
Pythonのデータ分析用ライブラリPandasのDataFrame、Seriesに表示されているデータは、様々な方法でソート(並び替え)することができます。
主なソート方法は、
- 指定した列の値によるソート
- インデックスによるソート
また昇順、降順のいずれも指定することができます。
Seriesもソートについては一部制限があるものの、ほぼDataFrameと同じです。よって、ここではDataFrameで例を確認していきます。
例として、あるストアの売上情報(一部)を格納するDataframe df1を元に、様々なソートの方法を見ていきましょう。
1 2 3 4 5 6 7 8 | import pandas as pd sales_list1=[["P001","iPhone 8 64GB",85000, 1], ["P002","iPhone X 256GB",260000, 2], ["P003","iPhone SE 32GB",37000, 1], ["P002","iPhone X 256GB",130000, 1]] columns1 =["Product ID","Product Name","Amount (JPY)", "Qty"] df1=pd.DataFrame(data=sales_list1,columns=columns1) df1 |

本記事の実行結果は、Jupyter Notebook(ジュピター・ノートブック)で確認しております。
従って、最終行の「df1」を実行すると、DataFrameの内容が表示されます。別の環境で実行される場合は、必要に応じて「df1」を「print(df1)」に置き換えてください。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pandas DataFrameにおける指定した列の値によるソート(sort_values)
指定した列の値によるソートは、sort_valuesを用います。引数byで値に基づくソートを行う対象の列を指定します。
引数ascendingにTrueを指定すると昇順、Falseを指定すると降順にソートされます。何も指定しなければ、Trueの昇順になります。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| by | 必須 | ソートする列名を指定する。 |
| ascending | 任意 | byで指定した列のソートの昇順、降順を指定する。 リストで複数の列を指定することも可能。 True: 昇順 False: 降順 ※何も指定しなければ、True(昇順) |
| inplace | 任意 | ソート結果を保存する/しないを指定する。 True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 ※何も指定しなければ、False |
| axis | 任意 | ソートする軸(行 or 列)を指定する。 0: 指定した列の値による行のソート 1: 指定した行の値による列のソート ※何も指定しなければ、0(行のソート) またSeriesは0(行のソート)のみ選択可能 |
| kind | 任意 | ソートのアルゴリズムを指定する。 "quicksort": クイックソート "mergesort": マージソート "heapsort": ヒープソート ※何も指定しなければ、"quicksort" |
| na_position | 任意 | 値がNaN(欠損値)の場合のソート順を指定する。 "first": 値がNaNの場合は最初に表示する。 "last": 値がNaNの場合は最後に表示する。 ※何も指定しなければ、"last" |
引数by: ソートする列名を文字列(単一キー)・リスト(複数キー)で指定
sort_valuesの引数byは、ソートする列名を文字列やリストで指定することができます。
- 1つの列をキーにソートする場合、列名を文字列で指定します。
- 複数の列をキーにソートする場合、複数の列名を格納したリストで指定します。
DataFrame df1の列"Amount (JPY)"の値を元に、昇順にソートします。引数byには列名"Amount (JPY)"を渡します。また"by="は省略することもできます。
1 | df1.sort_values(by="Amount (JPY)") |

df1の列"Amount (JPY)"の値について、上から37000, 85000, 130000, 260000と昇順に並んでいることがわかります。
引数ascendingに何も指定しなければ、昇順になります。
複数の列を指定してソートする場合、引数byにはリストを渡します。
2つの列”Product ID”、"Amount (JPY)"を元にソートしてみましょう。
1 | df1.sort_values(by=["Product ID","Amount (JPY)"]) |

こちらも引数ascendingに何も指定しなければ、2つの列ともに昇順になります。
引数ascending: 昇順・降順の指定
sort_valuesの引数ascendingでは、ソートする際の昇順・降順を指定することができます。
- 1つの列をキーにソートする場合、True(昇順)、False(降順)で指定します。
- 複数の列をキーにソートする場合、列毎にTrue、Falseを格納したリストで指定します。
また何も指定しなければTrue(昇順)になります。
DataFrame df1の列"Amount (JPY)"の値を元に、降順にソートします。この場合、引数ascendingには、Falseを指定します。
1 | df1.sort_values(by="Amount (JPY)", ascending=False) |

