
Python3におけるScrapyの使い方について初心者向けに解説した記事です。
最初にScrapyとはどのようなものかを説明し、その後に、Scrapyのインストール方法と基本的な使い方を、サンプルコード付きのチュートリアル形式で、具体的な例を用いて解説していきます。
Scrapyについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用ください。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「PythonでWebスクレイピング・クローリングを極めよう!」(Udemyへのリンク)
Scrapyとは、できること
Scrapy(読み方:スクレイピー)とは、Pythonのスクレイピング・クローリング専用のフレームワークです。主にWebページからのデータ取得に用いられます。
今までのWebスクレイピングの方法では、BeautifulSoupやRequestsなど、複数のライブラリを継ぎはぎに組み合わせながら、多くのコーディングを行う必要がありました。この結果、スクレイピングの学習や作業に非常に多くの時間を費やし、せっかく取得したデータの活用に割ける時間が奪われてしまっていました。
しかしスクレイピング専用のフレームワークであるScrapyの登場により、これは劇的に変わりました。フレームワークとは、全体の処理の流れがある程度、事前に組み込まれているソフトウェアの基盤になります。従って、面倒な多くのことはフレームワーク自体が行ってくれて、これによりデータの取得が容易になり、効率的に行うことができるようになりました。
別のページへのリンクのたどり方や、どのデータを取得するかなど、最低限必要なコーディングだけを行えばよくなりました。さらに1つのフレームワークで実現するので、一貫性が保たれ、非常に高速にデータを取得することができます。
これにより効率的にWebサイトからデータを取得することができ、データ取得の本来の目的であるデータの活用に、より多くの時間を割くことができるようになります。
この記事では、このPythonのスクレイピング専用フレームワークScrapyの使い方を、徹底的に解説していきます。
Scrapyについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用ください。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「PythonでWebスクレイピング・クローリングを極めよう!」(Udemyへのリンク)
ScrapyとBeautifulSoup、Seleniumとの違い
データ取得のステップ
Webページからのデータ取得は、次の3ステップで行われます。
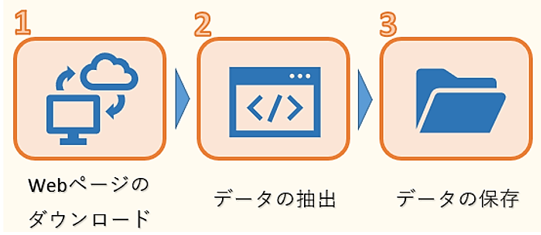
1つ目はWEBページのHTMLデータのダウンロードです。ただし、HTMLには必要な文章のデータだけでなく、タグなどのデータも混じっているので、必要なものだけを抽出する作業が必要になります。
そこで2つ目のデータの抽出が欠かせません。ここでは、複雑な構造のHTMLデータを解析し、必要なデータだけを抽出します。
そして最後に抽出したデータをデータベースやファイルなどに保存します。
データ取得に利用するライブラリ
Pythonでデータ取得によく使われるライブラリとしては、Requests、Beautiful Soup、Selenium、Scrapyがあります。
先ほどのデータ取得の3ステップの中で、それぞれのライブラリがどこで使われるのかをまとめると次のようになります。
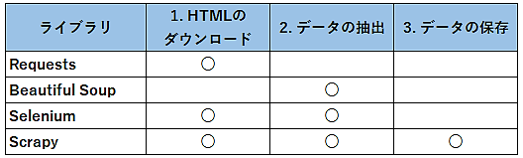
Requestsは1つ目のHTMLデータのダウンロードによく用いられます。PythonではRequestsを利用して、簡単にWebページからHTMLを自動的にダウンロードすることができます。
その後、取得したHTMLからBeautiful Soupなどの別のライブラリを用いて必要なデータのみを抽出します。
またSeleniumは、JavaScriptが使われている特殊なWebページからのHTMLデータのダウンロードや、サイトへのログインなどに使います。
Seleniumは、HTMLのダウンロードだけでなく、必要なデータの抽出も行うことができますが、ブラウザを操作してデータを取得しますので、動作が遅いことが難点です。従って、できるだけ必要最低限の箇所でSeleniumを使うことをお勧めします。
そしてこれら3つのステップを全てカバーするのがScrapyになります。Scrapyでは、コードは主にSpiderと呼ばれるクラスに記述していきます。Spiderにコードを記述すれば、後は他のものがうまく連動してくれて、必要な作業を行ってくれます。
Spiderには、最初のURLとリンクのたどり方を記述します。すると後はScrapyが、当てはまるWebページを次々自動的に高速にダウンロードしてくれます。そして、取得したHTMLの中から、どのデータを抽出するのかを、Spiderに記述します。すると、データの抽出自体はScrapyが行ってくれます。
ファイル出力は、コマンド1つでScrapyがCSV、JSON、XMLなど各種ファイルに出力・保存してくれます。
またJavaScriptが使われている特殊なWebページに対しては、Scrapy-SeleniumやScrapy-Splashを使います。これらについては別の記事で紹介していきます。
