデータのダウンロードによく用いられます。PythonではRequestsを利用して、簡単にWebページからHTMLを自動的にダウンロードすることができます。
その後、取得したHTMLからBeautiful Soupなどの別のライブラリを用いて必要なデータのみを抽出します。
またSeleniumは、JavaScriptが使われている特殊なWebページからのHTMLデータのダウンロードや、サイトへのログインなどに使います。
Seleniumは、HTMLのダウンロードだけでなく、必要なデータの抽出も行うことができますが、ブラウザを操作してデータを取得しますので、動作が遅いことが難点です。従って、できるだけ必要最低限の箇所でSeleniumを使うことをお勧めします。
そしてこれら3つのステップを全てカバーするのがScrapyになります。Scrapyでは、コードは主にSpiderと呼ばれるクラスに記述していきます。Spiderにコードを記述すれば、後は他のものがうまく連動してくれて、必要な作業を行ってくれます。
但し、Scrapyについては、スクレイピング初心者の方にとっては、短い記事だけでは理解しづらい所もあります。従ってこの記事では、初心者の方でも比較的理解しやすいRequests、Beautiful Soup、Seleniumを中心に解説を進めていきます。
Scrapyの詳細については、以下の記事を参照ください。
>> 図解!Python Scrapy入門(使い方・サンプルコード付きチュートリアル)
またBeautifulSoup、Selenium、Requestsについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)(Udemyへのリンク)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pythonのスクレイピング環境の構築
本記事では、AnacondaとJupyter Notebook(もしくは、Jupyter Lab)を元にスクレイピングの環境を構築していきます。
AnacondaとJupyter Notebook(もしくは、Jupyter Lab)のインストールについて、詳細は以下のリンクを参照ください。
>> AnacondaでPython3をインストール(Windows/Mac編)
またJupyter Notebookの使い方については、以下のリンクを参照ください。
>> Jupyter Notebookの使い方
Jupyter Labの使い方については、以下のリンクを参照ください。
>> Jupyter Labの使い方
RequestsでHTMLデータの取得(ダウンロード)
requestsとは、HTTP通信用のPythonのライブラリです。主にWEBスクレイピングでHTMLやXMLファイルからデータを取得するのに使われます。
インターネット上に公開されているWEBサイトでは広くHTMLやXMLが使われており、これらの情報の取得に大変便利なライブラリです。
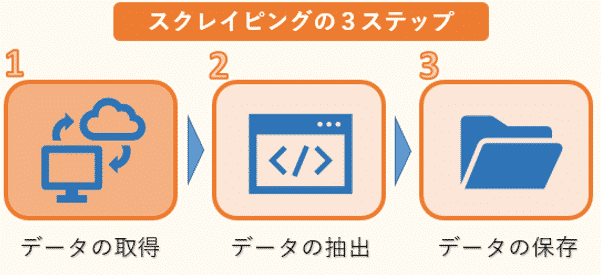
このWEBスクレイピングの3ステップの中で、requestsは1つ目のHTMLデータの取得によく用いられます。Pythonではrequestsを利用して、簡単にWEBサイトからデータを自動的に取得することができます。
その後、取得したデータからBeautiful Soupなどの別のライブラリを用いて必要な情報のみを抽出します。
Requestsの基本的な使い方
これからrequestsの基本となる使い方を紹介していきます。requestsの利用にあたってはインストールやインポートが必要になります。詳しい説明は、「図解!PythonのRequestsを徹底解説!」を参照ください。
requestsで主に使われるメソッドには、次のようなものがあります。
| メソッド | 説明 |
| get() | サーバから情報を取得するのに使用する。 |
| post() | サーバへ情報を登録する時に使用する。 |
| put() | サーバの情報を更新する時に使用する。 |
| delete() | サーバの情報を削除する時に使用する。 |
この中でも、WEBスクレイピングに使われるget()を紹介していきます。
requests.get()の使い方
get()は、サーバからHTML、XMLなどの情報を取得するのに使用します。
requests.get()の記述方法は以下です。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| URL | 必須 | 読み込み対象のURL |
| headers | 任意 | ヘッダとして送信する内容を辞書で指定 |
| timeout | 任意 | リクエストのタイムアウト時間 |
| params | 任意 | URLのクエリパラメータを辞書で指定 |
| cookies | 任意 | クッキーとして送信する内容を辞書で指定 |
戻り値としてresponseオブジェクトが返ってきます。responseオブジェクトには様々な属性値があり、主なものは次になります。
| 属性 | 説明 |
| status_code | ステータスコード |
| headers | レスポンスヘッダの内容 |
| content | レスポンスのバイナリデータ |
| text | レスポンスの内容 |
| encoding | エンコーディング |
| cookies | クッキーの内容 |
ここではget()の使い方の例として、yahoo news のページを取得してみましょう。
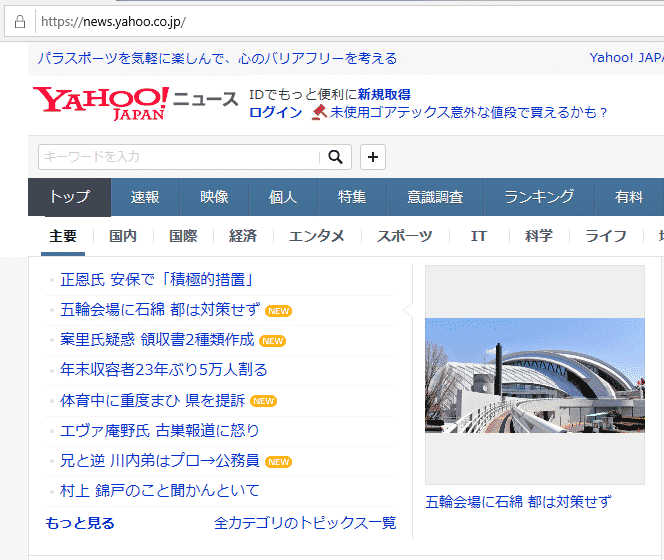
requests.get()を利用して、yahoo newsサイトの情報をダウンロードします。変数urlを定義し、確認したいWEBサイトのアドレスを渡します。
次に、requests.get()に対してurlを渡しています。request.get()で指定されたwebの情報を取得し、その結果は、変数responseに格納します。
1 2 | url = 'https://news.yahoo.co.jp' response = requests.get(url) |
試しに取得した内容を表示してみましょう。textで内容を確認することができます。ここでは最初の500文字だけを表示しています。
1 | response.text[:500] |