df1の列"Amount (JPY)"の値について、今度は上から260000, 130000, 85000, 37000と降順に並びました。
次にDataFrame df1の列"Product ID"の値で昇順に、"Amount (JPY)"の値で降順にソートします。この場合、引数ascendingには、リストを渡します。
1 | df1.sort_values(by=["Product ID","Amount (JPY)"], ascending=[True, False]) |

df1の列"Product ID"の値は昇順に、"Amount (JPY)"の値は降順になりました。
引数inplace: ソート結果の保存有無の指定
sort_valuesの引数inplaceでは、ソートした結果をDataFrameに保存する/しないを指定することができます。
- True:実行結果がDataFrameに保存される。
- False: DataFrameには実行結果が保存されない。
※何も指定しなければ、Falseになります。
例えば、DataFrame df1の列"Amount (JPY)"の値を元に、昇順にソートします。
1 | df1.sort_values(by="Amount (JPY)") |
inplaceには何も指定されず、DataFrameにはソートの実行結果が保存されません。
再度、DataFrameの内容を表示してみましょう。
1 | df1 |
ソートが元に戻っています。
この指定したソートをDataFrameに保存するには、sort_valuesの引数inplaceにTrueを渡します。そしてdf1の内容を表示すると、
1 2 | df1.sort_values(by="Amount (JPY)", inplace=True) df1 |
DataFrameにソート結果が保存されました。
引数kind: ソートのアルゴリズムを指定
sort_valuesの引数kindでは、ソートのアルゴリズムを指定します。
- "quicksort": クイックソート
- "mergesort": マージソート
- "heapsort": ヒープソート
※何も指定しなければ、"quicksort"になります。
基本的には、"quicksort"で問題ありません。
引数na_position: NaN(欠損値)のソート順の指定
値がNaN(欠損値)の場合のソート順を指定します。
- "first": 値がNaNの場合は最初に表示する。
- "last": 値がNaNの場合は最後に表示する。
※何も指定しなければ、"last"になります。
ソートに指定した列がNaN(欠損値)を含む場合があります。
ここでは次のようなDataFrame df2を使います。
1 2 3 4 5 6 7 | sales_list2=[["P001","iPhone 8 64GB",85000, 1], ["P002","iPhone X 256GB",260000, 2], ["P003", "iPhone SE 32GB",37000, ], ["P002","iPhone X 256GB",130000, 1]] columns2 =["Product ID","Product Name","Amount (JPY)", "Qty"] df2=pd.DataFrame(data=sales_list2,columns=columns2) df2 |

列"Qty"にNaNを含んでいます。
列"Qty"でソートしてみます。ソートする際にna_positionに何も指定しないと"last"を指定したことになります。
1 | df2.sort_values(by="Qty") |

NaNの行は最後に表示されます。
今度は、na_positionに"first"を指定します。
1 | df2.sort_values(by="Qty", na_position="first") |