Scrapyのインストール方法(Anacondaでの環境構築)
Anacondaでの環境構築(Python3.8)
本記事では、AnacondaとVS Codeを元にScrapyの開発環境を構築していきます。詳細は、以下のリンクを参照ください。またAnacondaでの仮想環境の作成においては、Pythonのバージョンは、必ず3.8を選択してください。現時点で、Scrapyはpython3.9に対応していません。
>> VS CodeでPython開発環境の構築
Scrapyのインストール
次にScrapyをインストールします。Anaconda Navigatorから仮想環境を選択し、三角のボタンをクリックして表示されたメニューから「Open Terminal」を選択します。
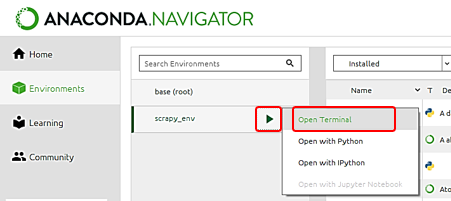
ターミナルが立ち上がったら、環境が先ほど作成したものであることを確認します。そして次のコマンドを入力し実行します。

途中で Proceed ([y]/n)? とインストールの確認メッセージが表示されたらyと入力し、Scrapyをインストールします。
インストールが終わりましたら、Scrapyの環境構築は終わりです。
Scrapyで利用できるコマンド
Scrapyでは、ターミナルを起動してコマンドを入力・実行することで、次のことを行うことができます。
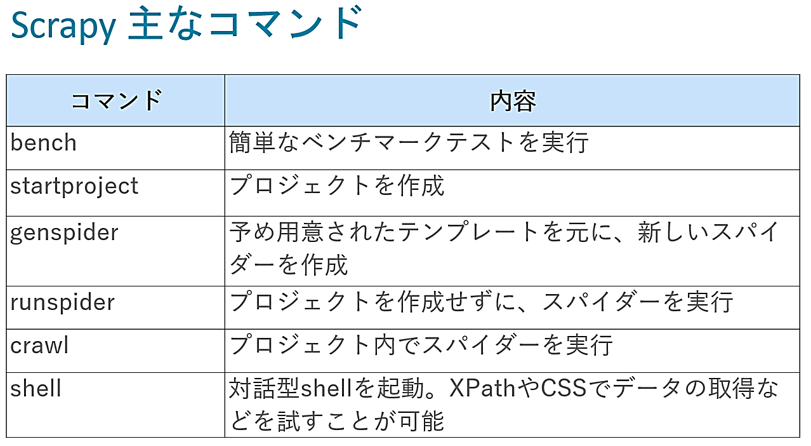
コマンドの詳細については、以下を参照ください。
>> Scrapyで利用できるコマンド
後で実際に実行していきますが、基本的な流れとしては、startprojectコマンドでプロジェクトを作成し、genspiderでプロジェクト内にspiderを作成していきます。
spiderのコーディングでは、必要に応じてshellでデータ取得方法を確認し、それをspiderに反映します。またScrapyのコーディングは、VS Codeで行います。
そしてコーディングが終わりましたら、crawlコマンドでspiderを実行する というのが一連の流れになります。
プロジェクトの作成
それでは実際にプロジェクトの作成、spiderの作成と一連の流れを確認していきます。
Scrapyでの開発ステップ
後で実際に1つ1つ確認していきますが、基本的な流れとしては、次のようになります。
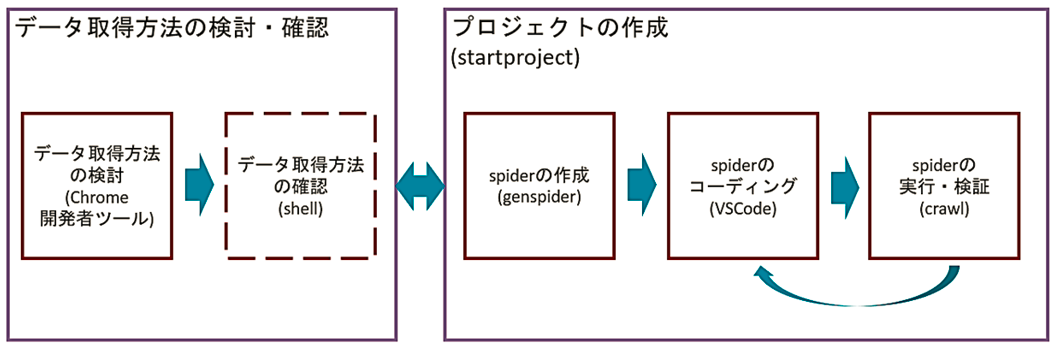
まずは大きく分けて2つのパートがあります。1つは、スクレイピング対象のサイトを分析し、データの取得方法の検討・確認を行うパート(左側)と、もう1つは、プロジェクトの作成からspiderの作成と、実際にコーディングを行うパート(右側)です。
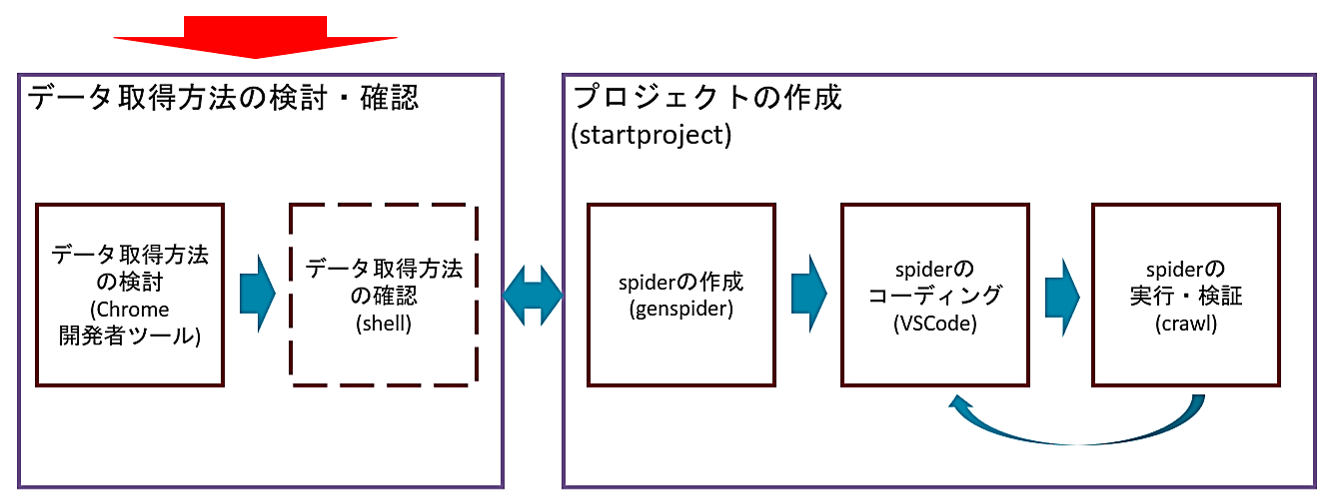
まずデータの取得方法の検討・確認を行うパート(左側)では、最初に目的のWebサイトからデータの取得方法を検討します。データの取得は、XPathやCSSセレクタと呼ばれるHTMLの中から必要な情報を取得するのに利用する簡易言語を使います。
ブラウザGoogle Chromeの開発者ツールを用いて、取得したいデータがあるサイトのHTMLを確認し、XPathやCSSセレクタでデータの取得方法などを検討していきます。
XPathやCSSセレクタの詳しい説明は、以下を参照ください。
>> XPathでスクレイピングする方法
>> CSSセレクタを用いたBeautifulSoupのselectメソッドの使い方
そして必要に応じて、これら検討したXPathやCSSセレクタで、正しくデータ取得できることをshellで確認します。shellでの確認は任意ですので、これを行わず、直接spiderへコーディングを行い、実行してエラーがあれば修正するという方法でも問題ありません。慣れてくると、通常は、shellでの確認は、行わなくなるかと思います。
またこれらのデータの取得方法の検討・確認は、spiderのコーディングまでに終えていれば良いので、これを最初に行わず、プロジェクトやspiderの作成の後や、さらにはspiderのコーディングの最中に行っても問題ありません。
またスクレイピング対象のサイトが構造の異なる複数のページに分かれている場合、1つのページの取得方法を検討・確認してはコーディングを行い、もう1つのページの取得方法を検討・確認してはコーディングを行うと行ったり来たりすることもあります。
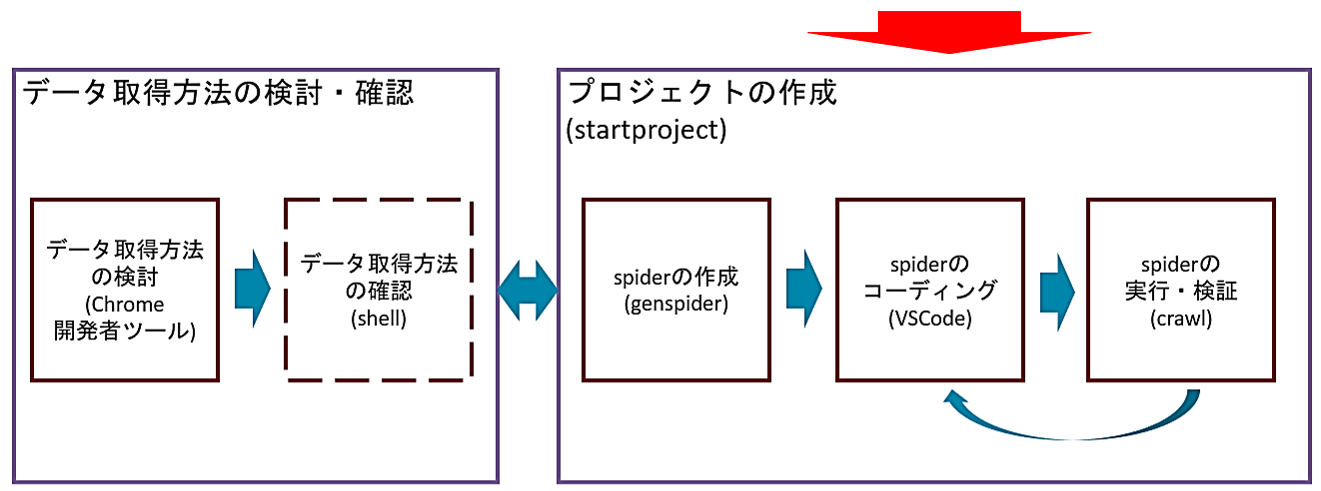
そしてコーディングを行っていくパート(右側)では、最初にターミナルからstartprojectコマンドでプロジェクトを作成し、genspiderでプロジェクト内にspiderを作成していきます。1つのプロジェクト内には、目的に応じて複数のspiderを作成することができます。
次にspiderのコーディングでは、これら確認したXPathやCSSセレクタをspiderに反映していきます。またspiderではXPathやCSSセレクタ以外のコーディングも行います。spiderのコーディングはVS Codeで行います。
そしてコーディングが終わったら、crawlコマンドでspiderを実行して、実行結果を確認し、問題があればコードに戻って修正します。
というのが一連の流れになります。これらの各ステップは、この後で1つずつ確認していきます。
Scrapyの練習用サイト
この記事では、スクレイピング用の練習サイト、Books to Scrapeのサイトから書籍のデータを取得していきます。