取得したHTMLのコードが表示されました。この中にはtitle「Yahoo!ニュース」なども含まれています。
また取得した全ての内容を表示するとわかりますが、主要ニュースのタイトルなど、画面に表示されている内容も取得できていることがわかります。
1 | response.text |
※一部抜粋
このようにWEBサイトの大量の情報が取り込まれています。
これら取得したデータの中から、ニュースのタイトルやURLなどの必要な情報を取得するのは、次のステップ2のデータの抽出になります。
データの抽出については、次のBeautiful Soupの章で確認していきましょう。
関連記事です。
requestsに関して、詳しい説明はこちらをご覧ください。インストール方法、Responseオブジェクト、requests.get()の引数などを詳しく解説しています。

発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
BeautifulSoupでYahooからニュース情報のスクレイピング
これからBeautiful Soupの基本となる使い方を紹介していきます。ここはでは、yahoo(https://www.yahoo.co.jp/) から記事を取得してみます。
Beautiful Soupの利用にあたってはインストールやインポートが必要になります。詳しい説明は、「図解!Beautiful SoupでWEBスクレイピング徹底解説!」を参照ください。
今回は、メインページのトップニュースから、タイトル(赤線で囲った箇所)とそのURLの組み合わせの一覧を取得したいと思います。
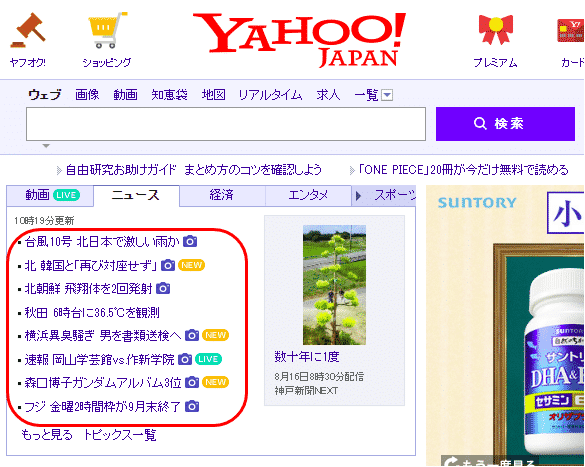
最初に、requestsを利用してWEBサイトの情報をダウンロードします。
1 2 | url = 'https://www.yahoo.co.jp/' res = requests.get(url) |
次に、この情報の中からトップニュースのタイトルとURLを取り出してみましょう。そのためには、BeautifulSoup()を用いて、ダウンロードした情報の解析が必要になります。
BeautifulSoup()の記述方法は以下です。
1つ目の引数には、解析対象のHTML/XMLを渡します。
2つ目の引数として解析に利用するパーサー(解析器)を指定します。
| パーサー | 引数での指定方法 | 特徴 |
| Python’s html.parser | “html.parser” | 追加ライブラリが不要 |
| lxml’s HTML parser | “lxml” | 高速に処理可 |
| lxml’s XML parser | “xml” | XMLに対応し、高速に処理可 |
| html5lib | “html5lib” | 正しくHTML5を処理可 |
この中でも、今回はPythonの標準ライブラリに入っており、追加でライブラリのインストールが不要なPython’s html.parserを利用します。
BeautifulSoup()に先ほど取得したWEBサイトの情報とパーサー"html.parser"を渡してあげます。
1 | soup = BeautifulSoup(res.text, "html.parser") |
これらの情報を用いてBeautiful SoupでHTMLを解析していきますが、HTMLタグで該当する箇所を検索するメソッドには次のようなものがあります。
| メソッド | 引数 | 説明 |
| find() | 検索するHTMLタグ | 引数に一致する 最初の1つの 要素を取得します。 |
| find_all() | 検索するHTMLタグ | 引数に一致する 全ての 要素を取得します。 |
まずは該当する箇所のHTMLタグを確認します。ブラウザでyahooのページを開きます。(ここでは、Google Chromeの例を載せていますが、他のブラウザでも確認できます。)
メインページのトップニュースのタイトルにマウスのカーソルを当て、右クリックします。するとメニューが表示されますので、その中から「検証」を選択します。
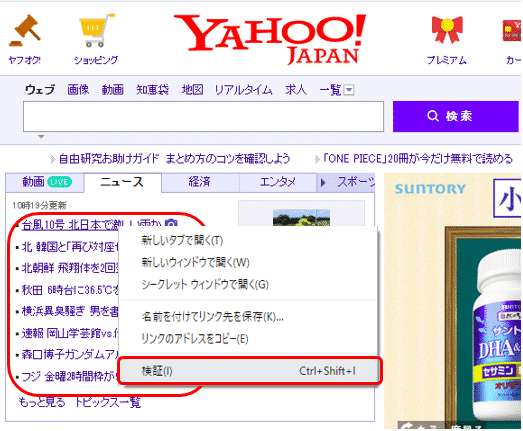
すると、右側にウィンドウが現れ、HTMLが表示されます。先ほどのトップページのニュースは、htmlのタグで<a href=”url”>…</a>のように記載されているようです。
タグ<a>は、リンクの開始点と終了点を指定するタグです。リンクの開始点ではhref属性でリンク先を指定しています。
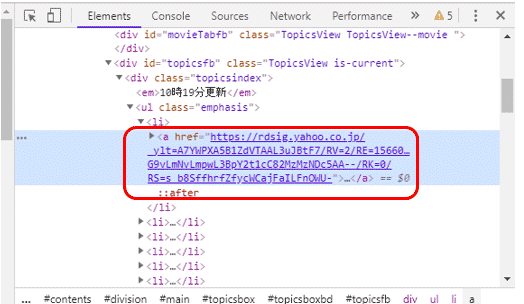
find_all()に引数”a”を渡して、検索してみます。
1 2 | elems = soup.find_all("a") elems |

すると、タグ<a>が含まれる全ての要素が表示されました。ここから必要な情報だけに絞り込む必要があるようです。
どのようにして絞り込めば良いのでしょうか?先ほど表示された内容をよく見てみると、トップニュースに該当する箇所は全て、URLに”news.yahoo.co.jp/pickup”が含まれているようです。これが利用できそうです。

