
前章に引き続きDataFrameに格納されたデータを取得する方法を確認します。この章では、複数のインデックスが設定されたDataFrameに対しての検索方法を確認します。これらのインデックスは階層型インデックス(MultiIndex)と呼ばれています。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
CSVファイルの読み込み
前回と同様、まず初めにCSVファイルを読み込みます。今回利用するのは、売上の明細情報「T_Sales_Item.csv」で、商品、数量、単価、金額などの情報が格納されています。
この明細情報には、Sales_Noとして、売上伝票毎にAから始まる番号の連番が、Sales_Item_Noには、売上伝票毎の明細の番号として1から始まる番号の連番が、Product_IDには商品IDが、Qtyには売上数量が、Amountには売上金額が、Taxには税額が設定されています。商品IDは、別途マスタデータがあり、IDと共に名称などの情報を持っています。
| Sales_No | Sales_Item_No | Product_ID | Qty | Amount | Tax |
| A001 | 1 | P001 | 1 | 7000 | 560 |
| A001 | 2 | P002 | 2 | 7700 | 616 |
| A002 | 1 | P003 | 1 | 6800 | 544 |
| A002 | 2 | P006 | 4 | 35000 | 2800 |
| A003 | 1 | P004 | 1 | 31000 | 2480 |
| A003 | 2 | P005 | 3 | 30000 | 2400 |
| A004 | 1 | P002 | 5 | 7700 | 616 |
| A004 | 2 | P003 | 1 | 6800 | 544 |
| A004 | 3 | P008 | 1 | 42000 | 3360 |
| A004 | 4 | P005 | 2 | 30000 | 2400 |
最初にCSVファイル「T_Sales_Item」からデータを読み込みます。(※CSVファイルは左のリンクから取得してください。)その際にインデックスも指定します。
CSVファイルの読み込みは、前の章と同様にpd.read_csvを利用します。引数は、読み込むファイル名「T_Sales_Item.csv」と、インデックスに列「Sales_No」「Sales_Item_No」を指定します。この読み込んだデータをDataFrameとして変数df_sales_itemに格納します。
...: df_sales_item = pd.read_csv("T_Sales_Item.csv",...: index_col=["Sales_No","Sales_Item_No"])
そして次にDataFrameを格納した変数df_sales_itemを入力し、格納されているデータを確認します。headを利用し、最初の10行だけを表示してみましょう。
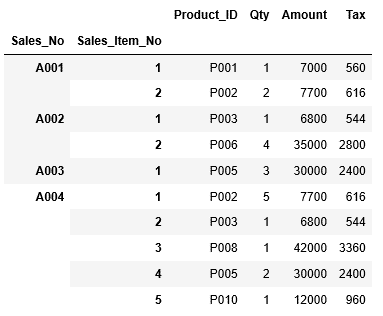
画面上部に表示されているのが列名で、インデックスに指定された列「Sales_No」 「Sales_Item_No」は一段下がって表示されています。
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
階層型インデックス(MultiIndex)から指定行・指定列の抽出
階層型インデックス(multiindex)を持つDataFrameからのデータ抽出は、行番号、インデックスや列名を指定して行なうことができます。但し、複数の行と列を同時に指定してデータの抽出ができないなどの制限がありますので、後述するloc、ilocを利用することも多いです。