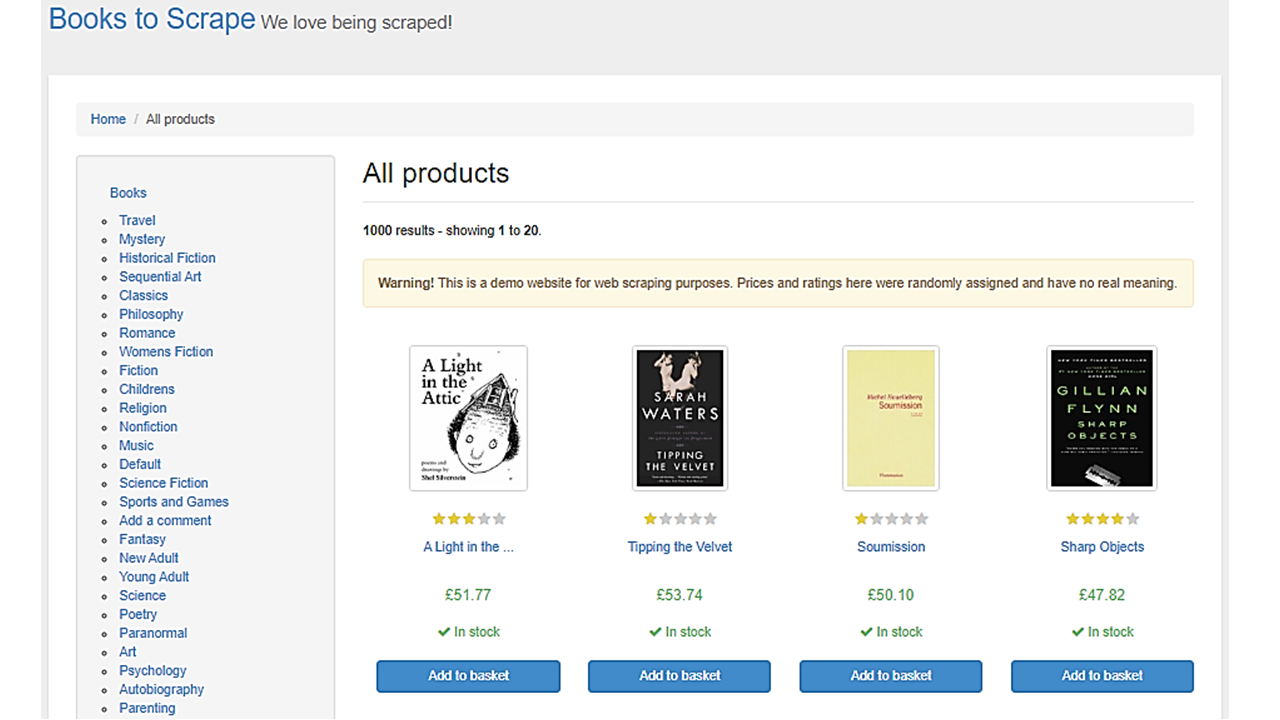
このサイトは、書籍を販売しているサイトのイメージで作成されています。スクレイピング用の練習サイトですので、実際に書籍を販売しているわけではありません。ここには、全部で1000冊の書籍があり、1ページに20冊分ずつの書籍が一覧で表示されています。
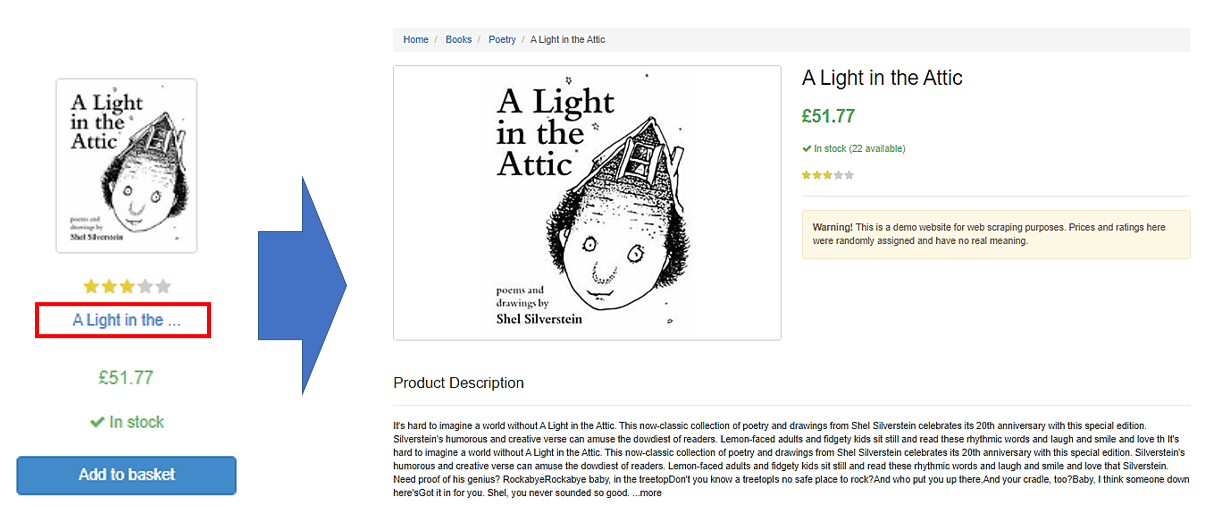
一覧では書籍の簡単な情報が掲載されており、書籍の表紙の画像、星での評価、タイトル、価格、在庫状況、バスケットに追加のボタンが表示されています。
各書籍のタイトルをクリックすると、詳細ページへ遷移します。この詳細ページでは、その書籍に関する、より詳しい情報を確認することができます。
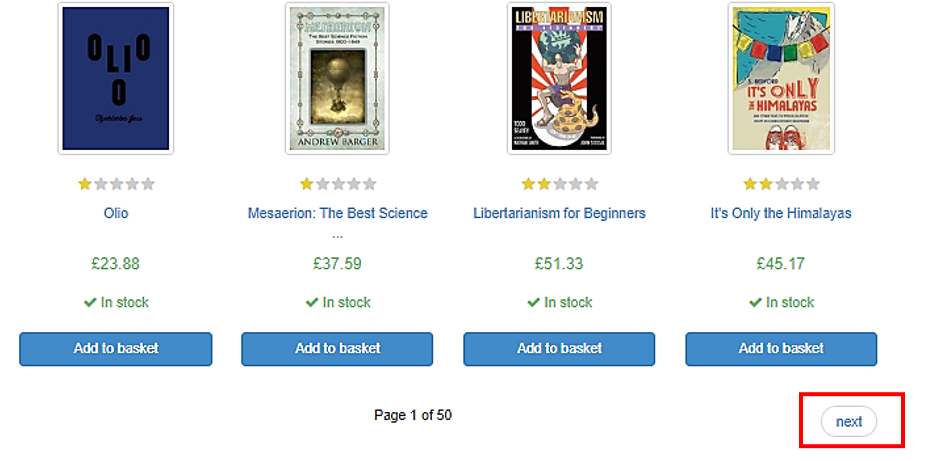
また一覧に戻ってページの下の方へ行くと、次のページへのリンクがあります。このnextをクリックすると、次のページへ遷移することができます。
また各書籍はカテゴリ分けされていて、左側にはカテゴリのメニューが表示されています。
このメニューをクリックすると、一覧に表示される書籍を、カテゴリ毎に絞り込んでいくことができます。
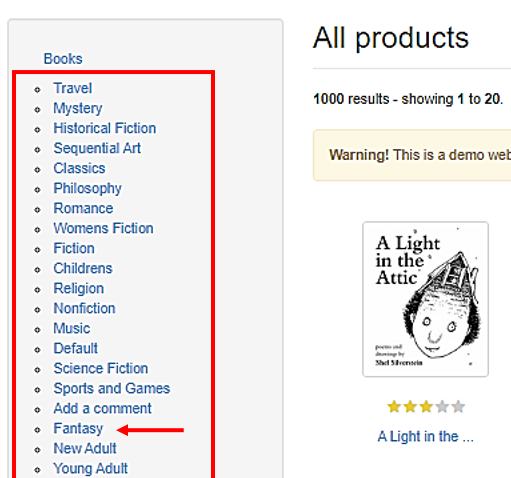
この記事では、全ての書籍から情報を取得していては時間がかかりますので、カテゴリfantasyに属する48冊の書籍に絞って、データを取得していきます。
まずはfantasyのカテゴリの1ページ目に表示されている、書籍のタイトルとURLの一覧を取得していきます。そして、後で2ページ目以降のデータの取得方法を検討していきます。
プロジェクトの作成
Scrapyでプロジェクトの作成には、startprojectコマンドを使います。
ディレクトリの指定は任意で、指定しなくても問題ありません。
指定したディレクトリの下に ここで指定した名前の新しいScrapyプロジェクトを作成します。 ディレクトリ を指定しなかった場合、 ディレクトリ は プロジェクト名 と同じになります。
まずはprojectsというディレクトリを作成します。その中にこれからの様々なプロジェクトを作成していきます。ディレクトリの作成は、mkdirを使います。
ディレクトリprojectsを作成した後、コマンドcdでprojectsに移動します。
そして先ほどのstartprojectコマンドでScrapyのプロジェクトを作成します。ここではプロジェクト名はbooks_toscrapeとします。
startprojectコマンドを実行すると、プロジェクトに必要なディレクトリ、ファイルが自動的に作成されます。
フォルダ・ファイルの説明
ここで、startprojectコマンドで作成されたものを確認してみましょう。使い方、設定方法は後で解説いたします。ここではざっくりと、どのようなものがあるかを説明いたします。
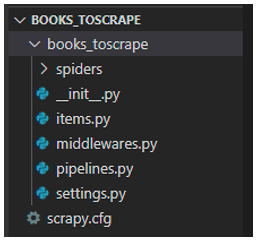
・scrapy.cfgファイル
spiderの作成やデプロイに重要な設定ファイルです。
・spidersフォルダ
このフォルダの中にspiderが作成されます。
・items.pyファイル
スクレイピングで取得したデータを格納する入れ物のようなものです。これはアイテムと呼ばれています。アイテムの各フィールドは、このような形で定義し、予め定義していないとデータを格納できません。この例では、フィールド名nameが定義されています。またspiderではアイテムを使わず、辞書に格納することもできます。
・middlewares.pyファイル
requestとresponseに関連する追加の処理を拡張する為に、ロジックを記述します。2つのmiddlewareがあり、1つはspider middlewareでWebサイトへのrequestやresponseに関連する処理を拡張することができます。もう1つは、download middlewareで、Webサイトからページのダウンロードに関する処理を拡張することができます。
・pipline.pyファイル
Webサイトから取得したデータのクレンジング、チェック、DBへの更新などの処理を記述するのに利用します。
・settings.pyファイル
パラメーターで各種設定を行う設定ファイルです。今後よく使うことになります。
Spiderの作成
それではspiderを作成していきます。先ほど作成したプロジェクトbooks_toscrapeへ移動します。
そしてspiderを作成します。scrapy genspider と入力し、基本的にはスパイダー名、URLを入力します。
URLの内、最初のhttps://と最後の / は削除してください。URLのこれらのものは、scrapyが自動で付加してくれますので、重複を避ける為、ここでは削除します。但し、scrapyはhttp://のプロトコルでテンプレートを自動的に作成しますので、後でhttpsに修正する必要があります。
またspiderはScrapyで予め用意されたテンプレートを元に作成されます。
必要に応じて、-t に続いて、テンプレートを指定します。
利用できるテンプレートは、次のコマンドで確認することができます。

何も指定しなければ、basicのテンプレートになります。ここでは、このbasicのテンプレートを使います。