ということで、URLに”news.yahoo.co.jp/pickup”が含まれているとう条件でさらに絞り込んでいきましょう。
ここで文字列のパターンで検索できるモジュールreをインポートします。モジュールreの詳しい説明は、「図解!Python 正規表現の徹底解説!」を参照ください。
1 | import re |
ライブラリreのcompile()を利用して、href=re.compile("news.yahoo.co.jp/pickup") をfind_all()の引数として渡します。
ここでは、href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出しています。そして抽出した結果を表示すると、
1 2 | elems = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup")) elems |

表示したいトップニュースの箇所に絞り込んで情報を表示することができました。
後は、ここからURLとタイトルを抽出して一覧表示するだけです。
まずはcontentsを利用して1つ目のニュースのタイトルを表示してみます。
1 | elems[0].contents[0] |
トップニュースの1つ目のタイトルだけを取り出すことができました。
今度はリンクのURLだけを取得したいと思います。リンクが含まれているタグhrefの内容だけを抽出するattrs['href']を利用します。
1 | elems[0].attrs['href'] |
同様に、2つ目のニュースも取得してみましょう。リストelemsの2つ目の要素を表示するよう、elems[0]からelems[1]に変更します。
1 | elems[1].contents[0] |
2つ目のニュースのURLも同様に、elems[0]からelems[1]に変更すると表示されました。
1 | elems[1].attrs['href'] |
このようにしてリストelemsに格納されている全ての要素のcontensとhref属性を取得すれば、タイトルとURLの一覧を表示することができます。全ての要素の表示はfor文を使って次のように書きます。
1 2 3 | for elem in elems: print(elem.contents[0]) print(elem.attrs['href']) |

このようにして、yahooのトップページからニュースのタイトルとURLの一覧を取得することができました。
関連記事です。
Beautiful Soupに関して、詳しい説明はこちらをご覧ください。インストール方法、selectメソッドの使い方、find、find_allメソッドの使い方などを詳しく解説しています。

Seleniumでスクレイピングする方法(Javascriptを使った動的ページへの対応)
Seleniumとは、ブラウザを自動的に操作するライブラリです。主にWEBアプリケーションのテストやWEBスクレイピングに利用されます。
主にWEBスクレイピングでは、JavaScriptが使われている動的なサイトからのデータの取得や、サイトへのログインなどに使われています。
Seleniumのスクレイピングでの使い方
このWEBスクレイピングの3ステップの中で、Seleniumは1つ目のHTMLデータの取得にrequestsと共によく用いられます。
Pythonではrequestsライブラリを利用して、簡単にWEBサイトからデータを自動的に取得することができます。
しかし、近年いくつかのWEBサイトではJavaScriptを用いて、ユーザーが画面のボタンをクリックや、画面をスクロールした時に次の画面を読み込む処理を組み込んでいるサイトがあります。
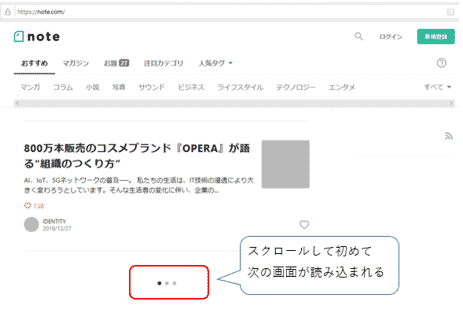
また最初にログインを求められるサイトもあります。