NaNの行は最初に表示されています。
このようにして、引数na_positionでは、NaNを最初に表示するか、最後に表示するかを指定することができます。
上位10位 (Top 10)などの抽出方法
引数の解説に続いて、sort_valuesでの上位10位などのデータの抽出方法を確認していきます。
ここでは次のような15件の売上データを含んだDataFrame df3を使います。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | sales_list3 = [["P001","iPhone 8 64GB",85000, 1], ["P002","iPhone X 256GB",260000, 2], ["P002","iPhone X 256GB",520000, 4], ["P003", "iPhone SE 32GB",111000, 3], ["P001","iPhone 8 64GB",170000, 2], ["P002","iPhone X 256GB",390000, 3], ["P002","iPhone X 256GB",650000, 5], ["P003", "iPhone SE 32GB",185000, 5], ["P001","iPhone 8 64GB",340000, 4], ["P002","iPhone X 256GB",390000, 3], ["P003", "iPhone SE 32GB",74000, 2], ["P001","iPhone 8 64GB",170000, 2], ["P003", "iPhone SE 32GB",74000, 2], ["P003", "iPhone SE 32GB",37000, 1], ["P002","iPhone X 256GB",130000, 1]] columns3 = ["Product ID","Product Name","Amount (JPY)", "Qty"] df3=pd.DataFrame(data=sales_list3, columns=columns3) df3 |
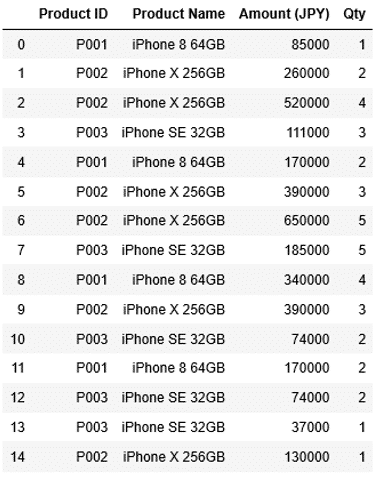
列“Amount (JPY)”に金額のデータがあり、これを元に上位10のデータを抽出してみましょう。
最初のn件のデータを取得する場合、以下のheadを使います。
nには件数を指定します。何も指定しなければ5になります。
先ほどのdf3をsort_valuesで列”Amount (JPY)”の降順、つまり金額の高い順に並べ替えて、headで最初の10件を取得します。
1 | df3.sort_values(by="Amount (JPY)", ascending=False).head(10) |
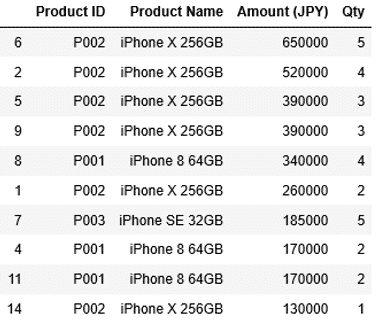
このようにして上位10位のデータを抽出することができました。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
Pandas DataFrameにおけるインデックスによるソート(sort_index)
インデックスによるソートは、sort_indexを利用します。
引数ascendingにTrueを指定すると昇順、Falseを指定すると降順にソートされます。何も指定しなければ、Trueの昇順になります。
主な引数は、
| 引数 | 必須/任意 | 説明 |
| ascending | 任意 | byで指定した列のソートの昇順、降順を指定する。 リストで複数の列を指定することも可能。 True: 昇順 False: 降順 ※何も指定しなければ、True(昇順) |
| inplace | 任意 | ソート結果を保存する/しないを指定する。 True:実行結果がDataFrameに保存される。 False: DataFrameには実行結果が保存されない。 ※何も指定しなければ、False |
| kind | 任意 | ソートのアルゴリズムを指定する。 "quicksort": クイックソート "mergesort": マージソート "heapsort": ヒープソート ※何も指定しなければ、"quicksort" |
| level | 任意 | 階層型インデックスにおける複数のインデックスのソート順を指定する。 インデックスの番号、もしくはインデックスの列名で指定 ※何も指定しなければ、インデックスの順番 |
| axis | 任意 | ソートする軸(行 or 列)を指定する。 0: 指定した列の値による行のソート 1: 指定した行の値による列のソート ※何も指定しなければ、0(行のソート) またSeriesは0(行のソート)のみ選択可能 |
sort_valuesに使った例を元にして、今度はset_indexで列"Product ID"にインデックスを設定します。set_indexの詳しい説明は「Pandas DataFrameへのインデックスの指定」を参照ください。
1 2 3 4 5 6 7 8 9 | import pandas as pd sales_list1=[["P001","iPhone 8 64GB",85000, 1], ["P002","iPhone X 256GB",260000, 2], ["P003","iPhone SE 32GB",37000, 1], ["P002","iPhone X 256GB",130000, 1]] columns1 =["Product ID","Product Name","Amount (JPY)", "Qty"] df1=pd.DataFrame(data=sales_list1,columns=columns1) df1.set_index("Product ID", inplace=True) df1 |
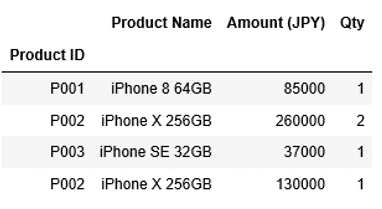
列"Product ID"にインデックスが設定されています。
引数ascending: 昇順・降順の指定
sort_indexの引数ascendingでは、ソートする際の昇順・降順を指定することができます。
True(昇順)、False(降順)で指定し、何も指定しなければTrue(昇順)になります。
sort_indexを実行します。引数に何も渡さなければ、ascending=True(昇順)になります。
1 | df1.sort_index() |
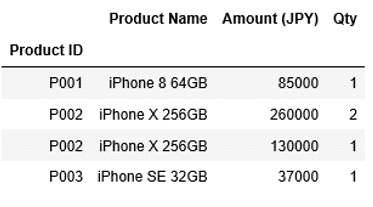
インデックス"Product ID"の昇順に並び替えられました。
今度は、ascendingにFalse(降順)を指定します。
1 | df1.sort_index(ascending=False) |
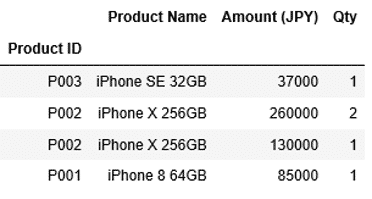
インデックス"Product ID"について、上から"P003"、"P002"、"P001"というように降順でソートされていることがわかります。
引数axis: インデックス、列名(カラム名)でのソートの指定
sort_indexの引数axisでは、ソートする軸(インデックス or 列)を指定します。
- 0: インデックスによるソート
- 1: 列名によるソート
※何も指定しなければ、0になります。
今までの例はすべて何も指定しなかったので、インデックスでソートしていました。滅多に使うことは無いかも知れませんが、参考までにaxisに1を指定して、列名(カラム名)でのソートの例も見ていきましょう。
df1を列名で降順にソートします。
1 2 | df1.sort_index(axis=1, ascending=False) df1 |