crawlは、通常のWebサイトをクロールするために使われるテンプレートです。ルールを定義してリンクをたどっていくテンプレートになります。このテンプレートは、別の記事で詳しく解説いたします。
csvfeedはcsvファイルを、xmlfeedはxmlファイルを読み込むテンプレートです。これらはめったに使いません。通常はbasicかcrawlテンプレートを使うことになります。
それでは、genspiderコマンドでspiderを作成します。scrapy genpiderに続いて、spider名を入力します。ここではbooks_basicとします。またURLはサイトから取得して貼り付けます。そして、https://と最後の/を消します。
コマンドを実行すると、spidersフォルダの下にspiderのファイル、books_basic.pyが作成されています。
Spiderのclassの説明(basicテンプレート)
作成したspiderのファイル、books_basic.pyを開きます。
1 2 3 4 5 6 7 8 9 | import scrapy class BooksBasicSpider(scrapy.Spider): name = 'books_basic' allowed_domains = ['books.toscrape.com/catalogue/category/books/fantasy_19/index.html'] start_urls = ['http://books.toscrape.com/catalogue/category/books/fantasy_19/index.html/'] def parse(self, response): pass |
spiderはクラスです。scrapyモジュールにあるspiderクラスを継承しています。つまり、このspiderクラスの多くの機能を引き継いでいます。
この中には、オーバーライド、つまり上書きすべきコードだけを記述していきます。従って、Scrapyではほんの数行のコードでも、多くのことを実現することができます。
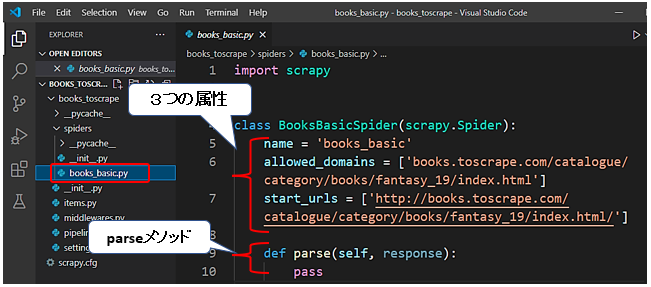
属性としては、これらの3つが定義されています。
- name属性には、先ほどのgenspiderコマンドで入力したspiderの名前が入っています。 それぞれのspiderはユニークな名前を持っています。ここでは、books_basicになります。1つのprojectで複数のspiderを作成できますが、それぞれユニークな名前を付ける必要があります。重複してはダメです。
- allowed_domeinsは、spiderがアクセスできるドメインを示します。リストなので複数指定することも可能です。無くても良いですが、spiderがリンクをたどって思わぬドメインもスクレイピングしないように設定する方がよいです。またドメインなので、http://などのプロトコルは付ける必要が御座いません。
- start_urlsは、spiderがスクレイピングを開始するURLが設定されます。spiderは初期設定では、http://で作成するので、https://とsを付ける必要があります。(※コードにsを追記する。)
またメソッドとしてparseメソッドが記述されています。
Scrapyの処理の流れ
Scrapyの処理の説明に入る前に、まずHTTP通信とリクエストメソッドについて、概要を簡単に説明します。WebブラウザでWebページを開くと、WebブラウザとWebサーバの間でデータの通信が行われます。この通信はHTTPというプロトコルに基づいて行われます。
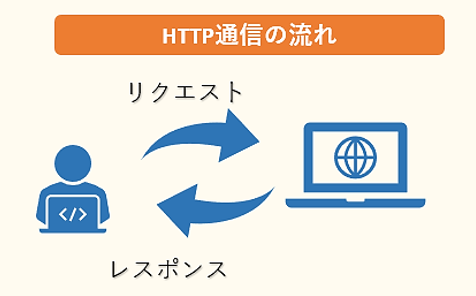
Webブラウザは最初に、開きたいWebページのアドレスをWebサーバに要求、リクエストを送信します。するとWebサーバは、ブラウザからのリクエストを受けて様々な処理を行った後、ブラウザへ回答、レスポンスを返します。Scrapyは、ここでのブラウザの役割の代わりを担い、リクエストの送信やレスポンスの受け取りを行います。
Scrapyの一連の処理では、まずrequestがstart_urls属性に設定されたURLに送られます。そして、Webサイトからのresponseをparseメソッドでキャッチします。このparseメソッドの中にXPathやCSSセレクタを用いて情報の抽出を行っていきます。
Webサイトから返ってくるresponseの中には、WebページのHTMLコードも含まれます。1ページ全てのコードになりますので、非常に多くのコードが含まれており、その中から必要な情報だけを取得する必要があります。
XPathやCSSセレクタは、HTMLの多くのコードの中から必要なものを取得するのに利用する簡易言語です。Scrapyを使ったスクレイピングでは大変重要になってきます。XPathやCSSセレクタの詳しい説明は、以下を参照ください。
>> XPathでスクレイピングする方法
>> CSSセレクタを用いたBeautifulSoupのselectメソッドの使い方
これら以外にも多くのメソッドがあり、scrapyでは必要に応じてオーバーライド、つまり上書きして処理を記述していきます。
最後に注意点として、これらの予めテンプレートに定義された属性とメソッド(name、allowed_domein, parse, etc.)の名前を変更してはいけません。うまく動作しなくなります。
spiderの作成と、最初に生成されるコードの説明は以上です。一旦、変更したものを保存します。保存は、ショートカットキーCtr + Sになります。