このようなサイトに対しては、機械的にrequestsライブラリだけでデータを取得することができません。
その際に利用するのがSeleniumになります。Seleniumでは、ドライバを経由してブラウザを操作することができます。
つまり、Seleniumでは人間がブラウザを経由して操作しているのと同じ動きを実現することができます。そしてブラウザを操作して、次の画面を読み込んでからrequestsライブラリを使って、画面のデータを取得します。
またSeleniumは、先ほどのWEBスクレイピングの3ステップの中で、2つ目のデータの抽出も行うことができます。
但し、Seleniumはブラウザを操作してデータを取得しますので、動作が遅いことが難点です。従って、できるだけ必要最低限の箇所でSeleniumを使うことをお勧めします。
Seleniumでインスタグラムへログインする方法
次にSeleniumを使って、パスワード入力を求められるサイトでのログイン方法を確認していきましょう。
Seleniumの利用にあたってはインストールやインポートが必要になります。詳しい説明は、「図解!PythonでSeleniumを使ったスクレイピングを徹底解説!」を参照ください。
ここはでは、インスタグラム(https://www.instagram.com) にログインします。
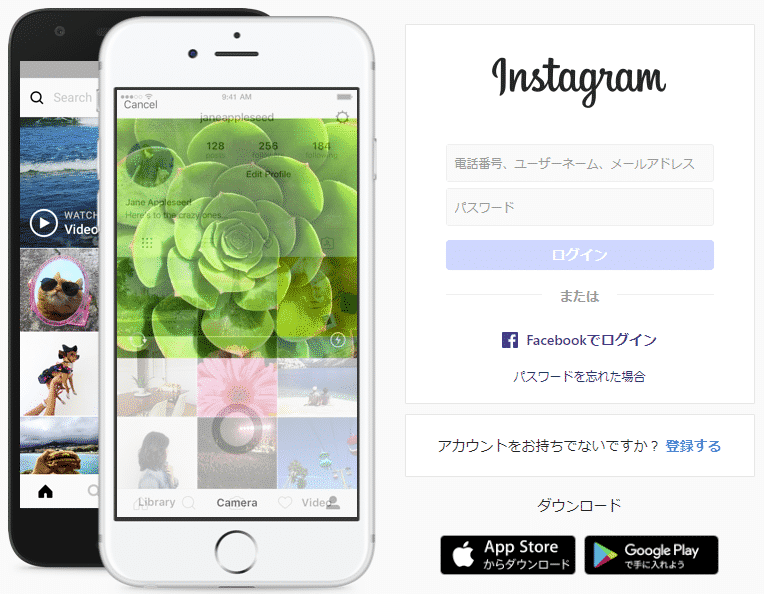
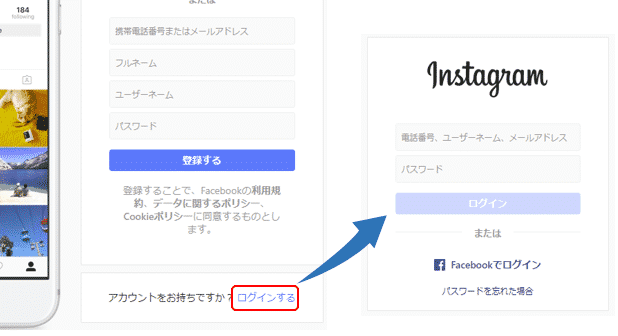
インスタグラムの最初の画面では「アカウントをお持ちですか?」と下にメッセージが表示されます。そこで「ログインする」のリンクをクリックします。
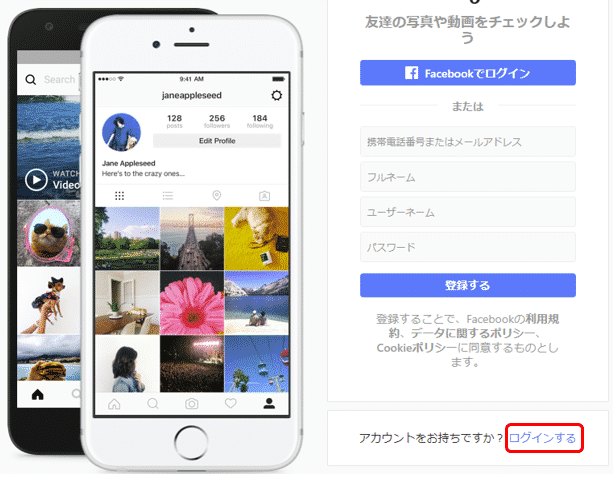
そして次の画面で「電話番号、ユーザーネーム、メールアドレス」と「パスワード」を入力しログインボタンを押します。
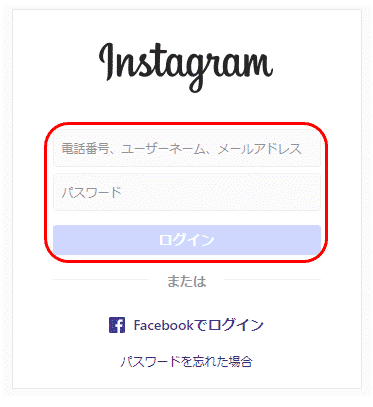
ログインしたら、最初に以下のような「お知らせをオンにする」を確認するメッセージが表示されるので、「後で」をクリックします。
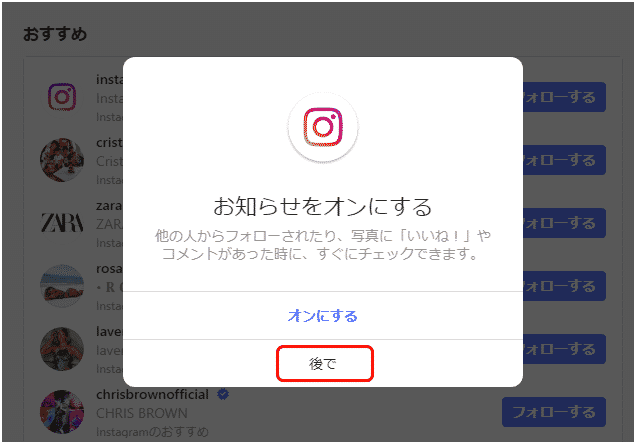
するとメイン画面が表示されます。
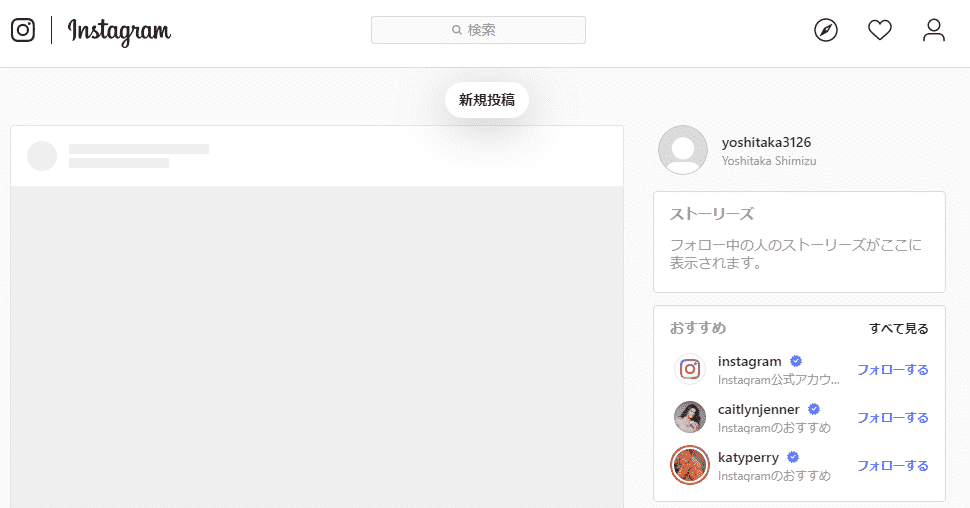
このログインに必要な一連の操作を、Seleniumを使って自動的にしてみましょう。
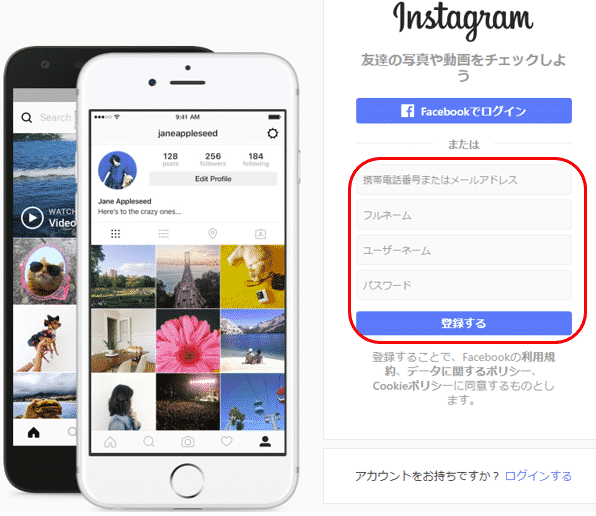
ログインに必要なインスタグラムのアカウントをお持ちでない場合は、最初の画面からユーザー登録を事前に行ってください。
以下の赤で囲った箇所に必要な情報を入力の上、「登録する」ボタンを押すと、ユーザー登録できます。
ログイン用リンクのクリック
最初のステップとして、インスタグラムのサイトを表示し、リンク「ログインする」をクリックしましょう。
コードは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | from selenium import webdriver from time import sleep USERNAME = 'インスタグラムのユーザー名' PASSWORD = 'インスタグラムのパスワード' driver = webdriver.Chrome('ChromeDriverのディレクトリ + chromedriver') error_flg = False target_url = 'https://www.instagram.com' driver.get(target_url) sleep(3) try: login_button = driver.find_element_by_link_text('ログインする') login_button.click() sleep(3) except Exception: error_flg = True print('ログインボタン押下時にエラーが発生しました。') |
プログラムを実行すると、
インスタグラムの画面が表示された後「ログインする」のリンクがクリックされ、ログイン画面が表示されました。
それではコードを詳しく解説していきましょう。
次の変数USERNAME、PASSWORDには、お持ちのインスタグラムのアカウント情報を入力下さい。この情報を元にログインします。
PASSWORD = 'インスタグラムのパスワード'
また「WebDriverのインストール」の章で説明したように、ChromeDriverを格納したディレクトリとファイル名「chromedriver」を入力してください。
そして読み込んだdriverのメソッドget()を利用して、インスタグラムのサイトを開きます。
target_url = 'https://www.instagram.com'
driver.get(target_url)
変数error_flgはエラーの判定に使うフラグです。最初はFalseを設定しておきます。
そして途中でエラーが発生した場合はTrueを設定して、以降の処理をスキップする判定に使います。
次に「ログインする」のリンクをクリックしています。
login_button.click()
リンクはfind_element_by_link_text(‘リンク名’)で該当のリンクを検索し、click()でクリックすることができます。
例外処理
先ほどのコードでは処理全体をtry~exceptで囲っており、try以下の処理でエラーが発生した場合は、except以下の例外処理に移るようにしています。
~
except Exception:
error_flg = True
print('ログインボタン押下時にエラーが発生しました。')
exceptでの処理は、変数error_flgにTrueを設定し、エラーメッセージをprint()で表示しています。
また以降の処理では、最初に「if error_flg is False:」と記述し、error_flgがFalseの時(エラーが発生しなかった時)のみ、処理を実行するようにしています。
ログイン画面でのユーザーネーム・パスワードの入力
次に、ログイン画面でユーザーネームとパスワードを入力し、インスタグラムにログインしましょう。
まずはログイン画面でユーザーネームとパスワードの入力欄の検索方法を確認します。それぞれの入力欄にカーソルが当たっている状態で右クリックし、メニューから「検証」を選択します。
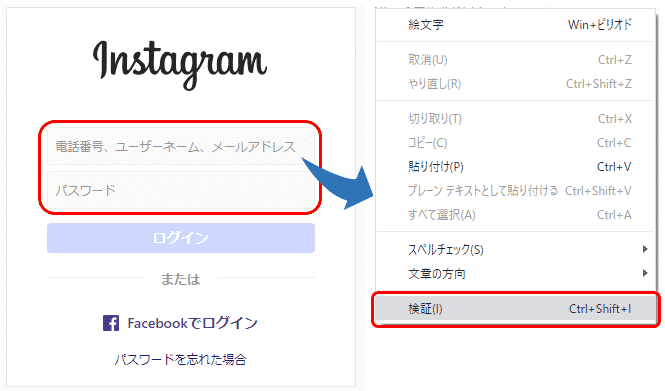
すると、ユーザーネームとパスワードで次のコードが表示されました。