まずは列名を指定して、列”Product_ID”の情報を表示してみましょう。

次に1つ目のインデックス”Sales_No”の範囲を指定し、A002~A004行までの全ての列の情報を抽出します。これは前の章の単一インデックスと全く同じ方法で指定できます。
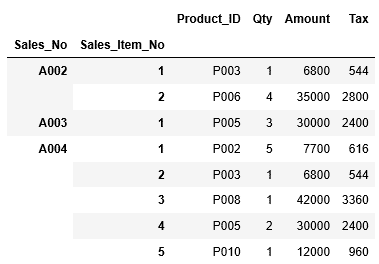
今度は2つ目のインデックスまで合わせて範囲を指定する場合、タプルを利用します。例えば、Sales_NOがA002、Sales_Item_Noが2の行から、Sales_NOがA004、Sales_Item_Noが3の行までを範囲指定する場合、次のように記述します。
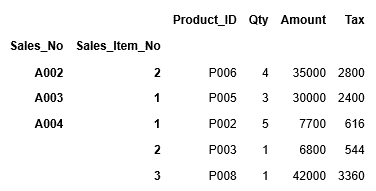
また行番号を指定して特定の範囲の行を抽出することもできます。3行目のSales_NOがA002、Sales_Item_Noが1の行から、6行目のSales_NOがA004、Sales_Item_Noが1の行までを指定してみます。行番号は、1行目は0から始まります。また範囲の終了値に指定された値は含まれません。
従って3行目から6行目までを指定する場合、[2:6]となります。つまり、1行目は0から始まりますので3行目は2となり、範囲の終了値に指定された値は含まれませんので、6行目までを指定したい場合、7行目の6を指定する必要があります。
階層型インデックス(MultiIndex)からlocによる行・列名を指定しての抽出
単一インデックスの時と同様、階層型インデックス(MultiIndex)でも、locを利用してDataFrameからインデックス、列名を指定してデータを抽出することができます。またスライシングも使うことができます。
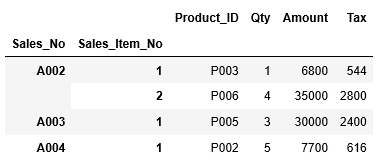
まずはインデックスを指定してデータの抽出をしてみましょう。A001~A003行のデータを抽出する場合、次のようにlocに引数"A001":"A003"を渡します。
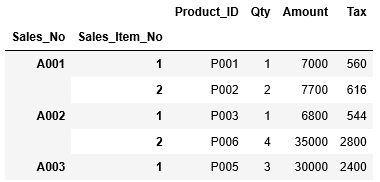
2つ目のインデックスまで合わせて範囲を指定するにはタプルを利用します。次の例では、Sales_NOがA002、Sales_Item_Noが2の行から、Sales_NOがA004、Sales_Item_Noが4の行までを範囲指定しています。
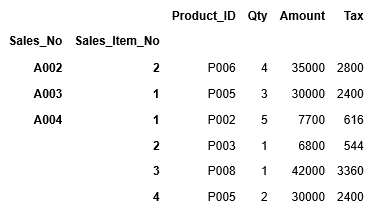
次に列を指定してデータを抽出します。列”Product_ID”~”Amount”までの列を指定して、全ての行の値を取得する場合、行の指定を”:”(全行)、列の指定を”Product_ID”:”Amount”とします。ここではheadを利用して、最初の5行だけを表示します。

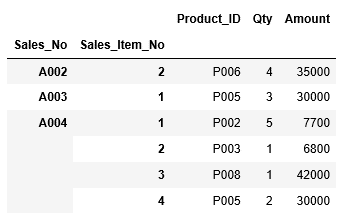
今度は前の2つの例を組み合わせて、行はSales_NOがA002、Sales_Item_Noが2の行から、Sales_NOがA004、Sales_Item_Noが4の行までを範囲指定し、列は”Product_ID”~”Amount”までの範囲を指定して出力してみましょう。
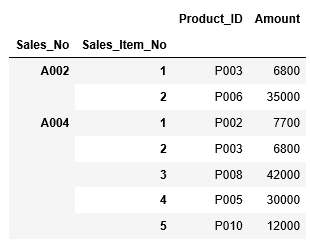
範囲指定だけではなく、行と列ともに個別に抽出する項目を指定することもできます。行はA002とA004行目を抽出し、列は”Product_ID”、 "Amount"のデータを抽出します。特定の列を指定したい場合は、[“Product_ID”,”Amount”]というように、[ ]括弧の中に指定したい列をカンマを挟んで記述します。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