Chrome開発者ツールの使い方
次に、実際にspiderのコーディングに取り掛かる前に、ブラウザChromeを用いて、目的のWebサイトからデータをどのようにして取得するか、検討する方法を説明いたします。
Webスクレイピングでは、対象のWebサイトのHTMLソースコードを確認して、取得したい項目が格納されている箇所を特定し、取得方法を確認する必要があります。
これらの確認にChromeの開発者ツールは用いられ、スクレイピングを行う上で非常に重要なツールとなります。
ブラウザGoogle Chromeがインストールされていない方は、以下のリンクよりインストールしてください。
>> Google Chrome公式ページ
開発者ツールの表示方法
ブラウザGoogle Chrome を立ち上げ、Books to Scrapeのサイトに行き、カテゴリからfantasyを選択します。fantasyに属する書籍の一覧が表示されます。
ここで1つの書籍のタイトルにカーソルを当てて、右クリックのメニューから検証を選択します。すると、右側に該当箇所のHTMLコードがハイライトされて表示されます。
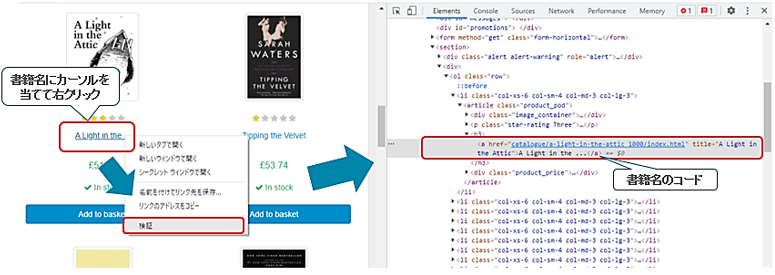
書籍のタイトルやURLは、このh3要素配下のa要素に含まれています。タイトルはtitle属性、もしくは、a要素配下のテキスト、URLはhref属性に格納されています。
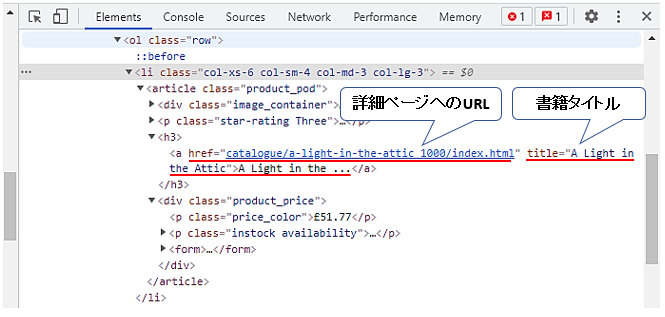
指定方法をXPathやCSSセレクタで確認していきます。Ctr + Fで検索ウィンドウを表示します。ここでは、XPathやCSSセレクタを入力することで、HTMLコードの中で該当する箇所を確認することができます。
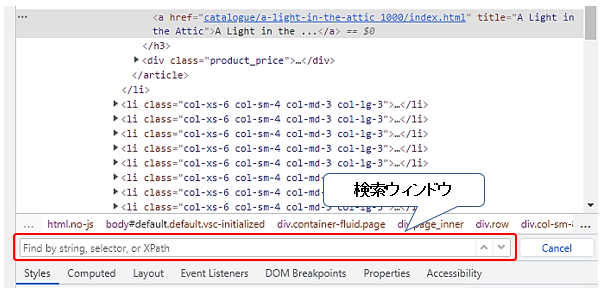
最初にXPathで取得方法を検討し、その後にCSSセレクタでも検討します。
XPathでの取得方法の検討
XPathで途中の階層から要素を指定するには、ダブルスラッシュから始めます。//h3 とh3要素を指定すると、ヒット件数は20件になります。下矢印を押すと、次の書籍のタイトルにハイライトが移動していきます。この20件は、このページの書籍の件数20と一致します。余分なものも含まれていないようです。
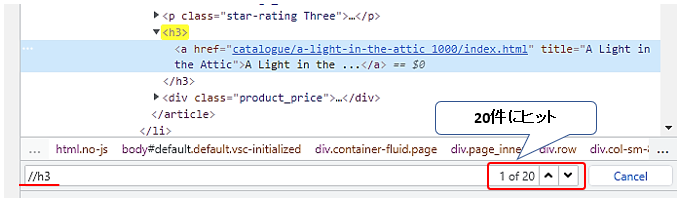
一方でh3要素を省略し、a要素から取得しようとすると、95件がヒットし、この中には書籍の情報が格納されているもの以外の要素も含まれてしまっています。従って、//h3/aとa要素の親要素であるh3要素から取得していきます。

書籍のタイトルは、a要素のtitle属性の値を取得する場合は、
となります。属性の値は、@に続いて属性名で取得することができます。
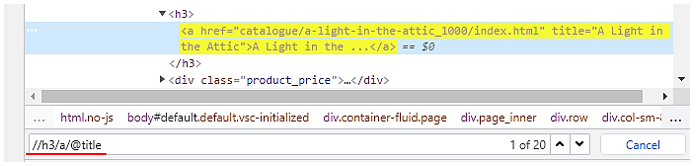
また書籍のタイトルはa要素の配下のテキストにも格納されていますので、
でも取得することができます。
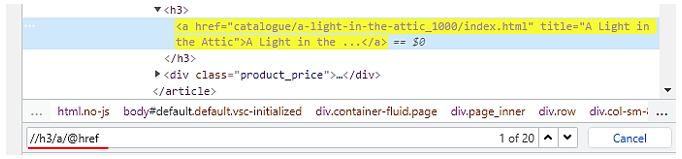
そしてURLは、a要素のhref属性の値に格納されていますので、
で取得することができます。
CSSセレクタでの取得方法の検討
同じ内容をCSSセレクタでも取得してみます。
CSSセレクタで途中の階層から指定する場合は、そのまま要素名を入力するだけで良いので、h3と入力します。そしてその配下のa要素を指定するには、1つスペースを空けてaと入力します。この場合は、h3要素の子孫要素の中からa要素を指定することになります。a要素はh3要素の直接配下にありますので、子要素になります。子要素も子孫要素の一種ですので、このようにスペースで指定することができます。
また子要素と限定して指定する場合は、大なりの記号で指定することができます。大なりの記号の前後にはスペースを挟みます。
いずれの方法でもh3配下のa要素を指定することができます。
そしてタイトルは、擬似要素と呼ばれる特殊な要素の指定方法を利用して取得することができます。コロン2つに続いてtextと記述します。但し、これらの疑似要素は非標準で、開発者ツールでは確認することができず、コーディングの際に追記します。
またtitle属性の値を取得する場合は、こちらも擬似要素を用いてコロン2つに続いてattr(title)と記述します。attr()で属性の値を取得することができ、ここではtitle属性の値を取得しています。
そしてURLは、href属性の値ですので、こちらも擬似要素を用いて、:: attr(href)で取得することができます。
以上で書籍のタイトルとURLの取得方法について、検討が終わりました。次に、これらの情報を取得すべく、コーディングに入っていきます。
Scrapy Shellの使い方
Shellは、Chromeの開発者ツールで確認したXPathやCSSセレクタで、うまく目的の情報を取得できるか確認するのに利用します。
取得方法に特に懸念点が無い場合、このプロセスを飛ばして、次のspiderへのコーディングに進んで頂いても問題御座いません。慣れてくるとspiderに直接まとめてコーディングして、エラーが出た場合は修正する、という方がやり易いかもしれません。
Shellの詳細については、以下を参照ください。
>> Scrapy Shellの使い方
Spiderのコーディングと実行