ここではinputタグの属性aria-labelで検索することができそうです。
XPathである特定のタグの属性を指定する方法は、次になります。
XPathの詳しい説明は、「図解!XPathでスクレイピングを極めろ!」を参照ください。
例えば、inputタグの属性aria-labelがパスワードのものを検索するには、
と記述します。
これらの情報を元に記述したコードは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | if error_flg is False: try: username_input = driver.find_element_by_xpath('//input[@aria-label="電話番号、ユーザーネーム、メールアドレス"]') username_input.send_keys(USERNAME) sleep(1) password_input = driver.find_element_by_xpath('//input[@aria-label="パスワード"]') password_input.send_keys(PASSWORD) sleep(1) username_input.submit() sleep(1) except Exception: print('ユーザー名、パスワード入力時にエラーが発生しました。') error_flg = True |
プログラムを実行すると、
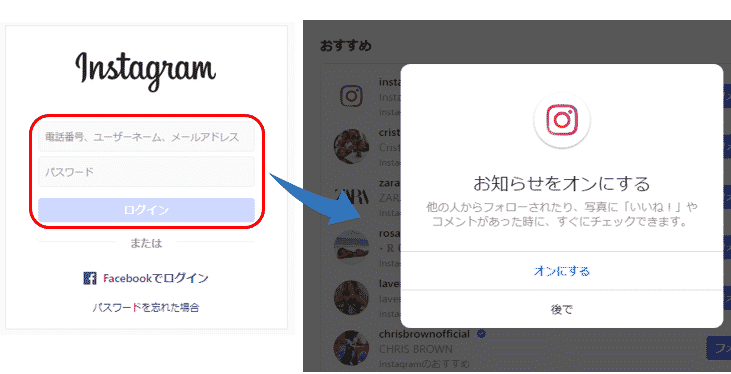
インスタグラムにログインできましたが、ポップアップ画面で「お知らせをオンにする」かの確認メッセージが表示されています。
ポップアップ画面を操作し閉じる方法
次にポップアップ画面で「後で」を選択し、インスタグラムのメイン画面を表示させましょう。
ここでもまず、「後で」の検索方法を確認します。「後で」にカーソルを当てた状態で右クリックし、メニューから「検証」を選択します。
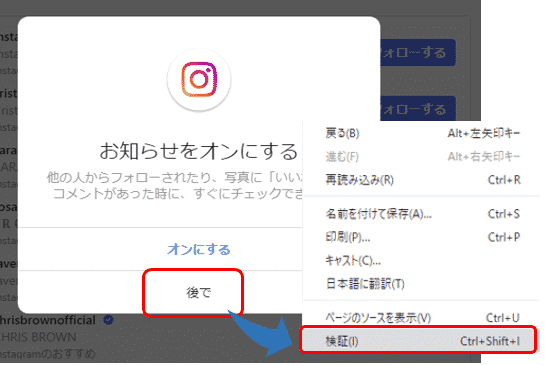
すると次のコードが表示されました。

