
この記事は、Python3におけるPandasを用いたDataFrameへのインデックスの指定・削除・変更方法を初心者向けに解説した記事です。インデックスについては、これだけを読んでおけば良いよう、徹底的に解説しています。
DataFrameでは、特定の列をインデックスに指定することができます。各行の情報をユニークに指定できる列をインデックスに指定することで、インデックスを指定して情報を取り出しやすくすることができます。
また次の記事「Pandas – DataFrameの参照(単一インデックス)」で説明しますが、設定したインデックスを元に、「リストのスライシング」でも学んだスライシングを用いて検索することができます。
インデックスは一度設定すると変更できませんので、変更が発生しない列に設定すべきです。(但し、設定したインデックスを外して、再度設定し直すことは可能です。)
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
PandasにおけるDataFrameへのインデックスの指定
インデックスの指定には、set_indexを使います。
inplaceにTrueを渡すとインデックス設定の実行結果がDataFrameに保存され、何も指定しなければFalseとなり、DataFrameには実行結果が保存されません。
次のような商品マスタの情報を格納するDataframe df1に対して、インデックスを設定してみましょう。
...: list1 = [["P001","iPhone 8 64GB",85000],...: ["P002","iPhone X 256GB",130000],...: ["P003","iPhone SE 32GB",37000]]...: columns1 = ["Product ID","Product Name","Price (JPY)"]
...: df1 = pd.DataFrame(data=list1,columns=columns1)
...: df1
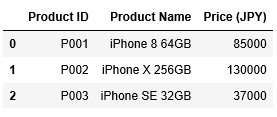
ここでは、df1に対してインデックスは0、1、2と連番になっています。
このような連番では、後々インデックスを指定して行の情報を取得したい場合、思い出すことができず、都度都度インデックスを調べるか、インデックスを使わずに、別の方法で検索することになり、不便です。
この商品マスタの行をユニークに識別する列は”Product ID”になりますので、”Product ID”をインデックスに設定しましょう。引数inplaceにはTrueを指定して、設定したインデックスをDataFrameに保存します。(Falseを指定して保存しなければ、次にdf1を確認すると、インデックスが連番に戻っています。)
...: df1
発売数10,000万本突破を記念して、今だけ期間限定で87%オフの大セール中!
PandasにおけるDataFrameへの階層型インデックスの指定
またインデックスは1つの列だけでなく、複数の列に対して指定することもできます。これを階層型インデックスと言います。
次のような受注伝票の明細データの場合、”Sales_No”、” Sales_Item_No”の2つの列が、行を特定する列になりますので、インデックスとしてこれら2つの列を設定することになります。
受注伝票明細
| Sales_No | Sales_Item_No | Product_ID | Qty | Amount | Tax |
| A001 | 1 | P001 | 1 | 7000 | 560 |
| A001 | 2 | P002 | 2 | 7700 | 616 |
| A002 | 1 | P003 | 1 | 6800 | 544 |
| A002 | 2 | P006 | 4 | 35000 | 2800 |
| A003 | 1 | P005 | 3 | 30000 | 2400 |
| A004 | 1 | P002 | 5 | 7700 | 616 |
| A004 | 2 | P003 | 1 | 6800 | 544 |
| A004 | 3 | P008 | 1 | 42000 | 3360 |
| A004 | 4 | P005 | 2 | 30000 | 2400 |
| A004 | 5 | P010 | 1 | 12000 | 960 |
それではまず、上記の受注伝票明細の情報が保存されているCSVファイル「T_Sales_Item」をread_csvで読み込み(※CSVファイルは上のリンクから取得してください。)、DataFrame df_sales_itemに格納します。
次にdf_sales_itemの中から、headを利用して最初の6行を確認します。read_csv、headともに、詳しくは後の章で解説します。
...: df_sales_item.head(6)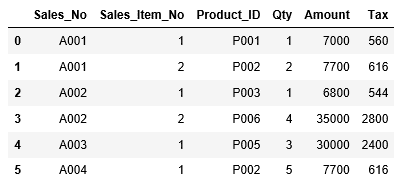
df_sales_itemでは、インデックスは連番になっています。
それでは、インデックスを変更して、2つの列"Sales_No","Sales_Item_No"をインデックスに設定しましょう。set_indexに対して、2つの列をリストで渡します。
...: df_sales_item.head(6)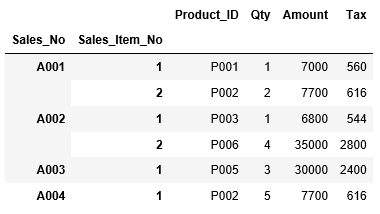
実行結果を確認すると、"Sales_No","Sales_Item_No"の列名が、他の項目名より一段下に表示され、インデックスとして設定されていることがわかります。
PandasにおけるDataFrameへのインデックスの解除・変更(振り直し)
インデックスの解除はreset_indexを使用します。インデックスの解除により、インデックスは連番に戻ります。inplaceは指定しなければFalseになり、インデックスの解除がDataFrameに保存されません。
reset_indexは、インデックスを変更(振り直し)したい場合にも利用されます。一度設定したインデックスは直接変更できません。set_indexで設定したインデックスが間違っていた場合、reset_indexで一度解除してから、再びset_indexで正しいインデックスに設定し直します。
先ほどインデックスに"Sales_No","Sales_Item_No"を指定したDataFrame df_sales_itemのインデックスを解除します。
...: df_sales_item.head(6)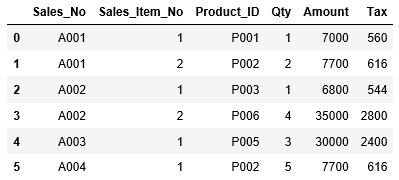
インデックスが解除され、連番に戻っていることがわかりました。
関連記事です。
Pandasの中心となるDataFrame(データフレーム)については、次の記事で詳しく解説しております。