それでは、いよいよspiderのコーディングに入っていきます。その中で、scrapyの各種設定を行う設定ファイルsettings.pyファイルの編集とspiderのコーディングの方法について、解説いたします。
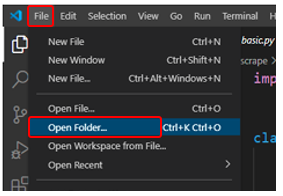
プロジェクトフォルダのオープン
まずはAnaconda Navigatorのメニューから、作成した仮想環境を選択します。この記事では、scrapy_workspaceになります。そして、VS Codeを起動します。
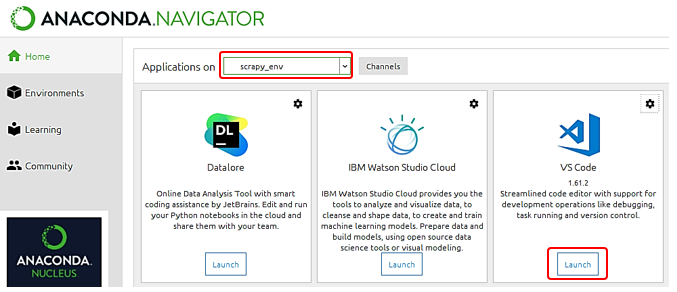
VS Codeでは、fileメニューからopen folderを選択し、サブWからprojectsフォルダ配下のbooks_toscrapeを選択します。
settings.pyの編集
最初にsettings.pyをオープンします。ここでは、パラメーターでscrapyの様々なオプションを指定します。
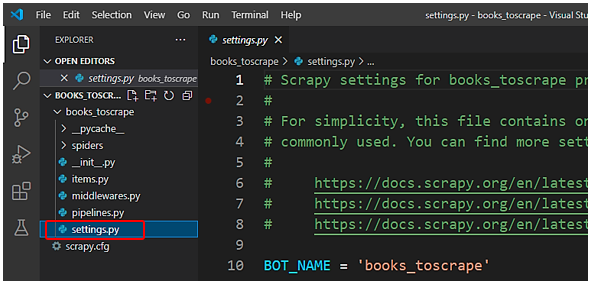
FEED EXPORT ENCODINGでは、出力ファイルの文字コードを指定します。文字コードには様々なものがありますが、標準的なutf-8を指定します。指定をしないと文字化けすることがあります。
1 | FEED_EXPORT_ENCODING = 'utf-8' |
DOWNLOAD DELAYのパラメーターのコメントアウトを外します。コメントアウトの解除はショートカットキー、Ctr + K + U で行うことができます。DOWNLOAD DELAYでは、1つのページをダウンロードしてから、次のページをダウンロードすするまでの間隔(単位:秒)で指定します。
1 | DOWNLOAD_DELAY = 3 |
誤ってサーバーに対して負荷をかけ過ぎないよう、ダウンロード毎の処理の間隔として3秒間隔を開けます。
また次のROBOTSTEXT_OBEYは、robots.txtがある場合は、それに従うかどうかを指定するパラメーターになります。最初からTrueになっておりますので、ここでは不用意にrobots.txtで禁止されているページにアクセスしないよう、このままTrueにしておきます。
1 2 | # Obey robots.txt rules ROBOTSTXT_OBEY = True |
全ての変更が終わりましたので、変更内容を保存します。ショートカットキーCtr + S で保存します。
settings.pyの変更は以上になります。
Spiderのコーディング
それではいよいよ最後のspiderのコーディングに入っていきます。ここではカテゴリFantasyの最初のページから、書籍のタイトル・URLの一覧を取得していきます。
先ほど作成したbooks_basicのspiderをオープンします。
属性の変更
spiderにはこれらの3つの属性が定義されていました。
・name属性には、spiderの名前が入っています。
・allowed_domeinsは、spiderがアクセスできるドメインを示します。
ドメイン名ですので、books.toscrape.com と、手前のドメイン部分だけにする必要があります。
1 | allowed_domains = ['books.toscrape.com'] |
・start_urlは、spiderがスクレイピングを開始するURLが設定されます。spiderは初期設定では、http://で作成するので、https://とsを付ける必要があります。
1 | start_urls = ['https://books.toscrape.com/catalogue/category/books/fantasy_19/index.html'] |
parseメソッドのコーディング
またメソッドとしてparseメソッドが記述されています。Scrapyの一連の処理では、まずrequestがstart_urlsのURLに送られます。そして、Webサイトからのresponseをparseメソッドでキャッチするということでした。この中にGoogle Chromeで確認したXPathやCSSセレクタを用いて情報の抽出を行っていきます。
1 2 3 4 5 6 | def parse(self, response): books = response.xpath('//h3') # books = response.css('h3') yield { 'books': books } |
先ほど確認したXPathを元に、まずはh3要素を取得し、変数booksに格納します。このh3要素の配下の要素には、書籍のタイトルやURLが格納されている要素が含まれています。書籍は20冊ありますので、20個のh3要素が格納されています。
またCSSセレクタの場合は、cssメソッドに変更し、CSSセレクタを渡します。ここではXPathで実行していきますので、このコードはコメントアウトします。CSSセレクタでも実行結果は同じになります。
ここには最後尾に.get()や.getall()が付いていませんので、Selectorオブジェクトがリストに格納されたかたちで情報が取得されます。ここでは取得したいデータとは関係ありませんが、理解しやすいよう、この変数booksの中身を確認してみましょう。戻り値はyieldを使って辞書で記述し、出力します。
またscrapyのparseメソッドでは、yieldを使って値を返します。何か値をxpathで取得した後、その値をyieldを用いて辞書型で返すことで、その結果が画面やファイルに出力されます。