buttonタグのテキスト「後で」で検索してみましょう。
XPathでは、テキストに含まれている文字で検索する場合、text()を使います。
最終的にコードは次のようになります。
1 2 3 4 5 6 7 8 9 10 | if error_flg is False: try: sleep(1) notnow_button = driver.find_element_by_xpath('//button[text()="後で"]') sleep(1) notnow_button.click() sleep(1) except Exception: pass |
プログラムを実行すると、
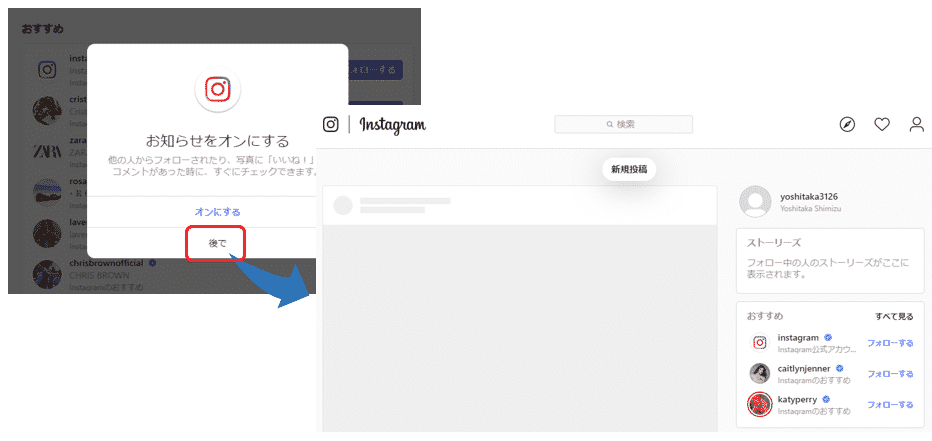
インスタグラムのメイン画面が表示されました。
このようにしてパスワードの入力を求められるサイトでも、Seleniumを使って自動的にログインすることができます。
関連記事です。
Seleniumに関して、詳しい説明はこちらをご覧ください。インストール方法、Googleでの検索結果の取得と保存方法、画面スクロールする方法、画像ファイルをダウンロード・保存する方法などを詳しく解説しています。

XPathに関して、詳しい説明はこちらをご覧ください。

Pandasによる株価情報のスクレイピングと保存(CSV、Excelファイル)
WEBスクレイピングとは、WEBサイトから情報を自動的に取得し、必要に応じて、情報の加工などを行うことです。取得したデータは、ファイルやデータベースに保存します。
WEBサイトに公開されている情報は、テキスト情報や画像、動画など様々な情報がありますが、その中の1つとしてテーブルに格納されている情報があります。
Pythonのデータ分析用ライブラリPandasではread_html()を利用して、WEBサイト上のテーブルに格納されているデータを非常に簡単に取得することができます。
また取得したデータはPandasのDataFrame(データフレーム)と呼ばれるデータ構造を利用してすぐに分析やグラフ化、データ保存することもできます。
pandas.read_html()の基本的な使い方
これからread_html()の基本となる使い方を紹介していきます。
pandas.read_html()の利用にあたってはインストールやインポートが必要になります。詳しい説明は、「Pandasで超簡単!WEBスクレイピング」を参照ください。
read_html()の記述方法は以下です。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| URL | 必須 | 読み込み対象のURL |
| header | 任意 | ヘッダに指定する行 |
| index_col | 任意 | インデックスに指定する列 |
| skiprows | 任意 | 読み飛ばす行数 |
Yahoo Financeから米国の株価情報の取得
これからread_html()の使い方の例を紹介していきます。
ここでは、Yahoo Finance(https://finance.yahoo.com/quote/AAPL/history?p=AAPL&.tsrc=fin-srch)からアップルの株価情報を取得してみます。
まず今回は、メインページのトップニュースのタイトル(赤線で囲った箇所)とそのURLを取得したいと思います。
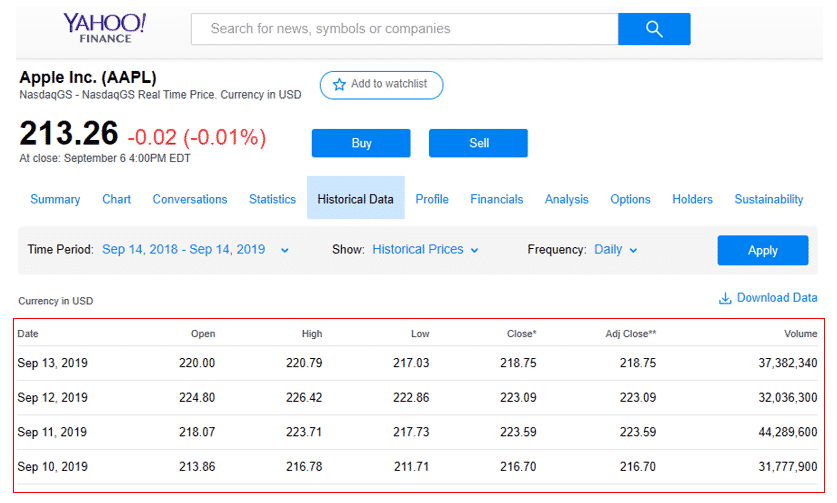
このページでは、1年間のアップルの株価が表示されています。
最初にpandasをインポートします。
1 | import pandas as pd |
次に今回読み込むURLを変数urlに格納します。
1 | url = 'https://finance.yahoo.com/quote/AAPL/history?p=AAPL&.tsrc=fin-srch' |
そして、read_html()に対して、変数urlを渡し、引数headerに0行目を指定します。取得した結果は、変数dataに格納されます。
1 | data = pd.read_html(url, header = 0) |
それではWEBページから取得したテーブルの情報を表示してみましょう。結果はリストの形式で取得されます。例えば、読み込み対象のWEBページに複数のテーブルがある場合、1つ目のテーブルは[0]、2つ目のテーブルは[1]で確認することができます。
ここではテーブルが1つしかありませんので、[0]で確認します。head()を使って最初の5行を表示してみましょう。
1 | data[0].head() |
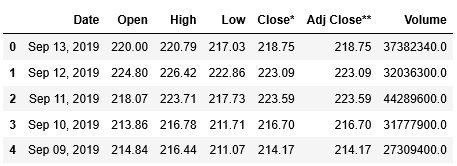
合わせて、tail()を用いて、後ろからの5行も内容を確認しましょう。
1 | data[0].tail() |
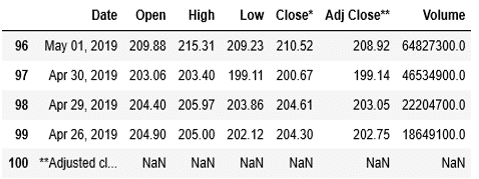
ここまでで、Yahoo Financeからアップルの株価を取得することができました。
関連記事です。
Pandasによるスクレイピングに関して、詳しい説明はこちらをご覧ください。インストール方法、Yahoo Financeから米国株の株価情報を取得、グラフ化し、データを保存する方法などを詳しく解説しています。

