
日々の業務で利用するデータは様々なかたちで保存されています。その中でもCSVやEXCELファイルに保存されているデータを利用することは多いと思います。この章では、これらのデータをDataFrameに読み込んだり、DataFrameで処理した結果をCSVやEXCELに保存する方法を確認していきます。
本章では、以下の方法について、学んでいきましょう。
- CSVファイルからのデータの読み込み
- EXCELファイルからのデータの読み込み
- CSVファイルへのデータの書き込み(出力)
- EXCELファイルへのデータの書き込み(出力)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pandasにおけるread_csvによるCSVファイルの読み込み
CSVからのデータの読み込みは、read_csvにて行います。
引数index_colの指定は任意ですが、指定することにより、インデックスも合わせて設定することができます。指定しなければ、インデックスとして連番が振られます。引数index_colには、インデックスに指定する列名、もしくは、一番左の列を0として順に1ずつ加算した、列の番号を元に指定することもできます。
読み込むCSVファイルは、作業を行っているディレクトリに格納されている必要があります。ディレクトリを指定して読み込むこともできますので、その方法については、後ほど紹介します。
それでは実際の例を確認しましょう。CSVファイル「T_Sales_Header.csv」を読み込み、インデックスに"Sales_No"を指定します。そして、その結果を変数df_salesにDataFrameとして格納します。次に変数df_salesの内容をheadを用いて上位5行を表示します。
...: df_sales=pd.read_csv("T_Sales_Header.csv",index_col=["Sales_No"])...: df_sales.head()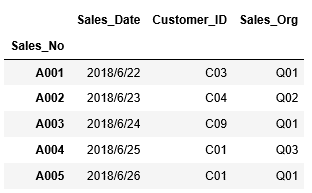
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pandasにおけるread_csvでのディレクトリの指定方法
作業を行っているディレクトリではなく、別のディレクトリからファイルを読み込む場合、ディレクトリの指定方法は、ファイル名の前にディレクトリを記述します。その際に、その前にrを付加します。例えば、ディレクトリ”C:\Test_Folder\Test_Folder2\Test_Folder3”の配下に先ほど利用したCSVファイル”T_Sales_Header.csv”を保存し、このCSVファイルを読み込む場合は、次のように書きます。
...: , index_col=["Sales_No"])...: df_sales.head()
Pandasにおけるread_excelによるEXCELファイルの読み込み
EXCELからのデータの読み込みは、read_excelを利用します。
1つのEXCELファイルには複数のシートが含まれることがありますので、引数shet_nameでは、読み込み対象のシート名を指定します。引数index_colはread_csvと同じです。
EXCELファイル「T_Sales_Item.xlsx」のシート「T_Sales_Item」のデータを読み込み、インデックスに"Sales_No"、”Sales_Item_No”を指定します。ここでは、列名ではなく、列の番号をリストに格納して指定しています。そして、その結果を変数df_sales_itemにDataFrameとして格納し、次に変数df_sales_itemの上位5行を表示します。
...: sheet_name="T_Sales_Item",...: index_col=[0,1])...: df_sales_item.head()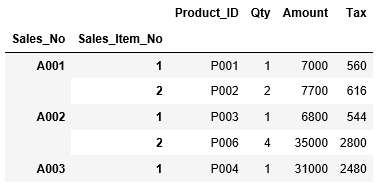
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pandasにおけるto_csvによるCSVファイルへの書き込み(出力)
DataFrameに保持しているデータをCSVファイルへ書き込むには、to_csvを使います。
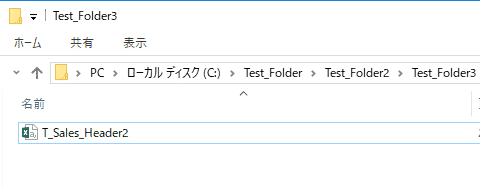
それでは先ほど読み込んだdf_salesの内容を、ファイル名”T_Sales_Header2.csv”で、ディレクトリ”C:\Test_Folder\Test_Folder2\Test_Folder3”の配下にCSVファイルとして出力しましょう。ファイル名の前にディレクトリを記述します。そして、その前にrを付加します。
エクスプローラーでディレクトリ”C:\Test_Folder\Test_Folder2\Test_Folder3”の中を確認すると、CSVファイル”T_Sales_Header2.csv”が出力されていることがわかります。CSVファイルを開くとdf_salesと同じデータが保存されています。
Pandasにおけるto_excelによるEXCELファイルへの書き込み(出力)
DataFrameに保持しているデータをEXCELファイルへ書き込むには、to_excelを使います。
1つのEXCELファイルには複数のシートが含まれることがありますので、引数shet_nameでは、書き込み先のシート名を指定します。
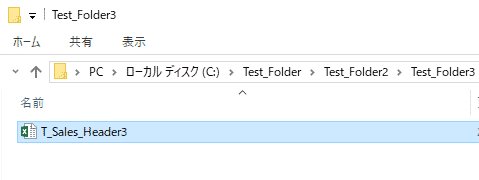
次にdf_salesの内容を、ファイル名”T_Sales_Header3.xlsx”で、ディレクトリ”C:\Test_Folder\Test_Folder2\Test_Folder3”の配下にEXCELファイルとして出力します。出力先のシート名は、”T_Sales_Header3”とします。
...: sheet_name=”T_Sales_Header3”)
エクスプローラーでディレクトリ”C:\Test_Folder\Test_Folder2\Test_Folder3”の中を確認すると、EXCELファイル”T_Sales_Header3.xlsx”が出力されていることがわかります。EXCELファイルを開くとシートT_Sales_Header3には、df_salesと同じデータが保存されています。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