returnでは、そこで処理が完全にストップしてしまいますが、yieldでは処理を一旦停止させるだけですので、値を返した後に処理は継続していきます。
まずはこの変数booksの中身を確認するよう、ここで実行してみます。変更内容を保存するよう、ショートカットキーCtr + Sで保存します。
Spiderの実行方法
spiderの実行はターミナルで行います。
spiderの実行にあたっては、scrapy.cfg(コンフィグ)ファイルと同じレベルのディレクトリにいる必要があります。ここではprojects配下のbooks_toscrapeにディレクトリを移動します。
そして、spiderの実行には、コマンドcrawlを使います。scrapy crawl books_basic と入力し、エンターキーで実行します。
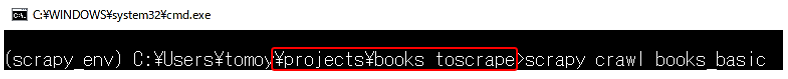
実行すると、このようにSelectorオブジェクトをリストで取得することができました。この変数booksの中には、Selectorオブジェクトのリストが格納されています。
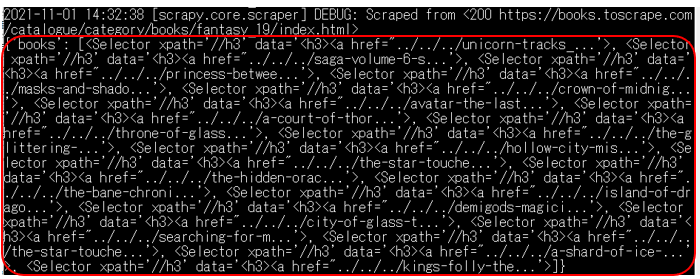
Selectorオブジェクトには、取得した要素の情報が格納されています。これらは、 XPath または CSS セレクタで指定されたHTMLの特定の部分を「選択(select)」するため、セレクター(selector)と呼ばれています。
ここではh3要素から配下の要素の情報が1つのSelectorオブジェクトとして、リストで格納されます。書籍1つが1つのリストの要素として、要素数が20のリストになっています。
dataには、省略して表示されていますが、h3要素とその配下の要素の情報が格納されています。この1つ1つのSelectorオブジェクトの中から、書籍のタイトルやURLを取得していきます。
parseメソッドのコード変更
parseメソッドで、Selectorオブジェクトの中から、書籍のタイトルやURLを取得したコードは次のようになります。
1 2 3 4 5 6 7 8 9 10 11 | def parse(self, response): books = response.xpath('//h3') # books = response.css('h3') for book in books: yield { 'Title': book.xpath('.//a/@title').get(), 'URL': book.xpath('.//a/@href').get() # 'Title': book.css('a::attr(title)').get(), # 'URL': book.css('a::attr(href)').get() } |
Selectorオブジェクトのリストが格納されている変数booksをfor文でループを回しながら1つ1つ取り出していきます。取り出したものは、単数形の変数bookに格納します。つまり変数bookには1つのSelectorオブジェクトが格納されています。
ここからさらに書籍のタイトルやURLを取得し出力していきます。yieldで取得した情報を出力します。
タイトルの取得(XPath)
書籍のタイトルは、キーTitleとして出力します。また書籍のタイトルは、h3要素の配下のa要素のtitle属性に格納されています。
変数bookに格納されているSelectorオブジェクトには、h3要素とその配下の要素の情報が格納されていますので、その配下にある要素の中からa要素を指定していきます。
Selectorオブジェクトに対して、XPathを記述する場合、最初に . (ドット)を付ける必要があります。
前はresponseに対してXPathを記述しましたので必要ありませんでしたが、Selectorオブジェクトに対して、XPathを記述する場合は、ドットが必要になりますので、ご注意ください。
タイトルの取得(CSSセレクタ)
またCSSセレクタで記述する場合は、ドットやその他追加する必要はありません。そのまま先ほど開発者ツールで確認したCSSセレクタを記述してください。::attr(title)は付ける必要があります。
以降はXPathで解説を進めていきますが、CSSセレクタでも同様に、cssメソッドに変更し、Chromeで確認したCSSセレクタを渡してください。
URLの取得
次にa要素のhref属性の値を取得し、出力します。
Spiderの実行とファイル出力
そして、spiderを実行します。ショートカットキーCtr + Sで保存し、ターミナルを開きます。
scrapy crawl books_basic と入力し、今度はJSONファイルに出力します。ファイル出力は、-o に続き、ファイル名を入力します。ここではbook_fantasy.jsonとしておきます。エンターキーで実行します。
出力されたJSONファイルを開けると、
このようにBooks to Scrapeのサイトから取得したfantasyの書籍のタイトルとURLが表示されました。ここでは1ページ目の情報、20冊分だけが表示されています。

Scrapyでのページ遷移(リンクのたどり方)
ここまでで、サイトBooks to Scrapeの最初のページに表示されている書籍のタイトルとURLを取得することができました。ここではさらに、次のページ以降の情報も取得していきます。
ページの下の方へ行くと、次のページへのリンクがあります。このnextをクリックすると、次のページへ遷移することができます。