Stooqから日本の株価情報の取得
Pandasを用いて日本の株価情報の取得方法についても解説した記事があります。インストール方法、Stooqから日本株の株価情報を取得、グラフ化し、データを保存する方法などを詳しく解説しています。

ニュースサイトからキーワードを含んだサマリー情報の取得・保存(CSV、Excelファイル)
WEBスクレイピングとは、WEBサイトから情報を自動的に取得し、必要に応じて、情報の加工などを行うことです。取得したデータは、ファイルやデータベースに保存します。
Pythonでは、newspaper3kというライブラリを利用して、非常に簡単にテキストデータをWEBサイトから自動的に取得することができます。
newspaper3kの基本的な使い方
newspaper3kの基本的な使い方について解説した記事があります。インストール方法、ニュースサイトから情報を取得、自然言語処理を用いてサマリーを取得する方法などを詳しく解説しています。

ニュースサイトから記事一覧の取得方法
今回は、ブルームバーグのニュースサイト(https://www.bloomberg.co.jp/)をスクレイピングして記事を取得してみましょう。
サイトを訪問すると、次のようなページが表示されます。こちらがトップページで、更新された記事が一覧で掲載されています。
ここではまず、トップページの記事の一覧から各記事のURLとタイトルを取得して表示する例を確認していきます。
最初にnewspaperをインポートします。
1 | import newspaper |
次のステップとして、build()を使います。build()を使うことによって、サイトのトップページから複数のページをまとめて取得することができます。
build()の引数として、記事を取得したいサイトのurlを渡します。
その他の引数としては、今回はテストの為、次のようなものを利用します。
memoize_articles = True/False : 取得した記事を記憶しておくか否か。Trueにすると、1度目に実行した時に取得した情報が記憶され、build()を再度実行しても、データは取得されません。ここでは、複数回実行しても結果の違いが分かるよう、Falseにしておきます。
MAX_SUMMARY = 文字数 : サマリーとして表示する最大の文字数を指定します。ここではテストの為、サマリーが取得できていることが確認できれば良いので、短くしておきます。
まず変数urlを定義して、ブルームバーグのニュースサイトのアドレスを格納します。次にbuild()に対して、このurlを渡します。また引数memoize_articlesはFalseに、MAX_SUMMARYは300を指定します。
1 2 | url = "https://www.bloomberg.co.jp/" website = newspaper.build(url, memoize_articles = False, MAX_SUMMARY = 300) |
またbuild()からの結果を変数websiteに格納しています。
これらbuild()から取得した記事の情報を確認していきましょう。まずは記事が取得できていることを確認する為、取得した記事のurlとタイトルを表示します。
取得した記事は属性articlesで確認できますので、これをfor文で1つ1つ順に取り出し、変数articleに格納します。そして、その属性urlに記事のURLが、属性titleにタイトルが入っているので、print文で表示します。
1 2 3 | for article in website.articles: print(article.url) print(article.title) |

実行すると、記事のURLが表示され、その下に記事のタイトルが表示されていることがわかります。これらの情報が、トップページに表示されている記事毎に、順に表示されていることがわかります。
ニュースサイトから記事サマリーの取得方法
今度は、記事のサマリーを取得していきましょう。記事のサマリーを取得するには、記事のオブジェクトに対して、download()で記事をダウンロードし、parse()で記事を解析し、nlp()で自然言語処理を実施した後で、summaryの属性を表示します。
サマリーを取得し、表示する例は次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | for item in range(len(website.articles)): <br> website_article = website.articles[item] <br> website_article_url = website_article.url <br> try: website_article.download() website_article.parse() website_article.nlp() print("記事[" + str(item) + "]: " + website_article_url +" : " + website_article.summary + "\n") except: print("記事[" + str(item) + "]: " + website_article_url +" : " + "取得エラー" + "\n") continue |
1つずつ順に解説しますと、まず、for item in range(len(website.articles)):では、len(website.articles)で読み込んだ記事数を取得し、rangeで0から記事数まで、順に数値を1ずつ増やしながら、itemにその数値を格納し、for文で以降の処理を繰り返しています。
website_article = website.articles[item]では、取得した記事の内、item番目の記事を変数website_articleに格納しています。
そして、website_article_url = website_article.urlでは、属性urlでitem番目の記事のurlを取得し、変数website_article_urlに格納しています。この内容は、後にprint文でurlとして表示しています。
最後に、取得したitem番目の記事に対して、先ほど説明したdownload()、parse()、ntp()を実行して、サマリーをwebsite_article.summaryとして、print文で表示しています。
記事のサマリーは、自然言語処理を利用して記事のキーワードを特定した上で、重要なキーワードを含めたかたちでまとめられています。
print文では、urlとサマリーの他に、"記事[" + str(item) + "]: "で何番目の記事かも表示しています。また最後に"\n"を付けて、1つの記事のサマリーを表示したら、改行するようにしています。
また、これらの一連の処理については、try:とexcept:を用いて、try以下の処理の実行中に何らかのエラーが発生した場合、except:でエラーが発生した記事番号、URLと合わせて、エラーが発生した旨をメッセージとして表示し、continueで次の記事の処理を続けるようにしています。
実行結果は次のようになります。