列名について、左から”Qty”、”Product Name”、”Amount (JPY)”というように降順でソートされていることがわかります。
引数level: 階層型インデックスでの複数インデックスのソート順の指定
階層型インデックスにおける複数のインデックスのソート順を指定します。インデックスの番号、もしくはインデックスの列名で指定します。
※何も指定しなければ、インデックスの順番になります。
今までのインデックスのソートの例では、1つしかインデックスがありませんでした。しかし、PandasのDataFrameには複数のインデックスをもつ、階層型インデックスがあります。
ここでは階層型インデックスにおけるソートの指定方法を確認していきます。階層型インデックスの詳しい説明は「Pandas DataFrameの抽出(階層型インデックス(MultiIndex))」を参照ください。
例として、次のような売上伝票の情報を取り上げます。列"Sales_No", "Sales_Item_No"にインデックスを設定します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | sales_list2 = [['A001', 1, 'P001', 1, 7000, 560], ['A001', 2, 'P002', 2, 7700, 616], ['A002', 1, 'P003', 1, 6800, 544], ['A002', 2, 'P006', 4, 35000, 2800], ['A003', 1, 'P005', 3, 30000, 2400], ['A004', 1, 'P002', 5, 7700, 616], ['A004', 2, 'P003', 1, 6800, 544], ['A004', 3, 'P008', 1, 42000, 3360], ['A004', 4, 'P005', 2, 30000, 2400], ['A004', 5, 'P010', 1, 12000, 960]] columns2 = ["Sales_No","Sales_Item_No","Product ID","Qty","Amount (JPY)", "Tax"] df_sales_item = pd.DataFrame(data=sales_list2, columns=columns2) df_sales_item.set_index(["Sales_No", "Sales_Item_No"], inplace=True) df_sales_item |
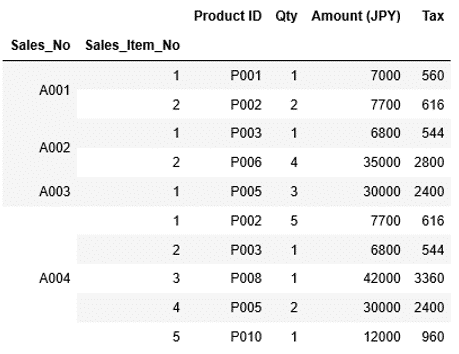
列"Sales_No", "Sales_Item_No"にインデックスが設定され、このインデックスの順番でデータは並んでいます。
これを列"Sales_Item_No"の昇順に並び替えてみましょう。sort_indexの引数levelに"Sales_Item_No"を渡します。
1 | df_sales_item.sort_index(level="Sales_Item_No") |
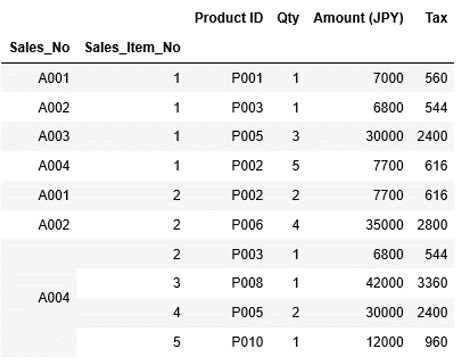
列"Sales_item_No"の昇順でソートされました。
このようにしてsort_indexの引数levelでは、複数のインデックスからソートするレベルのインデックスを選択することができます。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













