この記事では、scrapyで利用できるプログラムの作成や検証、実行などを行う基本的なコマンドを説明いたします。この記事でscrapyの基本的なコマンドを確認し、次の記事からは実際にプログラムの作成に入っていきます。
Scrapyについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「PythonでWebスクレイピング・クローリングを極めよう!(Scrapy、Selenium編)」(Udemyへのリンク)
scrapyで利用できるコマンド
コマンド一覧の表示
ターミナルを起動して、scrapy と入力しエンターを押すと、scrapyに関する情報が表示されます。
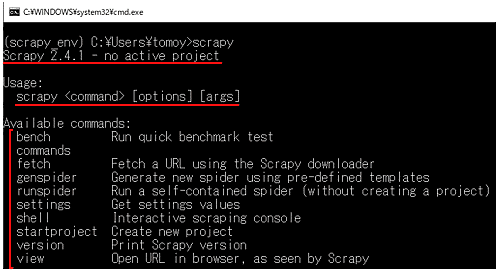
バージョン:私の環境は2.4.1です。利用中のプロジェクトがあれば、アクティブなプロジェクトとしてここに表示されます。
使い方としてコマンドの説明が書かれています。scrapy コマンド と続いてオプション、引数を入力します。
そして、scrapyで利用できるコマンドの一覧が表示されます。主なコマンドを紹介します。
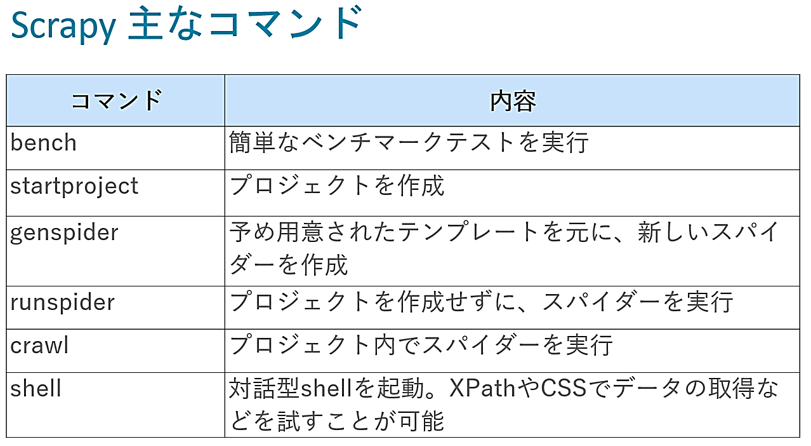
benchコマンド
benchコマンドは、簡単なベンチマークテストを実行するのに利用します。
startprojectコマンド
startprojectは、プロジェクトを作成するのに使います。
scrapyはプロジェクトという単位で1つのまとまりを構成し、その中にspiderというWebサイトから情報をスクレイピングする為のクラスを作成していきます。
1つのプロジェクトの中には、複数のspiderを作ることができます。
genspiderコマンド
genspiderは、新しいスパイダーを作成するのに利用します。spiderは、目的に応じて予め用意された、いくつかのテンプレートを元に作成します。
runspiderコマンド
runspiderは、プロジェクトを作成せずに、スパイダーを実行するのに用いられます。
通常はプロジェクトを作成しますので、めったに利用することはありません。何かを試したいなど、使い捨てのspiderを実行するのに利用します。
crawlコマンド
一方で、作成したプロジェクト内にスパイダーを作成し、そのスパイダーを実行する場合は、crawlコマンドを使います。
従って、通常はプロジェクトを作成しますので、スパイダーの実行には、こちらのcrawlコマンドを使うことになります。
shellコマンド
shellコマンドにより、対話型shellを起動します。shellでは、XPathやCSSセレクタでデータの取得などを試すことができます。これら試したXPathやCSSセレクタをspiderに反映していきます。
XPathやCSSセレクタは、HTMLの多くのコードの中から必要なものを取得するのに利用する簡易言語です。
XPathやCSSセレクタの詳しい説明は、以下を参照ください。
>> XPathでスクレイピングする方法
>> CSSセレクタを用いたBeautifulSoupのselectメソッドの使い方
これらの簡易言語で、データが思い通りに取得できるかを、shellを用いて確認していき、問題無ければspiderに反映します。shellの詳しい説明は「Scrapy Shellの使い方」を参照ください。
開発における基本的なコマンドの流れ
後で実際に実行していきますが、基本的な流れとしては、startprojectコマンドでプロジェクトを作成し、genspiderでプロジェクト内にspiderを作成していきます。
spiderのコーディングでは、必要に応じてshellでデータ取得方法を確認し、それをspiderに反映します。そしてコーディングが終わりましたら、crawlコマンドでspiderを実行する
というのが一連の流れになります。これらのコマンドは、以降の記事でscrapyでコーディングを行う際に確認していきます。
scrapy benchコマンドの使い方
ここでは最後に、scrapyのコーディングの際には出てこないbenchコマンドについて、実際に実行してみます。benchコマンドでは、ベンチマークテストをすることができます。
scrapy benchと入力し、エンターキーを押して実行すると、
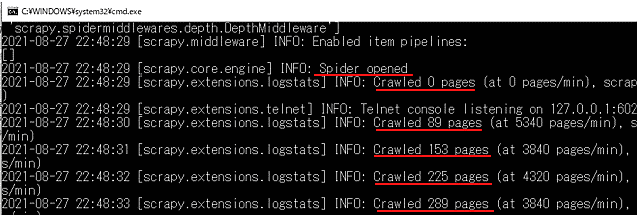
Scrapyが処理を開始し、内部のページに対してクローリングを開始します。
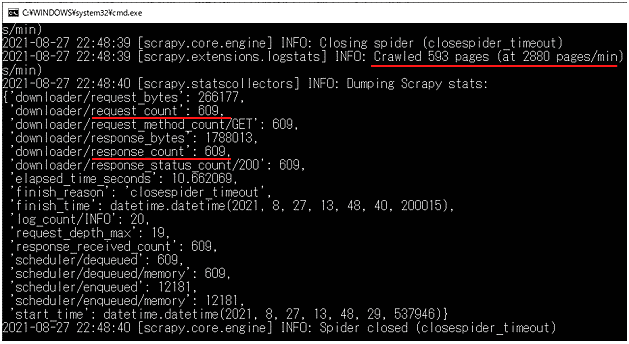
ここでは何ページまでクローリングできたかが表示されています。また横には1分間当たりの送信件数も表示されています。
request_countでは、Requestを送信した件数と、response_countでは、Responseが返ってきた件数がわかります。これらの数値はマシンスペックに依存します。
scrapyで使える基本的なコマンドは以上になります。
次の記事では、これらのコマンドを実際に使い、プログラムの作成に入っていきます。
>> 図解!Python Scrapy入門(使い方・サンプルコード付きチュートリアル)
Scrapyについて、もし動画教材で体系的に学ばれたい方は、以下の割引クーポンをご利用いただければと思います。クリックすると自動的に適用されます。期間限定になりますのでお早めに。
>> 「PythonでWebスクレイピング・クローリングを極めよう!(Scrapy、Selenium編)」(Udemyへのリンク)