リンクのURLの取得方法の検討
まずはこの次のページのリンクのURLの取得方法を検討します。
nextにカーソルを当てて右クリックし、メニューから検証を選択します。右側に該当箇所のHTMLコードが表示されます。このa要素のhref属性に格納されているようです。a要素だけで指定すると多くヒットし、このa要素だけに絞り込めませんので、絞り込みに使えそうな要素を探します。ここでは1つ上のclass属性の値にnextを持つli要素が絞り込みに使えそうです。
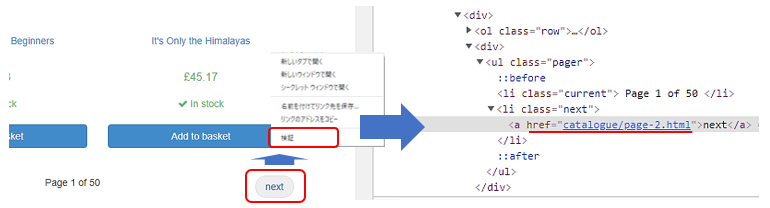
Ctr + Fで検索欄を表示し、まずはXPathで取得方法を確認します。
と入力すると、1件に絞り込むことができました。
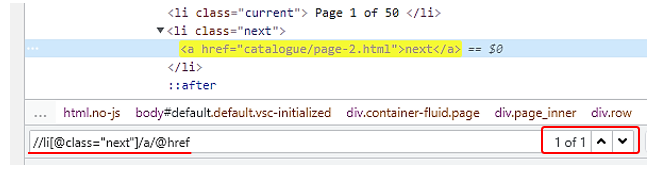
また同じものはCSSセレクタでは、
と記述します。::attr(href)は、非標準の疑似要素になりますので、開発者ツールでは確認することができず、コーディングの際に追記します。
Spiderへの複数ページ遷移のコード追記
先ほど開発者ツールで次ページへのURLの取得方法を確認しましたので、次に、これら確認した次のページへのURLを元に、spiderのコーディングにURLをたどるコードを追記していきます。
parseメソッドに対して、リンクをたどるコードを追記したコードは、次のとおりです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def parse(self, response): books = response.xpath('//h3') # books = response.css('h3') for book in books: yield { 'Title': book.xpath('.//a/@title').get(), 'URL': book.xpath('.//a/@href').get() # 'Title': book.css('a::attr(title)').get(), # 'URL': book.css('a::attr(href)').get() } next_page = response.xpath('//li[@class="next"]/a/@href').get() # next_page = response.css('li.next a::attr(href)').get() if next_page: yield response.follow(url=next_page, callback=self.parse) |
先ほどの書籍の情報を取得するfor文の後に、次のページへのリンクをたどるプログラムを追記しています。
次のページへのリンクは、変数next_pageに格納します。response.xpathに続いて、引数に先ほど確認したXPathを渡します。CSSセレクタの場合は、このxpathメソッドをcssメソッドに変更し、Chromeで確認したCSSセレクタを渡します。
# next_page = response.css('li.next a::attr(href)').get()
そして次へのボタンが存在し、リンクが取得できる場合のみ、次のページへ遷移します。
従って、if文でnext_pageに値が格納されていることを確認します。最後のページでは、次へのボタンが存在しませんので、変数next_pageはNullになり、処理を実行しません。if文で実行する処理には、response.followを記述します。
yield response.follow(url=next_page, callback=self.parse)
引数には、urlとコールバックメソッドを指定します。URLは絶対URL/相対URLの両方に対応しています。response.follow により、リンクで指定されたURLを元にサーバーに対してリクエストを送信し、レスポンスをコールバックメソッドで受け取ることができます。
コールバックメソッドには、このparseメソッドと同じ内容を実行しますので、self.parseを指定します。
つまり、最初のページで書籍の情報、タイトルとURLを取得し、次のページへのリンクをたどって、また次のページで書籍の情報を取得し、そして次のページへ遷移するという一連の処理を、次のページが無くなる最後のページまで繰り返していきます。
それではspiderを実行してみましょう。ショートカットキーCtr + Sで保存し、ターミナルを開きます。
scrapy crawl books_basic と入力し、ファイル出力は、-o に続き、ファイル名を入力します。ここではbook_fantasy.jsonとしておきます。エンターキーで実行します。
出力されたJSONファイルを開けると、このようにBooks to Scrapeのサイトから取得したfantasyの書籍のタイトルとURLが表示されました。ここでは1ページ目の情報だけでなく、2ページ目以降の情報も含めて、カテゴリfantasyに含まれる48冊分全ての情報が表示されています。
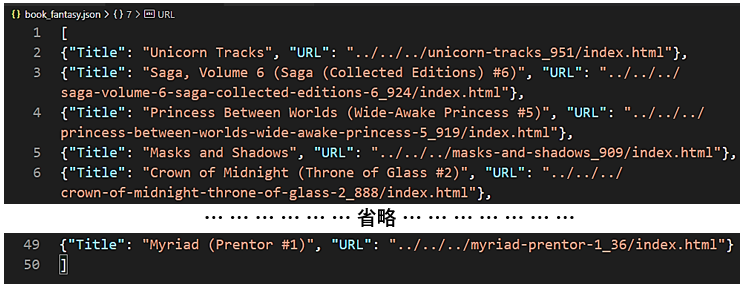
この記事は以上になります。
Scrapyについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「PythonでWebスクレイピング・クローリングを極めよう!(Scrapy、Selenium編)」(Udemyへのリンク)