記事毎に番号が0から振られて記事[0]から順に、URLとサマリーが表示されていきます。サマリーは300文字だけを表示しています。
このようにして、ニュースサイトのトップページに表示されている複数の記事を、順に取得し、表示することができました。次回の章では、取得した記事を後から確認できるようファイルに保存する方法を見ていきましょう。
ニュースサイトから取得した記事データの保存
今回は、その記事を後から確認できるよう、データを保存していきたいと思います。データはEXCELファイルで読み込んだり、データベースに取り込み易いよう、CSVファイルの形式で出力していきましょう。
前章のプログラムを元に、取得した記事のサマリーをCSVファイルに書き込むコードを追加していきたいと思います。
PythonでCSVファイルの読み書きを行うには、Pythonの標準ライブラリの中にCSVという便利なモジュールがあります。まずはCSVモジュールをインポートします。
1 | import csv |
またCSVファイルのファイル名には、後から見た時にいつの記事かがわかりやすいよう、記事を取得した日付を付けたいと思いますので、合わせて日付の取得に必要なライブラリdatetimeもインポートします。
1 | import datetime |
CSVのファイル名に付ける日付は、datetime.datetime.today()で当日の日付を取得し、strftime()で文字列に変換します。その際に書式として、西暦4桁「%Y」、月「%m」、日「%d」の形式で表示されるよう”%Y%m%d”を渡します。このようにして取得した日付を変数csv_dateに格納しています。
1 | csv_date = datetime.datetime.today().strftime("%Y%m%d") |
先ほど作成した変数csv_dateと合わせて、CSVファイル名を保存する変数csv_file_nameを作成します。日付の前にはブルームバーグから取得したデータとわかるように、「bloomberg_」を付けています。またファイルの末尾には、csvファイルとなるように「.csv」を付けています。
1 | csv_file_name = 'bloomberg_' + csv_date + '.csv' |
次にCSVファイルへの書き込みの処理を記述していきます。何かを書き込む前に、open()を利用して、空のCSVファイルをオープンすることが必要になります。
open()の記述方法は次のようになります。
引数として、最初にファイルの保存先ディレクトリとファイル名を指定します。ここでは、先ほどの変数csv_file_nameを指定します。ここでは、ディレクトリは指定せず、プログラムを実行するディレクトリにファイルを出力してみます。
引数modeでは、ファイルを読み込むモードを指定します。'w'を指定すると、書き込み用に開きます。
また引数encodingでは、CSVファイルの文字コードを指定します。ここでは、コンピュータ上で日本語を含む文字列を表現するために用いられる文字コードの一つであるShift_JIS(シフトジス)を指定します。Shift_JISを指定するには、引数に’cp932’(Shift_JIS)を渡します。
ここでは次のように記述します。
1 | f = open(csv_file_name, 'w', encoding='cp932') |
CSVファイルのオープンが終わりましたら、次にヘッダを書き込んでみましょう。CSVファイルへの書き込みには、csv.writer()を利用します。
csv.writer()の最初の引数には、open()で開いたファイルオブジェクトを指定します。ここでは、open()から返されたオブジェクトを変数fに代入していますので、fを指定します。
引数lineterminatorでは、改行方法を指定します。ここでは改行時に通常用いる'\n'を指定しています。
そして、CSVファイルに1行を書き込むには、writerow()を使います。writerow()には、CSVファイルに書き込みたい内容をリスト型で渡します。
一連のプログラムは次のようになります。
1 2 3 | writer = csv.writer(f, lineterminator='\n') csv_header = ["記事番号","URL","サマリー"] writer.writerow(csv_header) |
ヘッダの書き込みが終わりましたので、いよいよニュースサイトから1つ1つの記事を取得して表示しているプログラムに、CSVファイルへの書き込みを追加してみましょう。
サマリーを取得し、表示、CSVファイルへ書き込みするプログラムは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | for item in range(len(website.articles)): csvlist = [] website_article = website.articles[item] try: website_article.download() website_article.parse() website_article.nlp() print("記事[" + str(item) + "]: " + website_article_url +" : " + website_article.summary + "\n") csvlist.append(str(item)) csvlist.append(website_article.url) csvlist.append(website_article.summary) writer.writerow(csvlist) except: print("記事[" + str(item) + "]: " + website_article_url +" : " + "取得エラー" + "\n") continue f.close() |
基本的な流れは前のプログラムと同じになりますので、今回はCSVファイルへの書き込みの箇所に絞って解説します。該当箇所の背景色を変更しています。
1つずつ順に解説しますと、csvlist = [] では、空のリストを変数csvlistに渡し、初期化しています。これからcsvlistには、ファイル出力する1行の情報を格納し、writerow()に渡して1行ずつ書き込んでいくことになります。
次に、1つの記事のサマリーの取得が終わり、画面表示が終わりましたら、リスト型の変数csvlistに対して、ファイル出力する1行の情報を格納していきます。
csvlist.append(str(item))で記事番号を、csvlist.append(website_article.url)で記事のURLを、csvlist.append(website_article.summary)で取得した記事のサマリーを順にcsvlistに対して格納しています。
そして最後に、writerow()に対してcsvlistを渡して、1行の情報をCSVファイルに書き込んでいます。またfor文が終わりましたら、f.close()でopen()で開いたファイルオブジェクトを閉じます。
実行結果は次のようになります。

画面に表示される内容は、前の章と同じです。記事毎に番号が0から振られて記事[0]から順に、URLとサマリーが表示されていきます。サマリーは300文字だけを表示しています。
また出力されたCSVファイルを開けると、

1つ1つ取得した記事毎に順に、記事番号、URL、サマリーと出力されています。
このようにして、スクレイピングで取得した記事を後から確認できるよう、CSVファイルの形式で出力し、データを保存することができました。
Scrapyでスクレイピングする方法
Scrapy(読み方:スクレイピー)とは、Pythonのスクレイピング・クローリング専用のフレームワークです。主にWebページからのデータ取得に用いられます。
今までのWebスクレイピングの方法では、BeautifulSoupやRequestsなど、複数のライブラリを継ぎはぎに組み合わせながら、多くのコーディングを行う必要がありました。この結果、スクレイピングの学習や作業に非常に多くの時間を費やし、せっかく取得したデータの活用に割ける時間が奪われてしまっていました。
しかしスクレイピング専用のフレームワークであるScrapyの登場により、これは劇的に変わりました。フレームワークとは、全体の処理の流れがある程度、事前に組み込まれているソフトウェアの基盤になります。従って、面倒な多くのことはフレームワーク自体が行ってくれて、これによりデータの取得が容易になり、効率的に行うことができるようになりました。
別のページへのリンクのたどり方や、どのデータを取得するかなど、最低限必要なコーディングだけを行えばよくなりました。さらに1つのフレームワークで実現するので、一貫性が保たれ、非常に高速にデータを取得することができます。
これにより効率的にWebサイトからデータを取得することができ、データ取得の本来の目的であるデータの活用に、より多くの時間を割くことができるようになります。
Scrapyの詳細については、以下の記事を参照ください。




